vCenter High Availability (VCHA) was introduced in vSphere 6.5 in November 2016. Since that time the Technical Marketing team has spent a lot of time creating content and speaking about VCHA. Much of that content can be found on vSphere Central. Even with all that content, there are still some common questions and misconceptions regarding this feature. In this series of blog post we’ll discuss the differences between the Basic and Advanced deployment, deployment considerations, and operational aspects of VCHA.
Basic vs Advanced
One of the most common questions we get and misconceptions I hear about is that in order to get all the features of VCHA you need to deploy using the Advanced workflow. This is absolutely false. In fact, VCHA is exactly the same regardless of how it is deployed. I strongly recommend that you use Basic to deploy VCHA if possible. I think, in hindsight, it may have been better to call these Automated (Basic) and Manual (Advanced).
With Basic we do the setup for you – adding the 2nd NIC, cloning, resizing the Witness VM, and setting up the DRS anti-affinity rules. With the Advanced setup you have to do all of that work manually. In addition, lets say you need to do something that requires you to destroy the VCHA cluster such as changing certificates, changing the IP of vCenter Server, or restoring vCenter Server. If you used the Advanced workflow to configure VCHA, then you have quite a bit of work to redo. If you used Basic then you can have VCHA back up and running with 30 seconds worth of work.
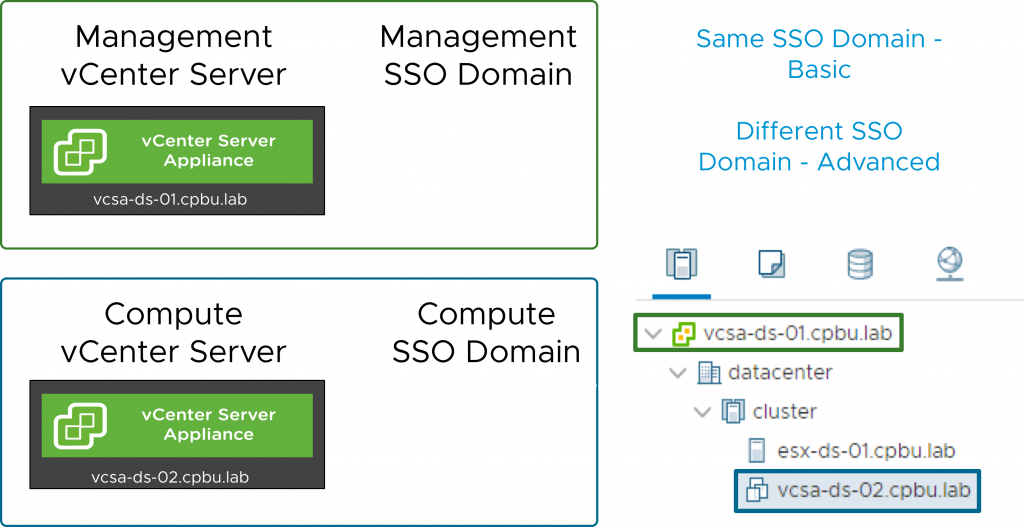
You might be thinking, “Ok, so when should I used Advanced?” Advanced is there in the case where your vCenter Server is running in a management cluster which is in a different SSO domain. For example, say we have a Compute vCenter in a compute SSO Domain, but the vCenter sits in the inventory of the Management vCenter and Management SSO domain we will need to use the advanced deployment. If that Compute vCenter Server is in the same SSO Domain as the Management vCenter Server on which you’re enabling VCHA, then you can use Basic. One final reason why you might consider using Advanced is if you’re going to split your VCHA nodes across different sites. I’ll get into more of this in a moment.
The key is that many customers should be able to use Basic and not have to deal with the manual work of the Advanced workflow. Remember that the outcome is the same. VCHA is VCHA regardless of how it is deployed so don’t assume you need to use Advanced.
Protecting vCenter Server with VCHA
This topic is probably the one I spend the most time on when talking with customers. This is a somewhat complicated topic so I’ll try to break it down into consumable chunks. First, let’s try and understand what failures VCHA is helping us protect against. A VCHA failover, that is a failover from Active to Passive node, can be a recovery from the following failures:
hardware or complete host failure
network failure or isolation
storage failures
vCenter Server application or service failure
operating system failure
Given the above failure modes and VCHA’s ability to recover from them, VCHA can be a robust HA solution for vCenter Server. There is one additional item that you may be wondering about, though. What if you have multiple locations and you want to protect vCenter Server from a complete site failure? Well, this is indeed possible but with some caveats. The most important point to make when talking about using VCHA to protect vCenter Server from site failure is that VCHA is very much an HA solution and not a DR solution. VCHA, if configured properly, will indeed recover your vCenter Server Appliance to an alternate node running in another location. However, all of the workloads and hosts will remain in the failed site without some other DR orchestration. So, I would recommend using a complete DR orchestration strategy to protect vCenter Server from site failure rather than just VCHA.
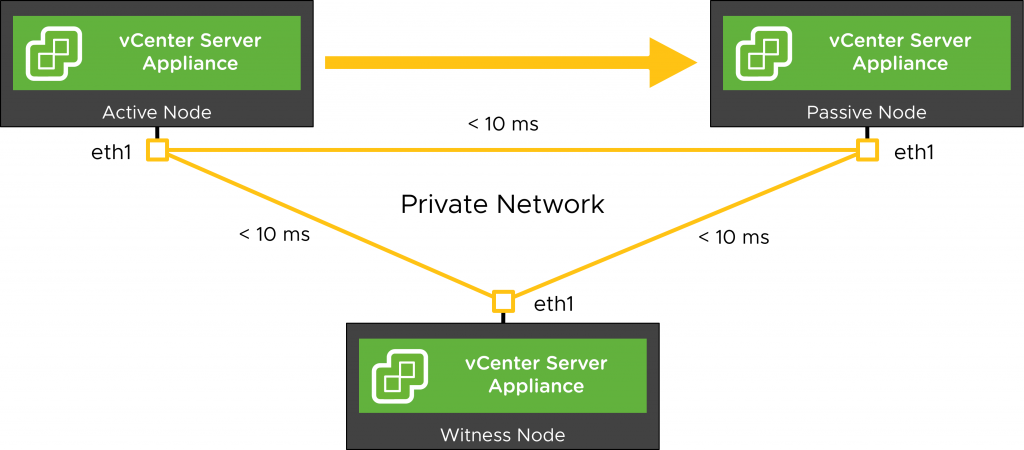
Some other points of note are that there is the 10ms RTT time requirement between all three nodes along with understanding the impacts of the networking of the VCHA network. If there is no stretched L2 (either via a conventional technology such as Cisco’s OTV or an overlay like VXLAN) then the IP address of vCenter Server has to change during a failover event. This part is automated for you but what isn’t automated is DNS. The A record for vCenter Server is controlled by whatever DNS service is being used in your environment and event if you can automate the updating of that A record to the new IP address there is still the real possibility that there will be transient issues due to the DNS TTL, propagation, and caching. It is possible that these transient DNS mechanisms could even prevent your passive node from starting up properly which I’d argue negates this being an HA solution in the first place.
If you do have stretched L2 networks between the sites then this is much less of a discussion because you can avoid the need to change the IP of vCenter Server as well as the DNS record during a failover. Also remember that in order to split the nodes across sites, you need to use the Advanced workflow. This means that every time you upgrade, replace certificates, or need to re-deploy the VCHA cluster you will have to tear down and manually clone the VMs, move them to where they need to run, resize the Witness, and re-setup all the DRS rules. It’s a lot of work so just be aware of what you’re getting into up front.
There does happen to be one scenario where I think splitting the VCHA nodes across different sites can work, though. If you are running stretched cluster or vMSC then you’re setup much better for VCHA. L2 connectivity between the sites is a requirement for stretched clusters as well as stretched storage. This makes it much easier to get the nodes where they need to go and you don’t need to add in the complexity of an IP and DNS change. You can reconfigure your DRS rules so that the nodes are pinned to certain host groups on each side. But, you’ll still need to use the Advanced workflow in this scenario because you need a third site for the Witness VM and using the Advanced workflow is the only way to get the Witness to that 3rd site. The one exception is if you happen to have a third site which has stretched L2 from the other two sites. Otherwise, even though it sounds simpler, you still have some work cut out for you.
Conclusion
If you’ve seen me talk about this subject you may have heard me say this before, but it bears repeating. vCenter High Availability is a high availability solution and not a disaster recovery solution. This is evidenced by the fact that VCHA only protects vCenter Server and not the workloads or hosts being managed by it. There is also a fair amount of work to get VCHA setup to work across sites as well as additional operational effort to maintain it, e.g. having to use the Advanced workflow. When deploying VCHA try to use the Basic workflow when at all possible to make the solution easier to maintain and deploy. Protect vCenter Server within a site as you are much more likely to suffer a failure from hardware, network, or storage than a total site failure.
In part 2 of this series, we’ll talk more about some of the operational aspects such as backup & restore, patching, and upgrades to the VCHA cluster.



")







