
Machine learning (ML) has recently undergone huge progress in research and development. Importantly, the emergence of deep learning (DL) and the computing power enhancement of accelerators like GPUs have together enabled a tremendous adoption of machine learning applications. This has caused machine learning to have a broader and deeper impact on our lives in many areas like health science, finance, security, data center monitoring and intelligent systems. Hence, machine learning and deep learning workloads are also growing in the datacenters and cloud environments.
To support customers with deploying ML / DL workloads on VMware vSphere, we conducted a series of performance studies on ML-based workloads using GPUs. Either direct pass-through (e.g. VMware DirectPath I/O) or mediated pass-through (e.g. NVIDIA GRID vGPU) can be applied to run workloads that use GPUs. In this blog post, we summarize the benefits of both pass-through and GRID vGPUas well as analyze their performance impacts from multiple aspects: performance comparisons, scalability, the use of a container inside a VM for ML workloads, mixing workloads, vGPU scheduling and vGPU profile selection.
Modes of GPU usage
There are two primary ways in which applications running in virtual machines on vSphere can make use of GPU processing power.
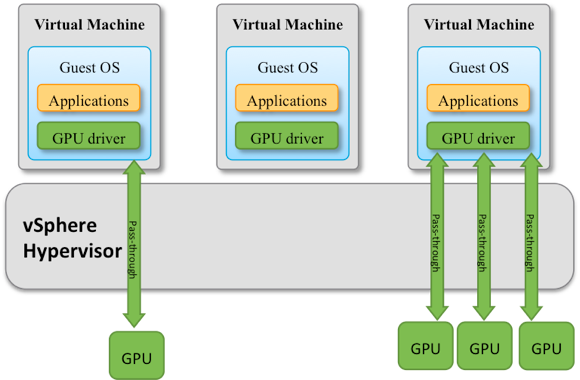
Passthrough mode (VMware DirectPath I/O) – allows direct access from the guest operating system in a virtual machine (VM) to the physical PCI or PCIe hardware devices of the server controlled by the vSphere hypervisor layer. This mode is depicted in Figure 1. Each VM is assigned one or more GPUs as PCI devices. Since the guest OS bypasses the virtualization layer to access the GPUs, the overhead of using passthrough mode is low. However, there is no GPU sharing amongst VMs when using this mode.
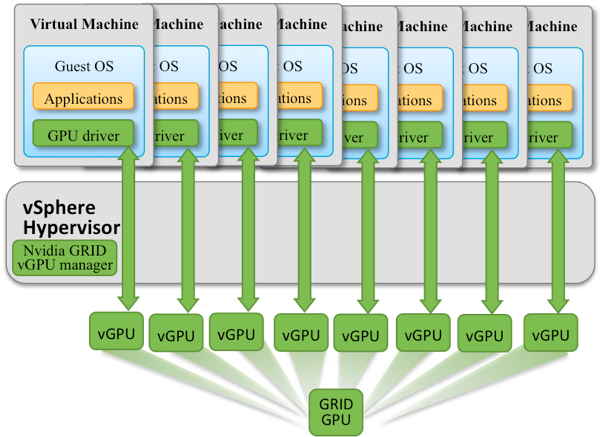
Mediated pass-through (NVIDIA GRID vGPU) – this mode enables well-known virtualization benefits, such as (1) cloning a VM and (2) suspending and resuming a VM. It also allows multiple VMs sharing same physical GPU. The NVIDIA GRID vGPU manager is installed into the hypervisor layer (i.e. VMware ESXi) that virtualizes the underlying physical GPUs (Figure 2). The graphics memory of the physical GPU is divided into equal chunks and those chunks are given to each VM. The type of vGPU profile determines the amount of graphics memory each VM can have.
Results
These are some highlights of our exploration on virtualized GPUs on VMware vSphere.
Performance
To understand the performance impact of machine learning with GPUs using virtualization, we compared the performance of virtual GPU vs. physical GPU by benchmarking the same ML workload in three different cases: (1) GPU using DirectPath I/O on vSphere, (2) GRID vGPU on vSphere and (3) native GPU on bare metal.Our results show that the virtualization layer (DirectPath I/O and GRID vGPU) introduced only a 4% overhead for the tested ML application. For more information on this, read this previous blog post.
Scalability
We evaluated the scalability of a GPU-based workload on vSphere: scaling the number of users or virtual machines (VMs) using GPU per server and scaling the number of GPUs per VM. With DirectPath I/O, one or more GPUs can be assigned to a single VM. That assignment makes this solution a suitable choice for heavy ML workloads requiring one or multiple dedicated GPUs. With GRID vGPU, NVIDIA Pascal GPUs and later versions support the compute capability for multiple vGPU profiles. This allows many VMs running ML workloads to share a single physical GPU and helps increase the system consolidation and utilization. Using GRID vGPU is suitable for those use cases where more VMs or users need a GPU capability than there is available. Our study shows a good scalability of virtualized GPUs. We also present the scalability in detail in the blog post and there are more updates in our recent GPU Technology Conference (GTC) 201 session.
Containerized Machine Learning Applications inside a VM
Containers are rapidly becoming a popular environment in which to run different applications, including those in machine learning. For GPU-based applications, we can use NVIDIA Docker (a wrapper around the Docker command line that understands CUDA and GPUs) to run applications that use NVIDIA GPUs. We compared the performance of a container running natively on centOS with a GPU installed in the host OS with that of a container running inside a VM equipped with a vGPU. We trained a convolutional neural network (CNN) on MNIST, a handwriting recognition application, while running it in a container on CentOS executing natively. Then we also trained the CNN on MNIST while running in a container inside a CentOS VM on VMware vSphere. In our experiments, we demonstrated that running containers in a virtualized environment, such as in a CentOS VM on vSphere, incurred no performance penalty, while it allowed the system to benefit from other virtualization features, especially in the security area. We describe this use case in detail here.
Mixing GPU-based Workloads: Graphics, ML and Knowledge Worker
For ML workloads using GPU, most of the computation is offloaded from the CPUs to the GPU and the CPU is under-utilized. In such use cases, mixing workloads on vSphere can increase the consolidation of VMs on a single server and the efficiency of resource usage. We characterized the performance impact of running 3D-CAD, machine learning and knowledge worker (Non-GPU) workloads concurrently on the same server. Our experiments showed that the ML training times increased by a factor of 2% to 18% as we scaled the number of knowledge worker VMs from 32 to 96. The impact on 3D CAD workloads ranged from 3% to 9% and the impact on the knowledge worker latencies was less than half a percent as we scaled the number of knowledge worker VMs from 32 to 96. For more information, see our blog post and our recent tech talk.
vGPU scheduling
NVIDIA GRID vGPU on vSphere provides three scheduling policies that specify how VMs with ML workloads can share GPUs concurrently: Fixed Share, Equal Share and Best Effort Scheduling. The selection of scheduling policies depends on the business use cases. We characterize the performance impact of these scheduling options here.
vGPU profile selection
NVIDIA GRID vGPU on vSphere has multiple options for the vGPU profile. Each profile specifies the amount of GPU memory each VM can use and the maximum number of VMs that can share a single GPU. We discuss how to select the right vGPU profile and its performance impact here.
More Information
Please check out our GTC 2018 tech talks for the latest updates on this topic.
- Machine Learning on VMware vSphere using NVIDIA’s Virtualized GPUs
- Maximizing The Power of GPU For Diverse Workloads of Enterprise Digital Workspaces On VMware vSphere
Guest Post by Uday Kurkure, Hari Sivaraman, and Lan Vu
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





