

Part 3 / 3
In Part 1 of this 3-part technical blog, we discussed how to prepare Cloud Foundation as an AI / ML platform using NVIDIA A30 and A100 GPU devices.
These steps included:
- Preparing the Hosts
- Configuring a vSphere Lifecyle Manager (vLCM) Image
- Adding a VI Workload Domain.
Part 2 covered the processes to configure the VI Workload Domain for Kubernetes Workload Management.
These steps included:
- Adding an NSX Edge cluster
- Creating a Content Library
- Deploying Kubernetes Workload Management
- Creating a vSphere Namespace.
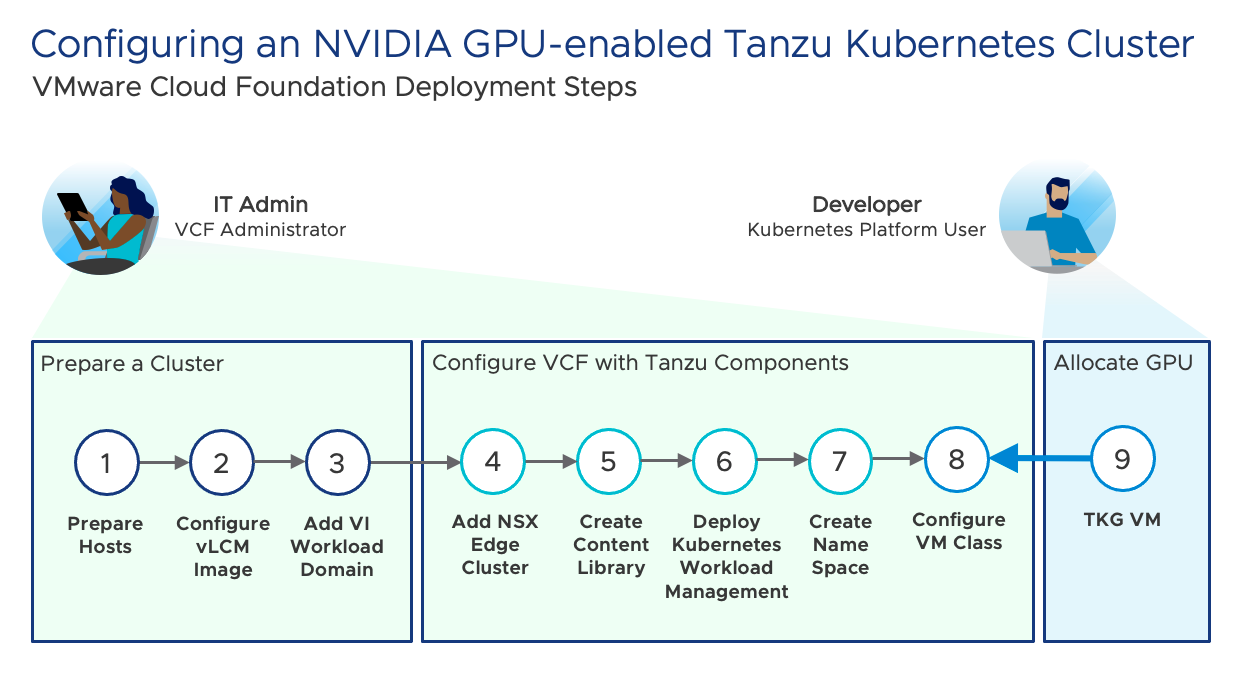
The final step required by the VCF Administrator to configure AI-ML ready infrastructure within VMware Cloud Foundation is to determine how TKC VMs will consume NVIDIA GPU resources.
Before exploring Step 8, it is important to first understand the different ways in which supported NVIDIA GPU resources can be allocated by the VCF Administrator and consumed by Kubernetes Platform Users.
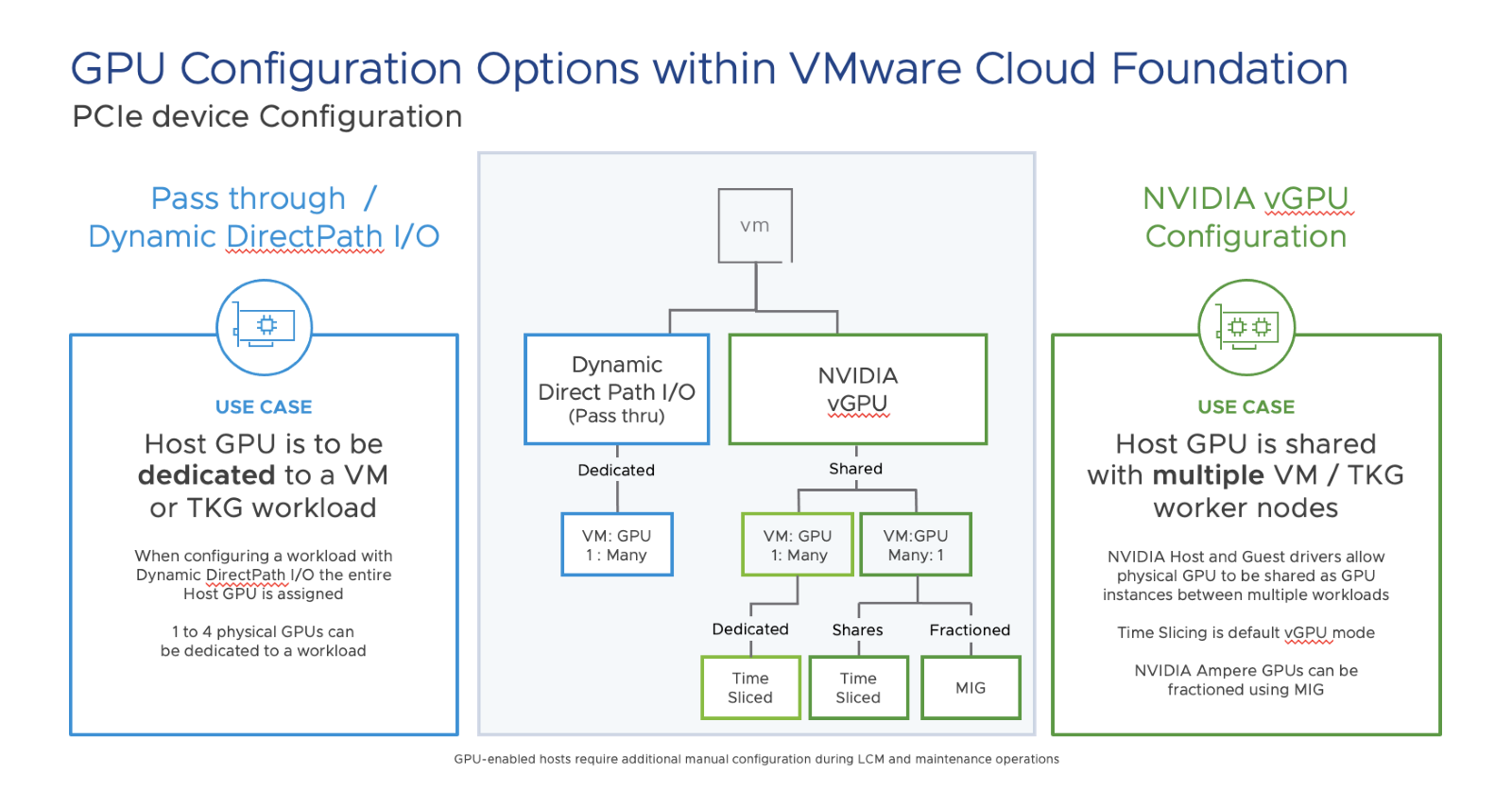
Configuring a GPU as a Pass-through device
The familiar approach, when adding a GPU device within a vSphere-based environment, is to configure it as a pass-through device using Dynamic DirectPath I/O.
When configuring access to GPUs in this way on a host, the entire GPU device is dedicated to a specific TKC worker node. VCF 4.4 supports (1) to four (4) physical GPUs assigned to a VM.
When configuring a GPU as a passthrough device, a virtual machine is pinned to a specific GPU running on a specific host. This is restrictive and means HA, DRS and vMotion of running workloads is not possible.
Configuring the GPU as an NVIDIA vGPU
NVIDIA together with VMware have virtualized the GPU allowing IT teams to drive greater levels of utilization and drive greater economies of scale.
GPU devices to be accessed as an NVIDIA Virtual GPU (vGPU) by deploying the NVIDIA vGPU host driver. This allows multiple running VM workloads on a host to have access to the physical GPU at the same time. The NVIDIA vGPU host driver allows the cores and memory from the GPU device to be shared between multiple virtual machines. The virtual machines can be either traditional VMs or TKC worker node VMs that support the use of consistent upstream-compatible Kubernetes workloads.
As discussed in Part 1 of this blog, the NVIDIA vGPU host driver (obtained in the NVD-AIE_xxx.zip) is configured as part of the cluster image applied by vSphere Lifecycle manager (vLCM).
One of the additional benefits of using an NVIDIA GPU in vGPU mode is that vSphere can utilize DRS for initial VM placement within the cluster. vCenter server will determine which host has the resources available and will place the workload for you. Suspend and resume operations will function and traditional VMs can be migrated between hosts with vMotion support. A pro-tip – if the workload is very large be mindful of large VM stun times when vMotioning.
Note: Many Kubernetes-based workloads are stateless, so vMotion of GPU-enabled Kubernetes worker node VMs is not required in this case. vMotion support applies to traditional GPU-enabled VMs only.
NVIDIA Ampere Class A30 & A100 GPU devices are supported with VCF 4.4. This list may expand and include additional devices in the future.
An NVIDIA Ampere Class vGPU device shares GPU resources in one of two ways:
Time Slicing
Workloads configured in Time-Slicing mode (sometimes called Time Sharing) share a physical GPU and operate in series. Using this method, vGPU processing is scheduled between multiple VM-based workloads using best effort, equal shares or fixed shares.
- Time Slicing mode is the default setting used with NVIDIA vGPU and is supported by NVIDIA Ampere Class devices as well as older GPU models.
- A single physical GPU, when accessed via the NVIDIA vGPU method can be used to support multiple VMs (Multiple VMs: 1 GPU).
- Using the vGPU time-slicing method, we can also configure 1 VM: 1 full GPU or 1 VM: Multiple GPUs (when all GPU memory and cores are fully allocated to that VM).
Multi-instance GPU (MIG)
Multi-instance GPU (MIG) is a new feature supported with the NVIDIA Ampere Class GPUs.
MIG can be configured to maximize utilization of GPU devices and provides dynamic scalability by fractioning a physical GPU device into multiple smaller GPU instances.
MIG isolates the internal hardware resources and pathways within a GPU device to provide more predictable levels of performance to the assigned workloads.
MIG requires an additional configuration step and is enabled via esxcli
Regardless of which option is chosen, NVIDIA vGPU provides the following benefits:
- Manual and automated vMotion (Maintenance mode) for traditional VM-based workloads (this does not apply to TKC Worker node VMs).
- Suspend and Resume of VM workloads.
- DRS initial placement of VMs (DRS load balancing is not currently supported).
- vSphere HA for VM workloads and non-persistent Kubernetes workloads.
We will re-commence configuring an NVIDIA GPU-enabled Tanzu Kubernetes Cluster at Step 8
Step 8. Create a VM Class and allocate GPU devices to the vSphere Namespace
The final step required by the VCF Administrator to configure an NVIDIA GPU for TKC in VMware Cloud Foundation is to add a VM Class and assign GPU resources to that class. Then we add the VM class to the vSphere Namespace where TKCs will use it.
A VM Class is a description that defines CPU, memory, and storage reservations for VMs. VMs can be traditional stand-alone VMs or TKC VMs. The VM Class helps to set guardrails for the policy and governance of VMs by anticipating development needs and accounting for resource availability and constraints.
A VM Class should not be confused with vSphere Namespace Resource Limits. vSphere Namespace Capacity and Usage is managed at a cluster level; VM Class is defined at a per VM level.
VMware Cloud Foundation with Tanzu offers several default VM Classes through vSphere. The VCF Administrator can use them as is, edit, or delete them.
- VM Classes created by the VCF Administrator are available to all vCenter Server clusters and all vSphere Namespaces in these clusters.
- VM Classes are available/can be added to all vSphere Namespaces in vCenter Server. However, DevOps Engineers and Kubernetes Platform Users can use only those VM Classes that the VCF Administrator associates with a particular vSphere Namespace.
When configuring NVIDIA GPU, a Custom VM Class also needs to be configured for the GPU PCIe devices in the cluster.
Note: The remainder of this blog will focus on configuring/addressing the GPU device as an NVIDIA vGPU.
As shown below, the VM Class is configured at the vCenter Server level and is then associated with a vSphere Namespace. Kubernetes Platform Users can then deploy Tanzu Kubernetes Clusters to the vSphere Namespace with one command:
kubectl apply
A vSphere Namespace is a visible object in the vSphere Client.
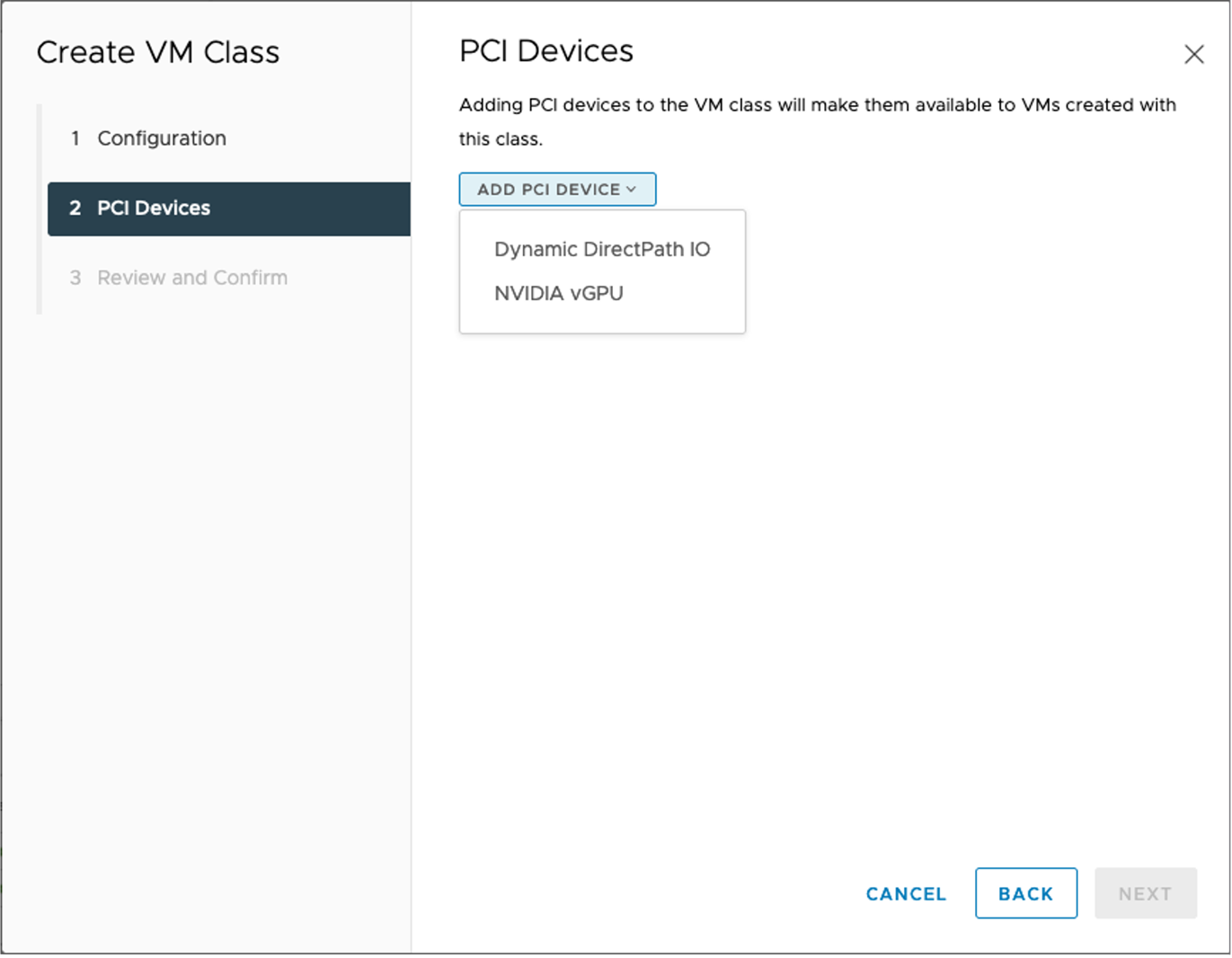
A VM Class is created using the vSphere client. A VM Class is visible to any vSphere cluster within a vCenter server.
When creating a VM Class using Dynamic DirectPath I/O, GPU access is setup as passthrough. When configuring in this way the full GPU device is dedicated to a specific TKC worker node VM.
When NVIDIA vGPU is chosen at VM class creation, the device can be shared with multiple TKC worker node VMs. Choosing this option is desirable as it allows a single NVIDIA GPU device to be shared by multiple TKC VMs, increasing utilization and lowering the costs associated with GPU hardware.
The VCF Administrator can then choose to configure the NVIDIA vGPUs in Time Slicing Mode or MIG mode.
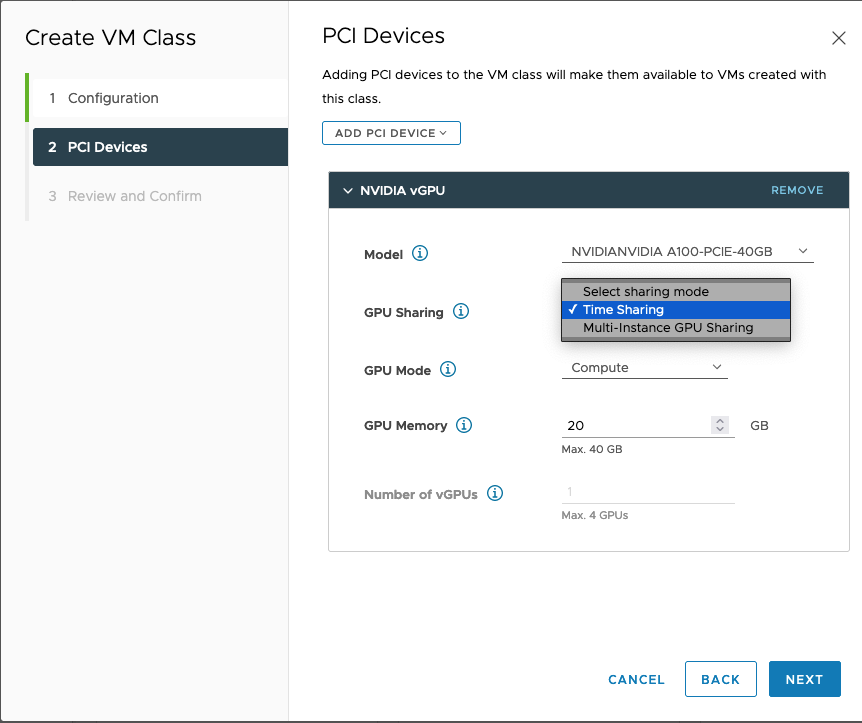
Click here for further detail on configuring a VM Class in vSphere with Tanzu.
Step 9: Allocating GPU
When configuring an NVIDIA vGPU in Time Slicing mode, the VCF Administrator can configure the size of the shares which the Kubernetes Platform User can select from. The size of the vGPU profile is based upon available GPU cores and Memory available.
For example:
- A single NVIDIA A30 GPU configured in Time Slicing mode can use a vGPU profile that supports all 24GB of framebuffer memory.
- A single NVIDIA A100 GPU configured with a fully-sized vGPU profile can support 80GB of framebuffer memory.
- vGPU profiles that contain the full resources of two or more NVIDIA GPUs can be configured in Time Slicing mode to combine their cores and memory onto one VM for larger AI / ML computing requirements .
When configuring the NVIDIA vGPU in MIG mode, the VCF Administrator configures a set of vGPU profiles representing a proportional slice of cores and memory available. An NVIDIA A30 GPU device can be factored into a maximum of 4 slices, an NVIDIA A100 GPU device can be factored into a maximum of 7 slices.
The VCF Administrator can at any time make changes to the way GPU resources are shared or the profile sizes of each MIG slice. However, the changes will only be applied after the VM is shutdown and restarted.
At this point the VCF Administrator has completed the configuration of GPU resources within VMware Cloud Foundation in readiness for Kubernetes Platform Users to start deploying Tanzu Kubernetes Clusters on vSphere clusters.
Within each vSphere Namespace in the vSphere Client, there is a link to the kubectl tool which the VCF Administrator can share with Kubernetes Platform Users.
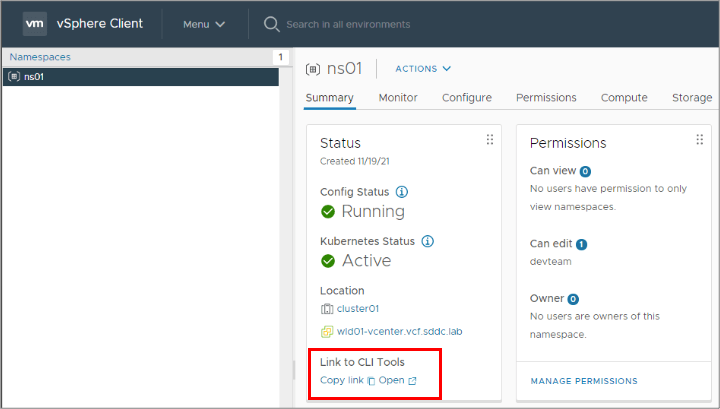
Click here for further detail and demos showing how Kubernetes Platform Users consume GPU resources using Tanzu Kubernetes worker node VMs.
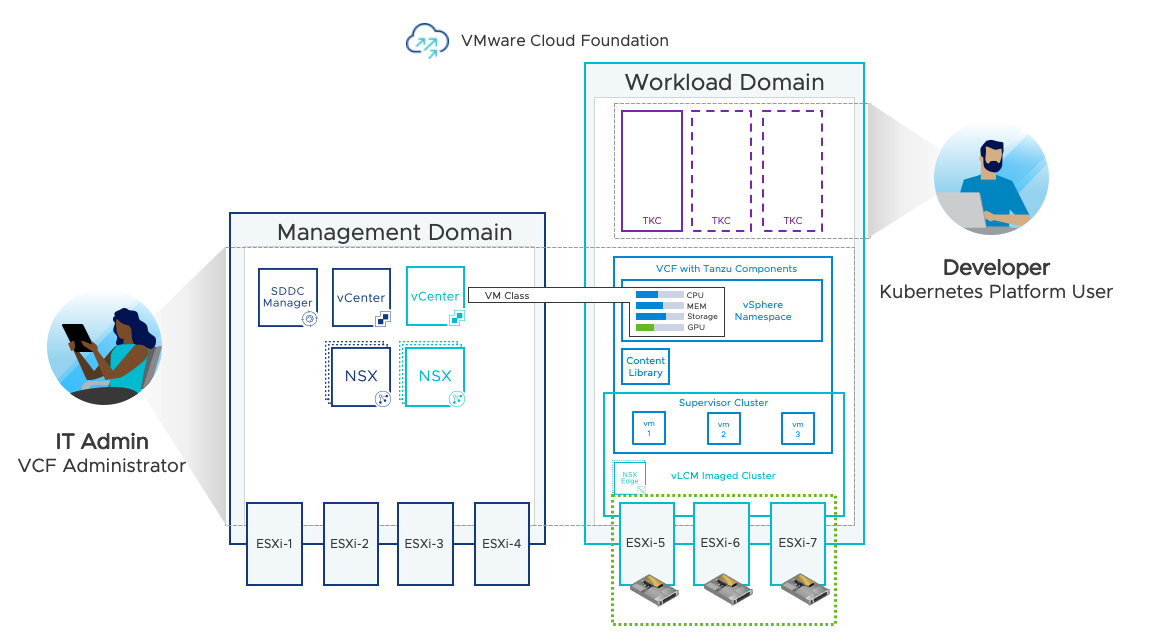
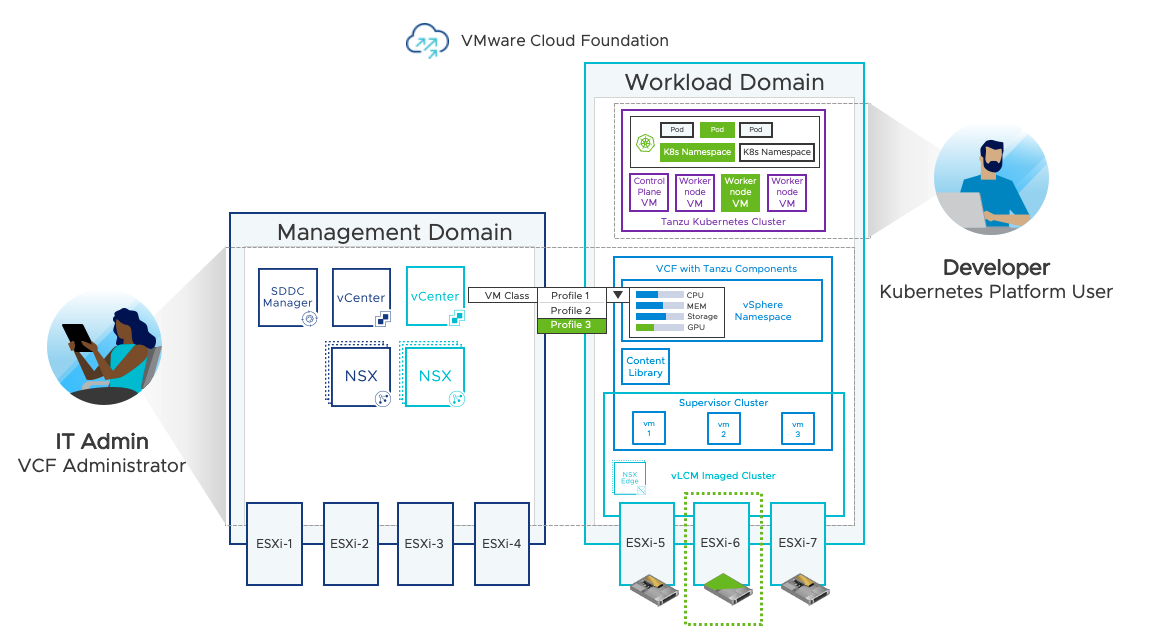
In the diagram below, the VCF Administrator has configured a Custom VM Class and a set of NVIDIA vGPU profiles.
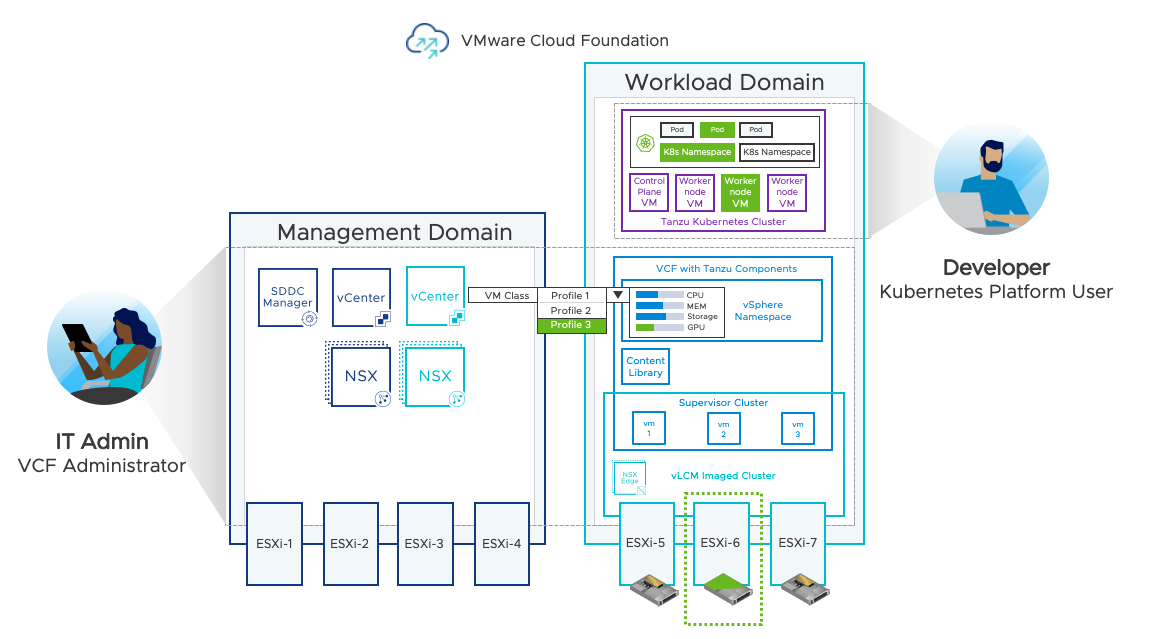
The VM Class has been assigned to the vSphere Namespace. The configuration of GPU infrastructure by the VCF Administrator is now complete and is now available to be consumed by the Kubernetes Platform User.
In order to create Tanzu Kubernetes Clusters, the Kubernetes Platform User needs to be granted “edit” permission to the vSphere Namespace by the VCF Administrator.
Kubernetes Platform Users install the kubectl tool on their workstations to access the VMware Cloud Foundation with Tanzu platform and login to the Supervisor cluster.
TKCs can then be provisioned by Kubernetes Platform Users with a TKC Specification YAML file.
The Kubernetes Platform User can choose to run their own compliant upstream version of Kubernetes on the TKC. From here they can create their own Kubernetes Namespaces and allocate one or more pods to it.
Once the Kubernetes Namespace is configured, the Kubernetes Platform User can instantiate pods to run their containerized applications and services.
The Kubernetes Platform User can then allocate a specific GPU profile to a containerized workload. The containerized workload runs within a Pod on a TKG worker node VM.
vSphere DRS determines available GPU resources available to the TKG worker node VM which in this case is a shared vGPU running on ESXi-6. (components highlighted in green).
Summary:
VMware Cloud Foundation Administrators can extend their software defined private cloud platform to support a flexible, secure and easily scalable AI-ready infrastructure. NVIDIA GPU device support allows GPU resources to be efficiently assigned to Tanzu Kubernetes worker node VMs. This can be done in a variety of different ways in order to maximize the GPU utilization and flexibility. This reduces cost in constructing your AI/ML infrastructure.
VCF Administrators simply provision the necessary GPU-enabled infrastructure to a vSphere Namespace for Kubernetes Platform Users to consume. This infrastructure provides containerized workloads with the additional processing power and memory capacity of GPU devices running within a vSphere cluster.
VMware Cloud Foundation AI-ready infrastructure removes the need to setup, manage and secure additional silos of specialized data center or public cloud infrastructure. It allows IT Infrastructure Teams and Kubernetes Platform Users to better collaborate and accelerate the adoption of AI / ML into their organizations in a cost-effective way.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.


