
VMware is committed to helping customers build intelligent infrastructure and optimize workload execution. With the rapidly growing interest in Machine Learning (ML) and High Performance Computing (HPC), hardware accelerators are increasingly being adopted in private, public, and hybrid cloud environments to accelerate these compute-intensive workloads. As part of facilitating this IT infrastructure transformation, VMware is collaborating with partners to ensure accelerated computing capabilities are available on vSphere for our customers.
Previously, we have demonstrated enablement of high-end GPUs and high-speed interconnects on vSphere with close-to-native performance for various ML and HPC workloads. Check here and here for our previous articles. In this article, we will demonstrate vSphere’s compatibility with another important hardware acceleration technology, i.e., FPGA, based on our recent collaboration with Xilinx. Given the focus of Xilinx FPGA on ML inference, we will show how to use Xilinx FPGA with VMware vSphere to achieve high-throughput and low-latency ML inference.
Xilinx FPGA and its advantages
FPGAs are adaptable devices that can be re-programmed to meet different processing and functionality requirements of desired applications, including but not limited to ML, Video, Database, Life Science, and Finance. This feature distinguishes FGPAs from GPUs and ASICs. In addition, among many commonly known benefits FPGAs also have advantages in achieving high energy efficiency and low latency compared to other hardware accelerators. This makes FPGAs especially suitable for ML inference tasks. Different from GPUs, which fundamentally rely on a large number of parallel processing cores to achieve high throughput, FPGAs can simultaneously achieve high throughput and low latency for ML inference through customized hardware kernels and data flow pipelining.
Vitis AI is Xilinx’s unified development stack for ML inference on Xilinx hardware platforms from Edge to Cloud. It consists of optimized tools, libraries, models, and examples. Vitis AI supports mainstream frameworks, including Caffe and TensorFlow, as well as the latest models capable of diverse deep learning tasks. In addition, Vitis AI is open source and can be accessed on GitHub.

Vitis AI software stack [1]
For this article, we use a Xilinx Alveo U250 datacenter card in our lab for testing, and ML models are quickly provisioned using Docker containers provided in Vitis AI. Before presenting the testing results, let’s first discuss how to enable FPGA on vSphere.
Configure Xilinx FPGA on vSphere
Currently, Xilinx FPGAs can be enabled on vSphere via DirectPath I/O mode (passthrough). In this way, an FPGA card can be directly accessed by applications running inside a VM, bypassing the hypervisor layer and thereby maximizing performance and minimizing latency. Configuring an FPGA in DirectPath I/O mode is a straightforward two-step process: First, enable the device on ESXi at the host level, and then add the device to the target VM. Detailed instructions can be found in this VMware KB article. Note that if you are running vSphere 7, host rebooting is no longer required.
Performance
We evaluate throughput and latency performance of Xilinx Alveo U250 FPGA in DirectPath I/O mode by running inference with four CNN models, namely Inception_v1, Inception_v2, Resnet50, and VGG16. These models vary in the number of model parameters and thus have different processing complexity.
The server used in this test is a Dell PowerEdge R740, which has two 10-core Intel Xeon Silver 4114 CPUs and 192 GB of DDR4 memory. The hypervisor used is ESXi 7.0, and end-to-end performance results for each model are compared to bare metal as the baseline. For fairness, Ubuntu 16.04 (kernel 4.4.0-116) is used as both the guest and native OS. In addition, Vitis AI v1.1 along with Docker CE 19.03.4 are used throughout the tests.
We use a 50k-image data set derived from ImageNet2012. Further, to avoid disk bottleneck in reading images, a RAM disk is created and used to store the 50k images. With these settings, we are able to achieve similar performance to Xilinx published performance here. The performance comparison between virtual and bare metal can be viewed in the following two figures, one for throughput and the other for latency. The y-axis is the ratio between virtual and bare metal, with y=1.0 meaning the performance in virtual and bare metal is identical. Note that for throughput higher is better, but for latency lower is better.
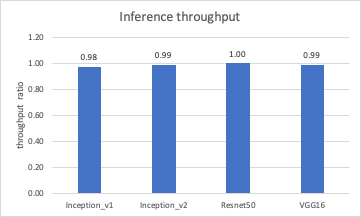
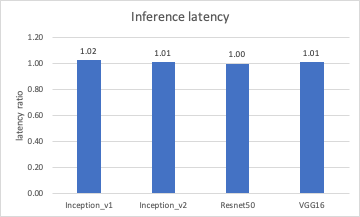
It’s clear from the figures that for these tests the performance gap between virtual and bare metal is capped at 2%, for both throughput and latency. This indicates that the performance of Alveo U250 on vSphere is very close to the bare-metal baseline.
Summary
It’s expected that the adoption of hardware accelerators will continue to increase in the near future in order to meet the growing demand for computing power. At VMware, significant R&D efforts are invested in ensuring that our customers can take advantage of these advanced technologies on the vSphere platform. As part of fulfilling this vision, in this article we showcase the use of FPGA on vSphere for ML inference through our partnership with Xilinx. Also, we present experimental results that demonstrate the close-to-native performance achieved with DirectPath I/O mode.
References
[1] Vitis AI GitHub page. https://github.com/Xilinx/Vitis-AI.
Author: Michael Cui, OCTO
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





