

Part 1 / 3
In this 3-part technical blog, we will discuss how to prepare a VMware Cloud Foundation Cluster as an AI / ML platform using NVIDIA A30 and A100 GPU devices.
Part 1 will pay close attention to the configuration of a vSphere Lifecycle Manager (vLCM) image for the GPU-enabled cluster.
Introduction
VMware has led the industry in virtualizing CPU workloads as virtual machines, and more recently has extended these capabilities further in supporting running Kubernetes through vSphere. However, some workloads such as AI / ML applications greatly benefit from hardware accelerators such as GPUs to offload large amounts of CPU processing and memory from a host.
VMware in partnership with NVIDIA has integrated the latest virtual GPU (vGPU) capabilities enabled by vSphere, into Cloud Foundation. Virtualizing the GPU allows IT teams to dynamically assign and scale GPU resources where they are needed.
GPU devices no longer need to be dedicated to a specific workload. This increases utilization and drives greater economies of scale, resulting in significant upfront capital and operational savings. NVIDIA GPUs can be shared or fractioned into multiple virtual GPUs (vGPUs) providing multiple users with the GPU compute and memory resources they need.
VMware Cloud Foundation Administrators can now extend their software defined private cloud platform to support a flexible, secure and easily scalable AI-ready infrastructure without having the setup, manage and secure another separate silo of specialized data center or public cloud infrastructure.
How are GPUs Allocated and Consumed in VMware Cloud Foundation
VMware Cloud Foundation 4.4 introduces initial support for NVIDIA A30 and A100 GPU devices for AI / ML workloads. Additional NVIDIA devices may be supported in the future. GPU resources can be efficiently assigned to traditional VMs or Tanzu Kubernetes worker node VMs in a variety of different ways which is economical and simple to deploy.
VCF Administrators (under the persona of an IT Admin) simply provision the necessary GPU-enabled infrastructure to a vSphere Namespace within a Tanzu Kubernetes deployment using a custom VM Class.
Kubernetes Platform Users (under the persona of Data Scientists, Developers, AI Researchers) can allocate GPU resources within their Tanzu Kubernetes Clusters (TKCs) to a Kubernetes worker node VM. Container workloads within Pods running within the Tanzu Kubernetes VMs can leverage the additional processing power and memory capacity provided by the GPU.
Note: GPU resources can be assigned when using the Tanzu Kubernetes Grid service. GPU resources are not supported for use with Pod VMs running natively on vSphere.
Click here to better understand the differences between running vSphere Pods and running Tanzu Kubernetes Clusters.
Preparing a VMware Cloud Foundation Cluster for Tanzu Workloads
Implementing a GPU-enabled cluster within VMware Cloud Foundation is straight forward, with many of the configuration tasks being automated.
Pre-requisites
Before we can start configuring an AI-ready infrastructure on VMware Cloud Foundation with Tanzu, the following needs to be in-place.
- VMware Cloud Foundation 4.4 is deployed.
- A minimum of 4 hosts is required for the initial deployment of VCF which configures the management domain.
- A Virtual Infrastructure (VI) workload domain of 3 or more hosts is required to support an NVIDIA GPU-enabled cluster.
- GPU devices are not supported in the Management Domain or within a Consolidated VCF deployment.
Click here for further detail on VMware Cloud Foundation Architecture.
- Server hosts are vLCM compliant for VCF (OEM vendor supported) and NVIDIA certified* devices.
- One or more identical supported NVIDIA GPU devices is installed in each server host within the VI workload domain containing the GPU-enabled cluster.
- SR-IOV is enabled in both the system BIOS and the vSphere client on each host configured with a GPU device.
- Configure each of the hosts for SharedPassthru. This can be configured using the following command:
esxcli graphics host set –default-type SharedPassthru
- VMware Cloud Foundation and Tanzu licensing.
- NVIDIA vGPU host driver, contained in a VIB. These VIBs are licensed as part of the NVIDIA AI Enterprise Suite.
Note: NVIDIA Ampere Class A30 & A100 GPU devices are supported with VCF 4.4. This list may expand and include additional devices in the future.
Configuration Steps
Below is a summary of the steps to prepare a GPU-enabled cluster to support containerized applications within VMware Cloud Foundation.
 For further detail please refer to the VMware vSphere with Tanzu Configuration Documentation and NVIDIA User Guides.
For further detail please refer to the VMware vSphere with Tanzu Configuration Documentation and NVIDIA User Guides.
Step 1: Prepare Hosts
To commence the process, use SDDC Manager to commission three (3) new ESXi hosts into the VCF Inventory. These hosts will be used to build the GPU-enabled cluster. It is recommended to also create a new Network Pool prior to commissioning the new hosts.
- A minimum of three (3) hosts is required to create a Tanzu Kubernetes Cluster (TKC).
- Ensure ALL hosts within the new cluster are configured with identical NVIDIA GPU devices which are supported by VCF.
From SDDC Manager commission the new hosts into the inventory.
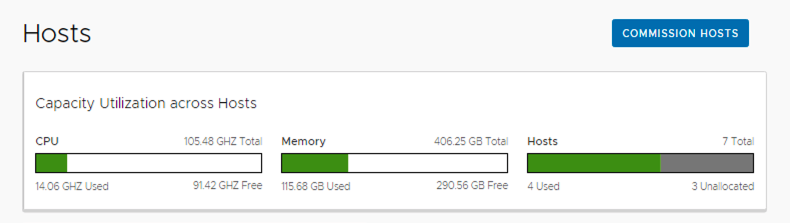
Click here for further detail and a demo on configuring Network Pools and Commissioning new hosts into VMware Cloud Foundation 4.4.
Step 2: Configure a vSphere Lifecycle Manager image for the GPU-enabled cluster
vSphere Lifecycle Manager (vLCM) was introduced with vSphere 7.0 and simplifies the process of deploying, upgrading and patching the software and hardware components of a cluster quickly and consistently.
When configuring a GPU-enabled cluster in VCF, vLCM Images need to be used. vLCM Images use an on-line Image Depot which contain validated ESXi images, certified vendor OEM add-ons (which includes firmware and drivers) and the ability to add or import custom components. vLCM Images follow a desired state model, where ESXi images can be easily composed and applied across hosts within a cluster. vLCM can also check if all hosts within a cluster are compliant and can remediate and update clusters as required.
Custom components which do not appear in the vLCM Image Depot can be imported from a Zip file. The NVIDIA AI Enterprise Suite includes custom kernel modules (VIBs) which can be imported using into the Image Depot using the following process.
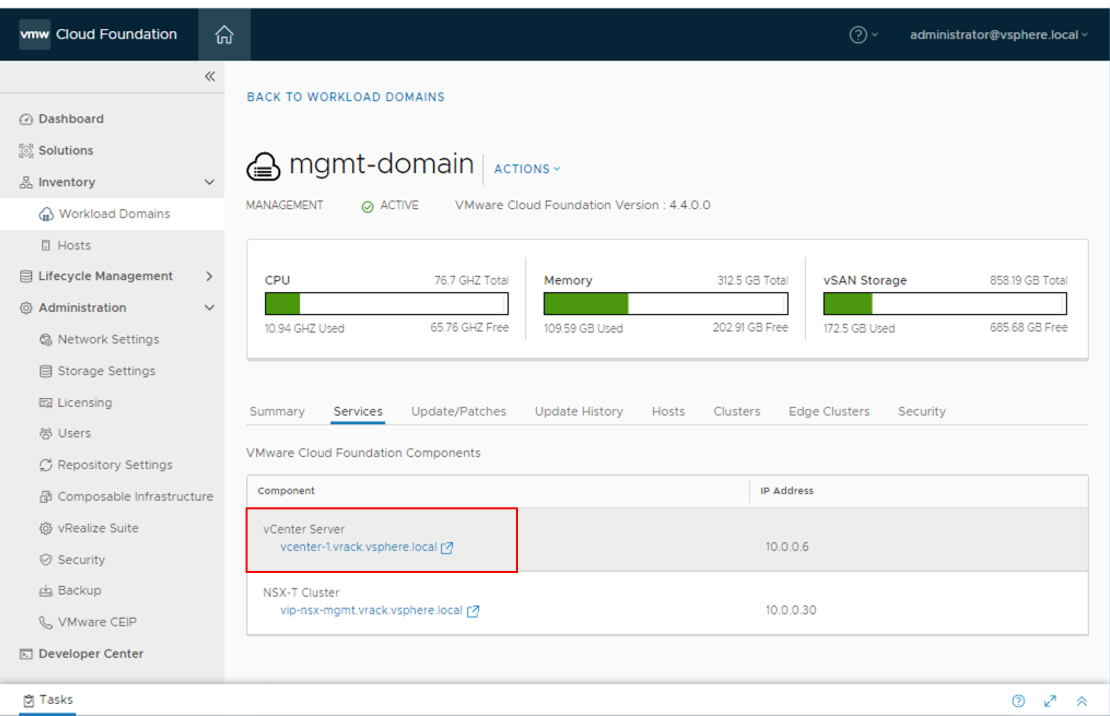
Open the vSphere client and connect to the vCenter server for the Management domain. This can also be accessed from the Management domain Services link within SDDC Manager.
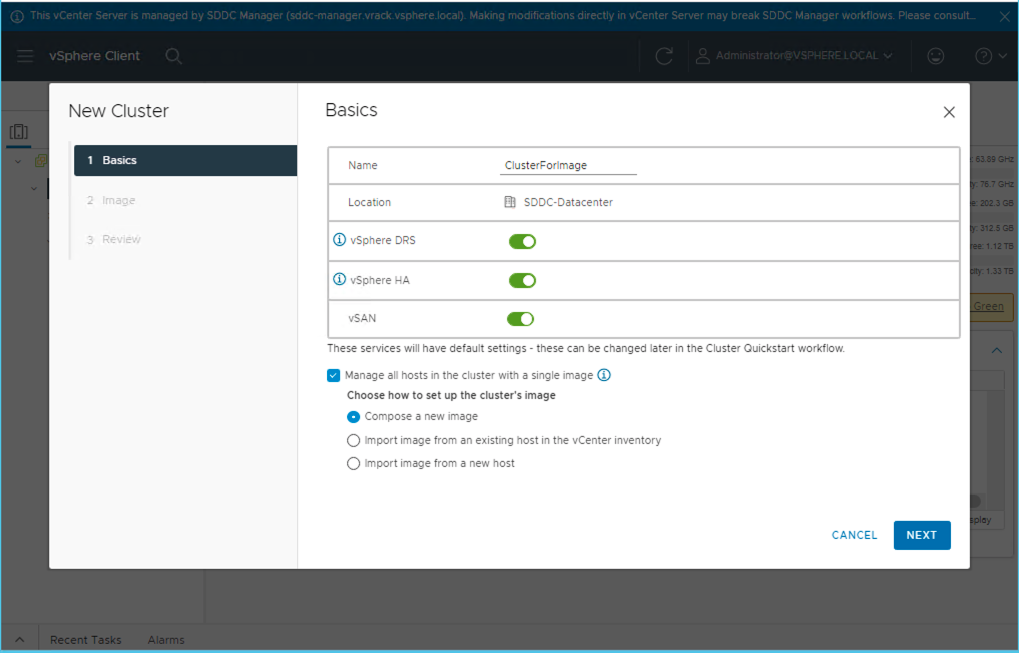
Create a new cluster to be used to compile a vLCM cluster image. This is an empty cluster which will not be configured with any hosts – it is used primarily for the creation of cluster images.
Select the options you wish to configure for vSphere DRS, vSphere HA and vSAN. Select the option to Manage all hosts in the cluster with a single image and select Compose a new image.
To support OEM vendor firmware upgrades through vLCM, select the supported Vendor Addons from the dropdown menu.
Select Finish to complete the basic ESXi host image. This does not yet include the NVIDIA VIB which is added as part of the next step.
Using the vSphere client, Navigate to Lifecycle Manager from the Main Menu.
Within vSphere Lifecycle Manager you will see the Image Depot which contains all the ESXi image versions, Vendor Add-ons and custom Components.
Import the NVIDIA AIE VIB into the Image Depot. Once it is imported it can then be selected as part of an ESXi image which VMware Cloud Foundation can use when deploying a GPU-enabled cluster. The NVIDIA AIE VIB will appear as a custom component.
From the Actions menu select Import Updates.
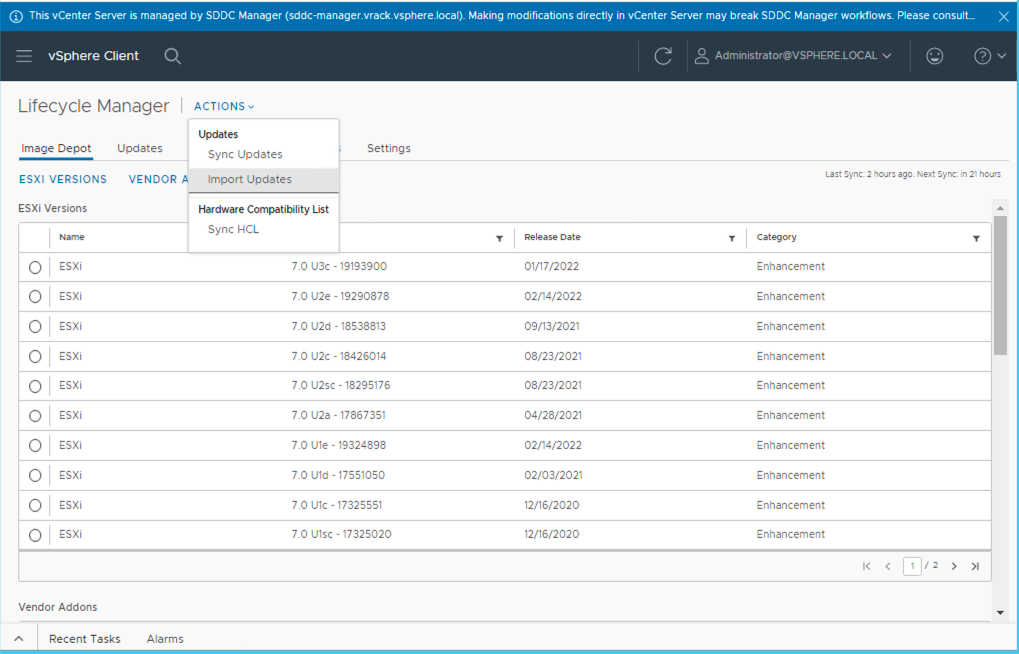
Select the path to the NVIDIA AIE VIB zip file. The NVIDIA VIB and VM driver are included as part of the NVIDIA AI Enterprise Suite (licensing is required). For this to work, ensure you select the extracted NVD-AIE_xxx.zip file within the NVIDIA VIBs package.
Note: In addition to the NVIDIA (host) kernel module AIE VIB, the NVD-AIE_xxx.zip package also contains a VM guest driver which only needs to be configured when GPU devices are used with traditional (stand-alone) VMs. The VM guest driver does not need to be configured for Kubernetes worker node VMs used with VMware Cloud Foundation with Tanzu.
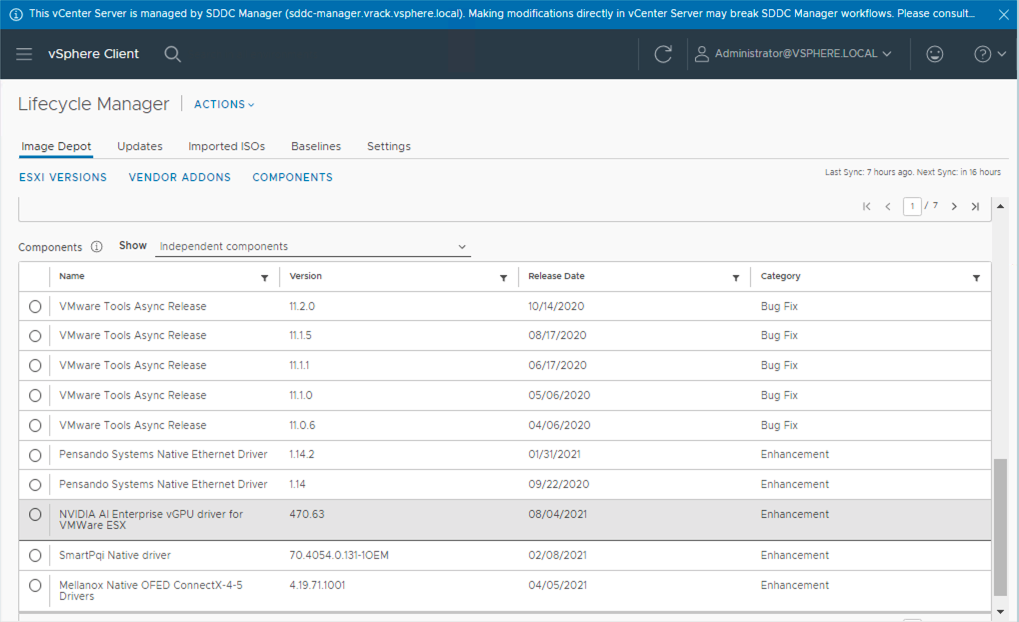
Once uploaded, the NVIDIA AI Enterprise vGPU driver for VMware ESXi will then appear in the Components list within the vLCM Image Depot. From here we can now edit the ESXi desired state image for a cluster of hosts by adding the NVIDIA GPU kernel modules.
To do this, go back into the vCenter Server Inventory View and click to Edit the image we created earlier.
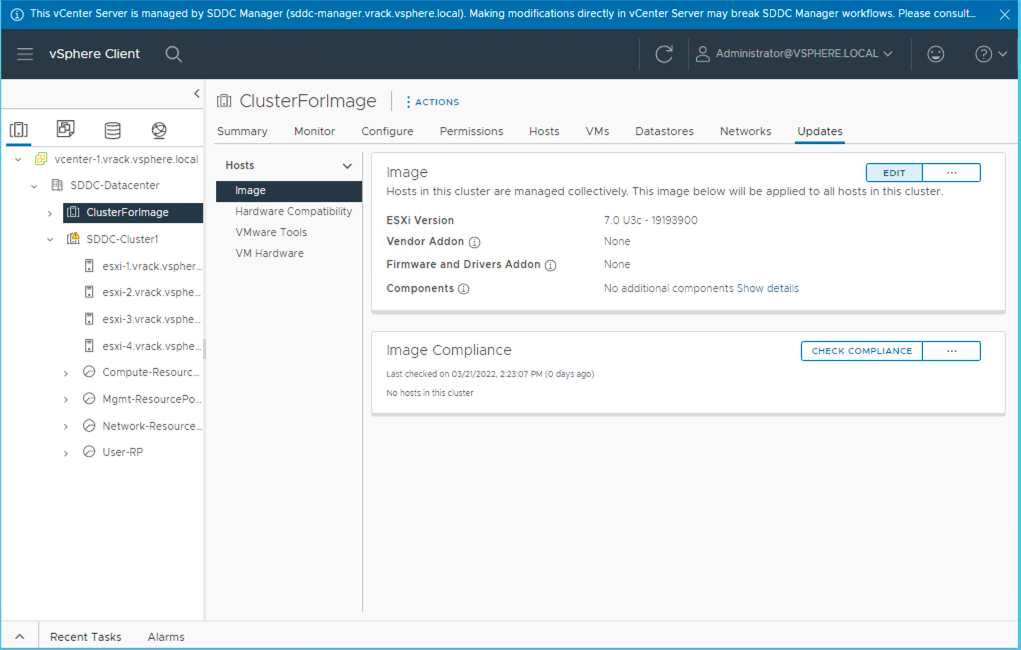
Add the NVIDIA AI Enterprise component which was uploaded to the Components section.
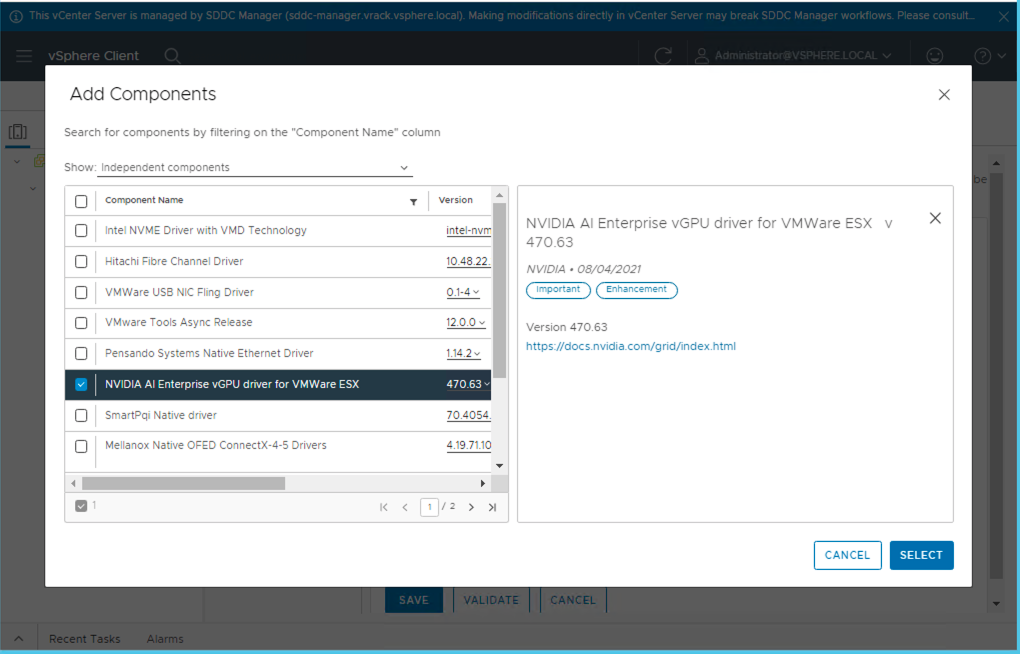
Select Validate and then Save.
The final step is to then to extract the cluster image from vLCM and import it into SDDC Manager.
From SDDC Manager, expand Lifecycle Management and open Image Management. Select the Image Cluster configured earlier which resides in the Management domain and click Extract Cluster Image.
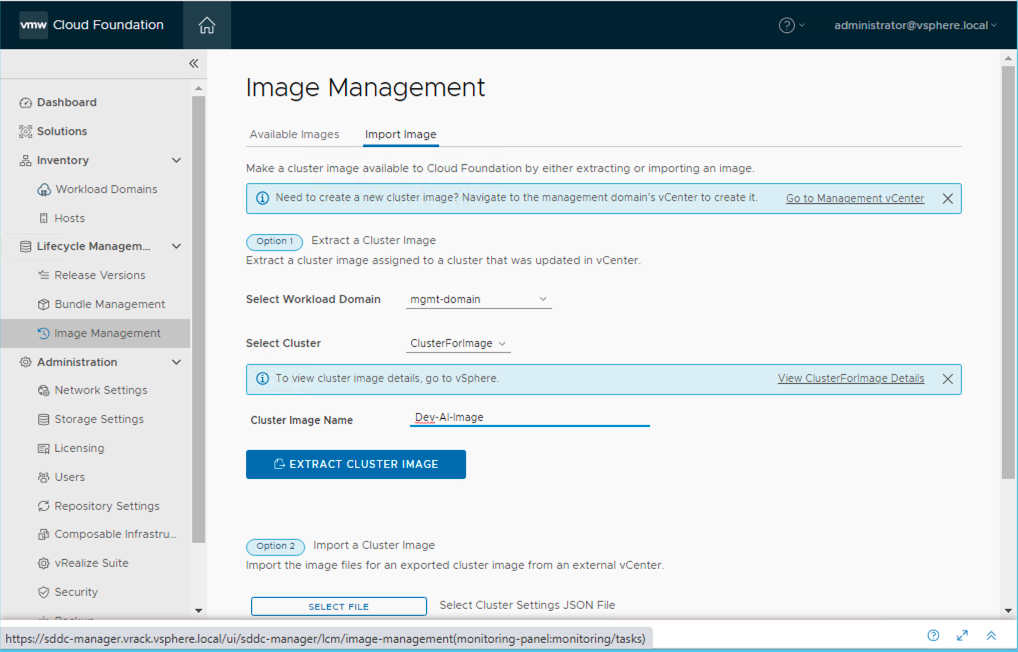
At this point the ESXi image which includes the custom NVIDIA GPU kernel module has been configured and is ready to be applied to any GPU-enabled cluster within a VI Workload domain.
Click here for further detail on configuring vLCM images within VMware Cloud Foundation 4.4.
Step 3: Configure a new VCF VI Workload domain.
A Workload Domain is a logical set of infrastructure designed to run customer applications.
SDDC Manager contains advanced automation to deploy new workload domains quickly in a way that is consistent, repeatable and scalable. Each workload domain contains its own set of software defined policies which allows them to be managed and configured separately providing workload separation.
In this instance this workload domain will provide the underlying infrastructure which includes the underlying NSX networking to run Tanzu Kubernetes clusters (TKC’s) at scale.
Use SDDC Manager automation or the API to configure a new VCF VI Workload domain.
Note: The Management domain is configured using vLCM baselines which does not support GPU device configuration.
Prior to commencing the configuration, the SDDC Manager workflow provides a checklist of pre-requisites to follow.
After checking the pre-requisites, the next step is to select the storage type to use when configuring the workload domain. vSAN is always used in the management domain and is recommended for use in any other domain. Using vSAN provides a full software-defined solution. It is flexible, quick to configure, easy to change and removes the need for manual configuration and potential disruption when changes are needed.
When configuring a GPU-enabled vSphere cluster, storage can be configured to use vSAN, NFS, VMFS on FC or vVols.
Configure the WLD to use the vLCM image which we created earlier in Step 2.
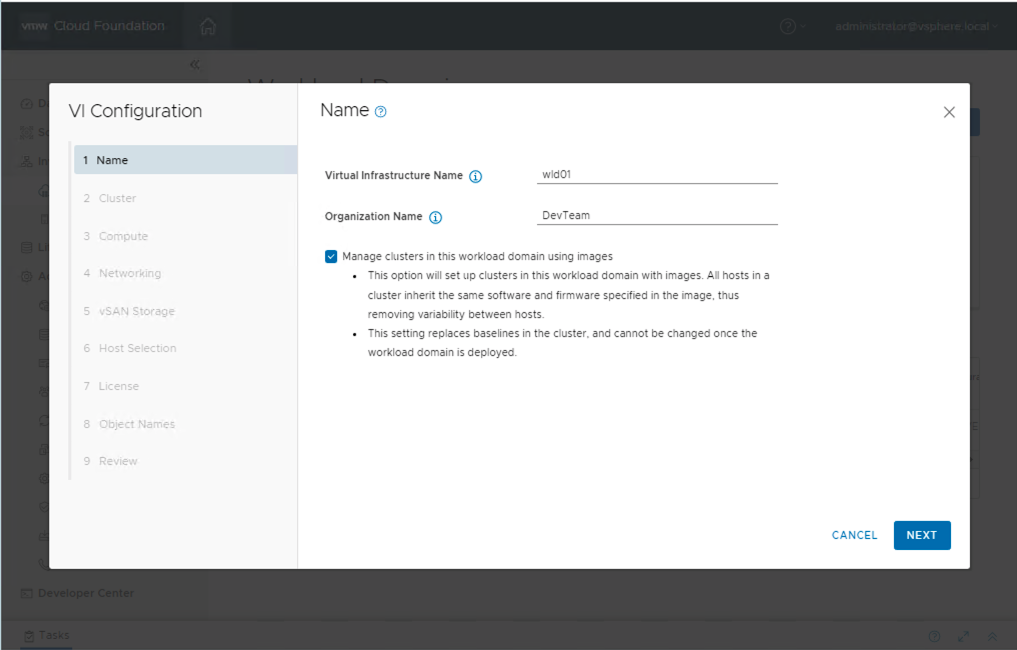
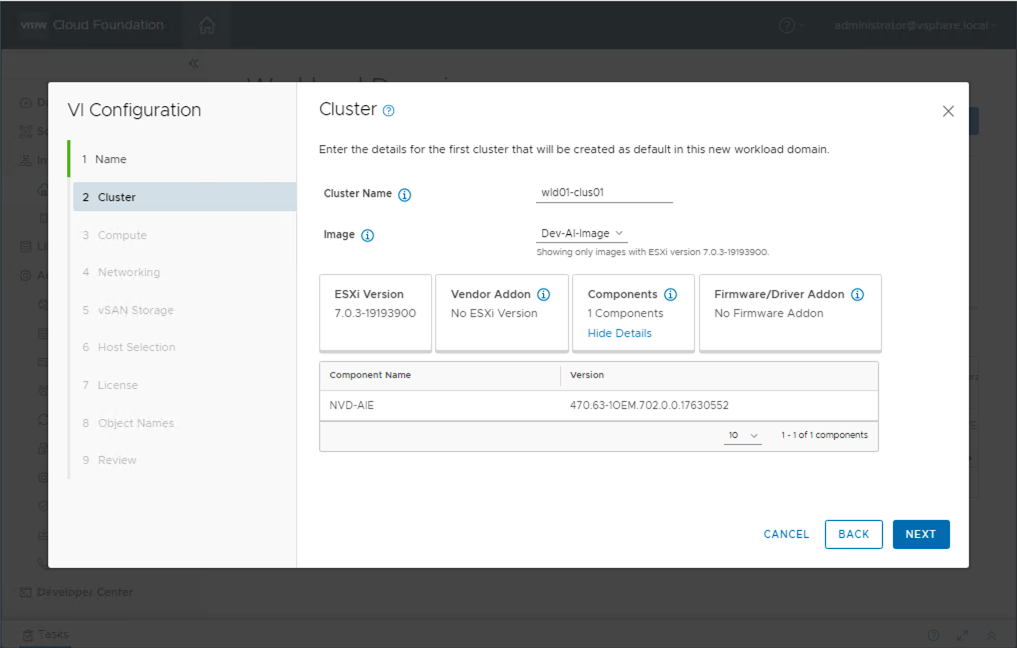
Follow the SDDC Manager workflow to complete the configuration of the workload domain cluster to be configured for GPU.
SDDC Manager initially configures a new VI workload domain with its own dedicated vCenter Server configured in a single cluster. The automated deployment configures the domain using a choice of storage options and a choice of a dedicated or shared NSX networking fabric. Workload domains can be easily scaled using SDDC Manager workflows by adding new clusters or scaling existing clusters.
By using SDDC Manager or by using the API, workload domain deployment is simple and fast and automates over 50 manual tasks
Click here for further detail on configuring workload domains within VMware Cloud Foundation.
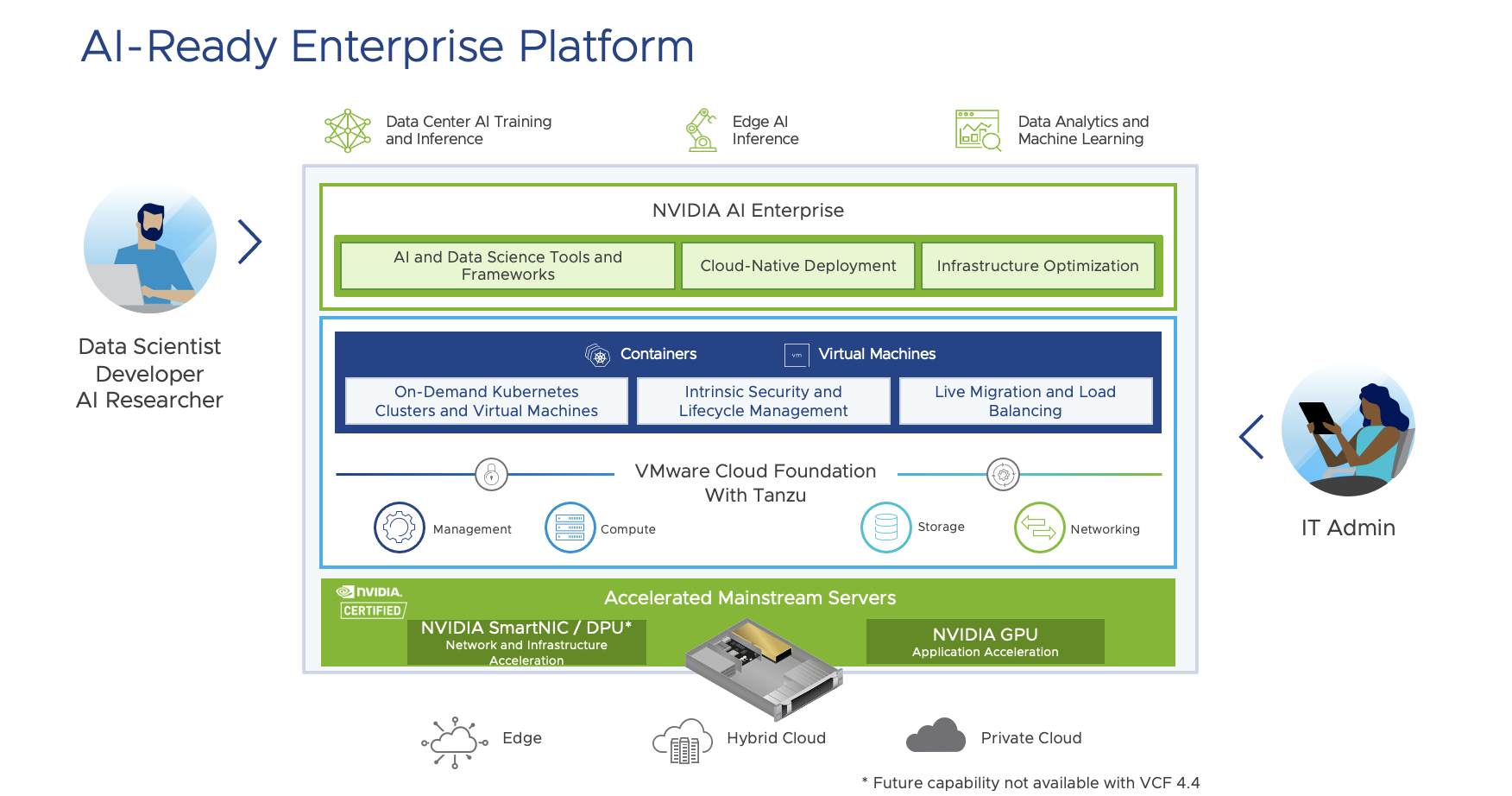
This diagram below shows an overview of the key components deployed so far by a VCF Administrator within a VMware Cloud Foundation environment configured with a GPU-enabled workload domain cluster.
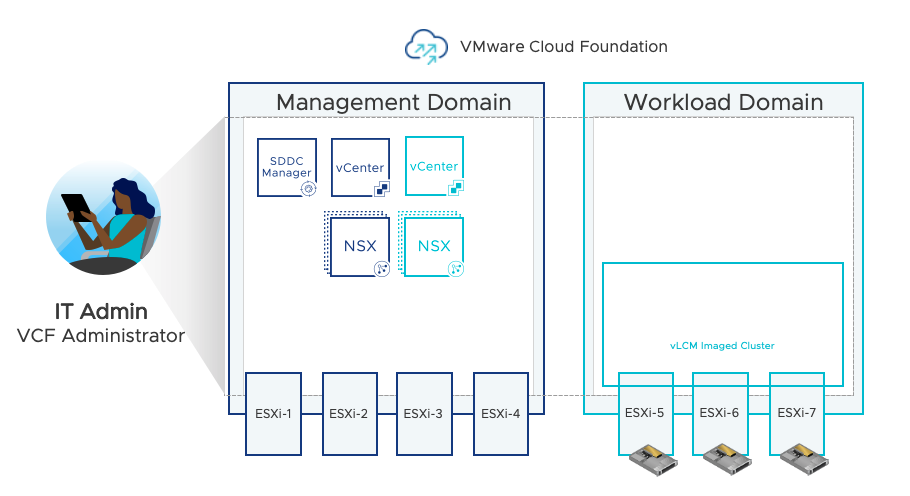
In Part 2 of this blog series, we will discuss the process of configuring the VI Workload Domain for Kubernetes Workload Management. We will discuss setting up an NSX Edge, a Content Library and a vSphere Namespace.
Part 3 will discuss the different ways in which GPU resources can be configured and assigned to Tanzu Kubernetes Clusters for use with containerized applications.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





