
In this part 1 of 3, I will introduce the challenges with GPU usage and the features and components that can make the building blocks for GPU as a service.
Challenges with GPU Usage
GPUs are getting increasingly faster but not all ML and GPU applications are currently using them. GPUs in the physical bare-metal world are stuck in silos and grossly underutilized. A survey of most enterprises has shown that GPUs are utilized only 25-30% of the time. Even though some GPUs are shared in servers, the majority of GPUs are bound to workstations that are dedicated to individual users. In a typical workflow, a researcher will set up a large number of experiments, wait for them to finish and on completion work to digest the results, while the GPUs sit idling. Due to the dis-aggregated nature of existing GPU infrastructures there is minimal automation and ability to effectively utilize the GPU capabilities. The physical nature of the infrastructure for GPUs does not allow for secure access and sharing across teams with multi-tenancy.
This leads to major inefficiencies in GPU utilization and user productivity. The dis-aggregation of the resources makes it hard to automate the solutions and reduces the overall potential of the infrastructure.
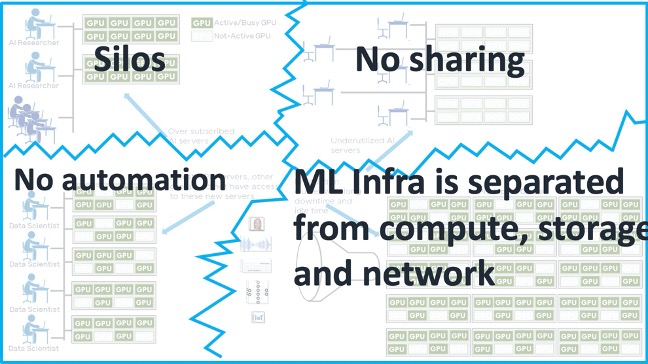
Figure 1: Current challenges with GPU Utilization
Modern Developers & Data Scientist challenges
Modern applications require infrastructures that support all of their components. Without an adaptive infrastructure, developers and IT operators are often at odds and struggle to provide the services that applications require.
- Lack of modern developer services within organization
- Access to the modern coding tools and backend databases is slow
- Deployment, day 2 operations and lifecycle management are painful

Figure 2: Hybrid components of modern IT landscape
IT Operators challenges
- Deploying and configuring right infrastructure defined by Modern App Interfaces
- Infrastructure silos exist as provisioning resources for developers is a nightmare
- Security isolation of modern apps and sensitive databases is difficult
- Inconsistent operations and cross-functional workflows remains a concern
Why Virtualize GPUs for Machine Learning?
Machine learning is a subset of the broader field of artificial intelligence, which uses statistical techniques to allow programs to learn from experiences or from existing data.
Deep learning is a machine learning technique that enables computers to learn from example data. Deep Learning models support applications from autonomously driven vehicles, medical image recognition, voice processing systems and many others. The rise of deep learning platforms has led to an exponential growth in these workloads, both in both data centers and in cloud environments. GPUs provide the computing power needed to run deep learning and other machine learning programs efficiently, reliably and quickly. These GPU-based workloads are even more versatile, flexible and efficient when they run in virtual machines on VMware vSphere. Virtualizing GPUs provides the following advantages:
- Achieve higher utilization of each individual GPU
- Gain greater efficiency through sharing of GPUs across users and applications
- Allow users to make use of partial or multiple GPUs on a case-by-case basis as their applications need them
Features that can be leveraged for machine learning on VMware Cloud Foundation (VCF)
Increasingly, data scientists and machine learning developers are asking their systems administrators to provide them with a GPU-capable machine setup so they can execute workloads that need GPU power. The data scientist often describes these workloads as machine “training,” “inference,” or “development.”
GPUs are commonly used today for highly graphical applications on the desktop. Organizations already using desktop VMs on VCF can also use their existing GPUs for applications other than this virtual desktop infrastructure (VDI) scenario. This non-graphical use case is known as a “Compute” workload in vSphere, and it enables end users to consume GPUs in VMs in the same way they do in any GPU-enabled public cloud instance or on bare metal, but with more flexibility. Through collaboration with VMware technology partners, VMware Cloud Foundation allows flexible consumption and multiple GPU utilization models that can increase the ROI of this infrastructure, while providing end users with exactly what they need.
NVIDIA GPUs for Machine Learning
With the impending end to Moore’s law, the spark that is fueling the current revolution in deep learning is having enough compute horsepower to train neural-network based models in a reasonable amount of time
The needed compute horsepower is derived largely from GPUs, which NVIDIA began optimizing for deep learning in 2012.
The NVIDIA vGPU software family enables GPU virtualization for any workload and is available through licensed products such as the NVIDIA vComputeServer. NVIDIA vComputeServer software, enables virtualize NVIDIA GPUs to power the more than 60 GPU accelerated applications for AI, deep machine learning, and high-performance computing (HPC) as well as the NGC GPU optimized containers. With GPU sharing, multiple VMs can be powered by a single GPU, maximizing utilization and affordability, or a single VM can be powered by multiple virtual GPUs, making even the most compute-intensive workloads possible. With vSphere integration, GPU clusters for compute can be managed by vCenter, maximizing GPU utilization and ensuring security.

Figure 3: Layered model showing NVIDIA vGPU components
High Speed Networking with PVRDMA & RoCE
Remote Direct Memory Access (RDMA) provides direct memory access from the memory between hosts bypassing the Operating System and CPU. This can boost network and host performance with reduced latency & CPU load while providing higher bandwidth. RDMA compares favorably to TCP/IP, which adds latency and consumes significant CPU and memory resources. Mellanox conducted Benchmarks that demonstrated NVIDIA® vComputeServer or virtualized GPUs achieve two times better efficiency by using VMware’s paravirtualized RDMA (PVRDMA) technology than when using traditional networking protocols.
RDMA over Converged Ethernet
RDMA over Converged Ethernet (RoCE) is a network protocol that allows remote direct memory access (RDMA) over an Ethernet network. There are two RoCE versions, RoCE v1 and RoCE v2. RoCE v1 is an Ethernet link layer protocol and hence allows communication between any two hosts in the same Ethernet broadcast domain. RoCE v2 is an internet layer protocol which means that RoCE v2 packets can be routed. Although the RoCE protocol benefits from the characteristics of a converged Ethernet network, the protocol can also be used on a traditional or non-converged Ethernet network. (Source: Wikipedia)
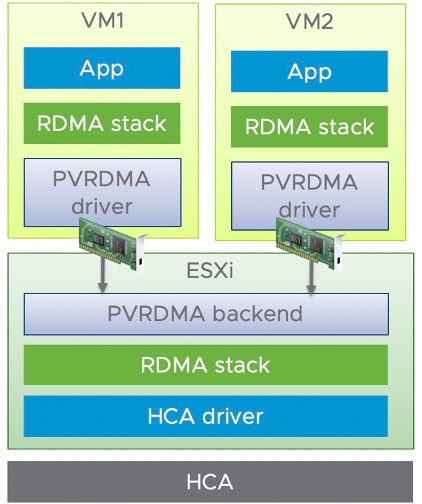
Figure 4: The end to end PVRDMA stack
PVRDMA in vSphere
In vSphere, a virtual machine can use a PVRDMA network adapter to communicate with other virtual machines that have PVRDMA devices. The PVRDMA device automatically selects the method of communication between the virtual machines. vMotion is supported when PVRDMA is used as the transport mechanism.
vSphere Bitfusion
vSphere Bitfusion extends the power of VMware vSphere’s virtualization technology to GPUs. vSphere Bitfusion helps enterprises disaggregate the GPU compute and dynamically attach GPUs anywhere in the datacenter just like attaching storage. Bitfusion enables use of any arbitrary fractions of GPUs. Support more users in test and development phase. vSphere Bitfusion supports the CUDA API and demonstrates virtualization and remote attach for all hardware. GPUs are attached based on CUDA calls at run-time, maximizing utilization of GPU servers anywhere in the network.

Figure 5: Elastic AI Platform with vSphere Bitfusion
Bitfusion is now part of vSphere and NVIDIA GPU accelerators can now be part of a common infrastructure resource pool, available for use by any virtual machine in the data center in full or partial configurations, attached over the network. The solution works with any type of GPU server and any networking configuration such as TCP, RoCE or InfiniBand. GPU infrastructure can now be pooled together to offer an elastic GPU as a service, enabling dynamic assignment of GPU resources based on an organization’s business needs and priorities. Bitfusion runs in the user space of a guest operating system and doesn’t require any changes to the OS, drivers, kernel modules or AI frameworks.
In part 2 we will look at how VMware Cloud Foundation components can be assembled to provide GPUs as a service to your end users. In part 3, we will look at a sample design of a GPU cluster.
Call to Action:
- Audit how GPUs are used in your organization’s infrastructure!
- Calculate the costs and utilization of the existing GPUs in the environment
- What are the use cases for GPUs across different groups?
- Propose an internal virtualized GPUaaS infrastructure by combining all resources for better utilization and cost optimization.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





