Optimized intelligent applications powered by AI are the future of user-centric technology. With the evolution and use of Generative AI (GenAI) application experiences are expanding at an aggressive pace, and organizations representing a wide spectrum of industries are struggling to find the right balance between user experience, innovation and operational efficiency. Safely taking advantage of these rapidly evolving technologies requires careful planning and a clear understanding of the foundational elements that will help you succeed in these efforts.
Foundational Considerations
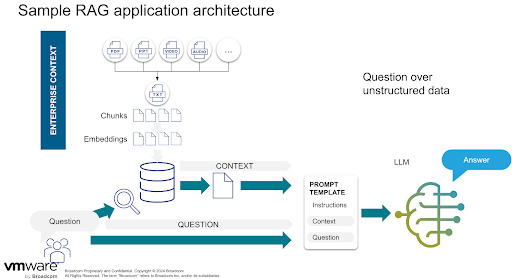
In early 2023, the VMware Tanzu team developed a Retrieval-Augmented Generation (RAG) application for enterprises (more technical details on how we built this application will be forthcoming). This RAG-app enables users to ask questions about their cloud environments—including resources, metadata, configuration, and status—using natural language. Based upon this experience building intelligent applications, and on our numerous customer engagements building and advising organizations on GenAI app delivery, we’d like to share our recommendations for enterprises that are considering building these apps.
Choosing the right models
Not all language models are equal. It’s important to consider the licensing and cost, evaluate inference speed and precision for performance needs, and consider context length and model size. With our RAG application, we initially relied heavily on proprietary models because they had better training and larger model sizes and made it easier to get started. This approach helped us quickly validate our use case and generate accurate GraphQL queries. However, our initial choice of LLM proved to be both slow and costly, prompting us to search for models that might better suit our application. We experimented with faster and cheaper models and conducted rigorous testing to ensure their reliability. The key takeaway is that models are not one-size-fits-all, so you should be prepared to switch models as the situation warrants.
Open source vs. proprietary models
Using open source models can reduce latency and costs and provide more control, especially for on-premises deployments. Enterprises should consider LLM safety when you are weighing your model choices. Initially, when we started our RAG-app journey, the quality of open source models was limited. However, with the release of more advanced OSS LLMs, there are now several robust open source options for enterprise developers to consider.
Malicious actors have been known to exploit LLMs and force them to produce misinformation or damaging propaganda, which can cause damage to your organization’s brand if not checked. This is why tools for AI monitoring are developing (more on that in another forthcoming blog).
Java enjoys first class citizenship
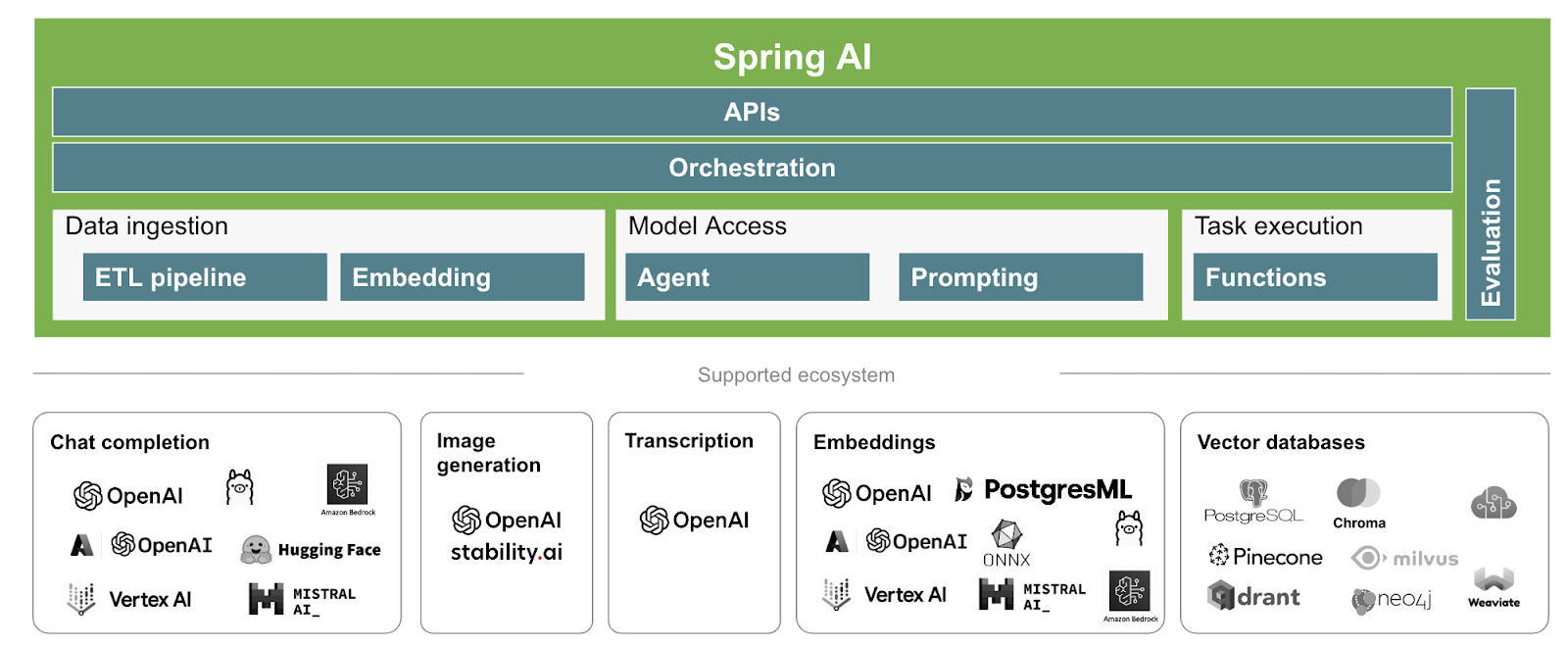
Although a great number of intelligent apps powered by AI are written in Python, they don’t need to be. There is nothing technical in LLMs that require using Python to deliver this new breed of intelligent apps. Java is still the leading programming language for enterprise applications based on its stability, security, extensive library support, and robust performance. Our numbers show that 65% of all enterprise developers use Java, making it essential for business-critical applications. Development frameworks, like Spring AI, enable Java developers to interact with AI models and vector databases through the framework, rather than having to learn new skills.
While we couldn’t use Spring AI for building our RAG-LLM solution because it wasn’t formally launched until November 2023, Java should be considered moving forward for the reasons mentioned above. Spring AI can help your Java developers quickly create intelligent applications.
New types of operational frameworks
In addition to foundational implications, you will need to reconsider your operational models for implementing GenAI intelligent apps. Though we’ve mentioned some of the risks around LLM safety, you should also consider the changes that intelligent apps will require to your overall, day-to-day operations.
Working with large language models (LLMs)
Working with LLMs presents unique challenges, one of which is evaluating the output. Unlike traditional software, LLMs can produce text with high confidence, even if it’s incorrect. This necessitates implementing extensive validation logic to check the accuracy of generated text for both syntactic and semantic before running any queries.
Validation is crucial
Robust mechanisms are needed to validate and ensure that any generated GraphQL or SQL queries are correct. Standard software engineering techniques should be used to verify the accuracy of the generated scripts.
Breaking down complex problems into smaller tasks
One of our first and most important learnings was the necessity to break down complex tasks into smaller, manageable steps. In our case, directly generating a GraphQL query from a prompt was challenging, so decomposing this task into smaller steps improved accuracy and performance.
Handling latency
Serially running multiple steps can introduce latency. To address this, you can optimize by running independent steps in parallel. However, some operations may still require further optimization. Replacing certain language model interactions with local software solutions can significantly reduce latency.
These are just a few things to consider when you are getting started with the development of AI powered intelligent applications. However, the AI space is vast and ever changing so we’ll be dedicating the next several weeks to topics related to this journey.
Moving towards mastery
The future of intelligent app delivery holds immense potential, and being at the forefront of this technological wave is both a challenge and an opportunity. The path to mastery has some known pitfalls, but VMware Tanzu can take some of the guesswork out of developing this next generation of applications.
In addition to Spring AI mentioned above, we just launched our public beta of GenAI on Tanzu Platform, which is open to existing Tanzu Platform customers who are interested in exploring how developers can leverage GenAI for their applications. The existing features are merely a fraction of the comprehensive functionality slated for release by VMware Tanzu, and we will have some exciting announcements leading up to VMware Explore. Watch this space for more to come!.
Download the beta now to get started building intelligent applications powered by AI on Tanzu Platform!