

Storage devices are the backbone of any storage system, as they are responsible for keeping the data in a persistent state. But these storage devices can have unique characteristics that may impact their behavior and longevity. So, it makes sense to not only gather as much information about these devices as possible, but turn this into intelligence that can help you or the system identify, alert and remediate any impending issues.
This is exactly what we have done with VMware vSAN 8 U3, as a part of VMware Cloud Foundation 5.2. Let’s look at these improvements, which apply to vSAN powered clusters configured as an aggregated vSAN HCI cluster, or a disaggregated vSAN Max configuration.
Proactive Hardware Management for Storage Devices
Device telemetry is a necessity in a highly intelligent storage system. But gathering this data from storage devices and turning it into usable intelligence is not easy. What you measure, how you measure it, and where you measure are all factors in determining what may be failing, and the appropriate action to take. The system must be built in a correct way so that data collected from one device vendor means the same thing as another vendor.
vSAN 8 U3 introduces a new framework that provides a uniform, vendor neutral way of taking this data which can serve as leading indicators of impending failure, to then predict and present its results in the form of health findings in Skyline Health so that appropriate action can be taken. This telemetry data is collected from the storage devices, processed, and normalized so that different OEM devices report the telemetry data in the same way, by the same definitions. This device telemetry can be consumed by the Skyline Health service and can be used to trigger health findings that will give prescriptive guidance on ways to remedy the condition.
What is so unique about this new capability is that it uses a framework already in place. The vSphere Lifecycle Management (vLCM) in vSphere 8 U3 now allows server vendors to adapt their Hardware Support Manager (HSM) component so that telemetry data from storage devices can be easily ingested. The information is sent to the vSAN Health service through a vendor neutral API for further rendering in the form of specific device health findings, and cluster-wide health scores. This can easily serve as the supporting information needed for customers who perhaps are experiencing a bad batch of storage devices and need qualitative and quantitative evidence for replacements under warranty.
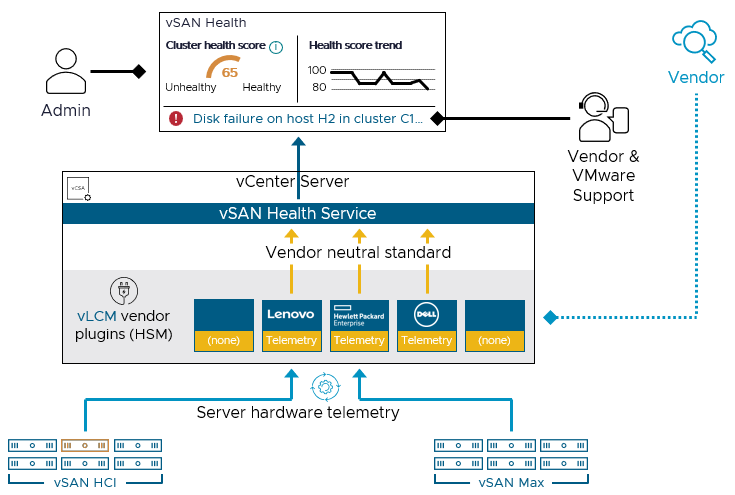
Figure 1. Proactive hardware management for storage devices.
Proactive hardware management is supported in both vSAN ESA and OSA. As of vSAN 8 U3, Dell, HPE, and Lenovo have already adapted their HSM used for vLCM, with more partners to join the HSM program. The VMware Compatibility Guide (VCG) for vSAN will also report which vendors currently support this capability. To take advantage of this feature, simply ensure you are running vSAN 8 U3, and the latest HSM from one of the vendors.
Customizable Alarm Thresholds for Storage Devices
The post “Health and Performance Monitoring Enhancements in vSAN 8 U2,” describes how ESA powered environments can track and report statistics on device wear for NVMe storage devices. Using standard alarm definitions in vCenter Server, this gave administrators an easy way to be alerted on storage devices that were near or at their expected number of device writes.
vSAN 8 U3 makes this storage device endurance alerting capability even better. Custom device endurance alerting can be configured by using new parameters to tailor the alerts to an environment. These parameters allow an alert to be applied to a specific cluster, a specific set of hosts, disk vendors, or even the storage device model.
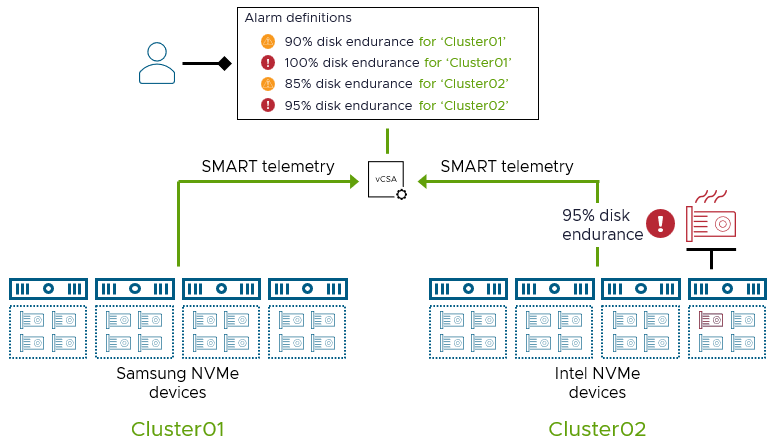
Figure 2. Customizable device endurance alarms in vSAN 8 U3
How could this be applied in the real world? Imagine you have several ESA clusters running higher endurance “Mixed-Use” storage devices but have introduced a few new vSAN clusters running the more value-based “Read-Intensive” storage devices. A new argument can be added to the definition that allows for hosts in one cluster using lower endurance storage devices to generate an alert at a lower threshold than hosts residing in another cluster.
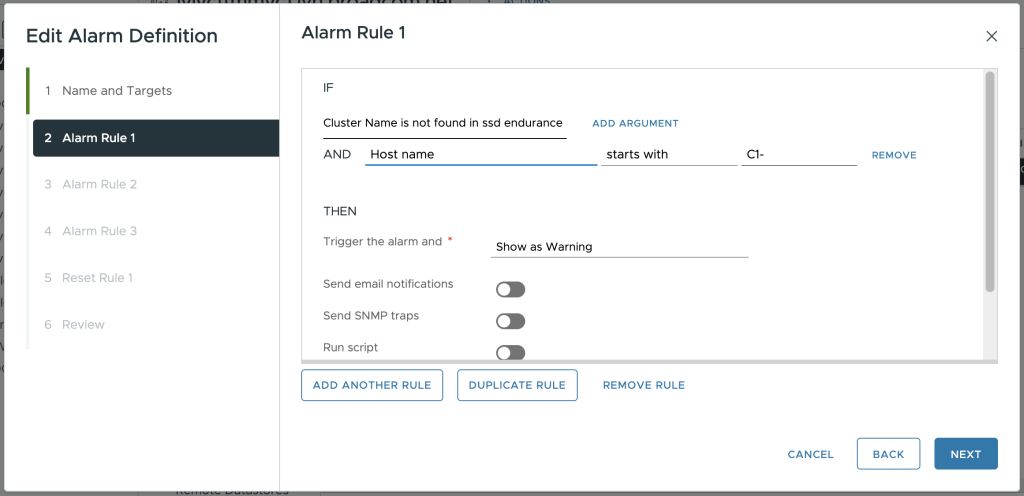
Figure 3. Configuring endurance alarm conditions based on host name.
Note that this endurance tracking of NVMe devices in vSAN ESA is independent of the proactive hardware management for storage devices framework described earlier in this post. This endurance tracking uses S.M.A.R.T data from the NVMe storage devices to trigger alerts defined in vCenter Server. The ability to trigger alarms based on storage device endurance is only supported in clusters running vSAN ESA. vSAN OSA clusters do not have this capability.
This enhancement uses a new vCenter alarm titled: “vSAN Health Alarm for disk endurance check.” It can be found by highlighting the managing vCenter Server, and clicking on Configure > Alarm Definitions. This single alarm definition takes the place of the “Disk endurance exceeded” and “90% Disk endurance used” alarm definitions, which are deprecated in vSAN 8 U3.
Summary
The value of a storage solution that provides meaningful and actionable intelligence about storage devices is almost self-evident. vSAN 8 U3, as a part of VMware Cloud Foundation 5.2, can track the state of discrete storage devices with an unprecedented level of detail and consistency.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




