

by: VMware Lead Application DBA Jino Jose, VMware Sr. Enterprise DBA Yadukula Chengappa, VMware Lead Application Administrator Gopala SK, and VMware Sr. IT Manager Lincu Abraham
Embarking on the multi-cloud journey comes with its own set of challenges and VMware, as an organization, has always been at the forefront of helping its customers with their multi-cloud journey and discovering multi-cloud solutions for them. VMware IT faced a similar challenge when they started this journey for its customer-facing services.
The challenge
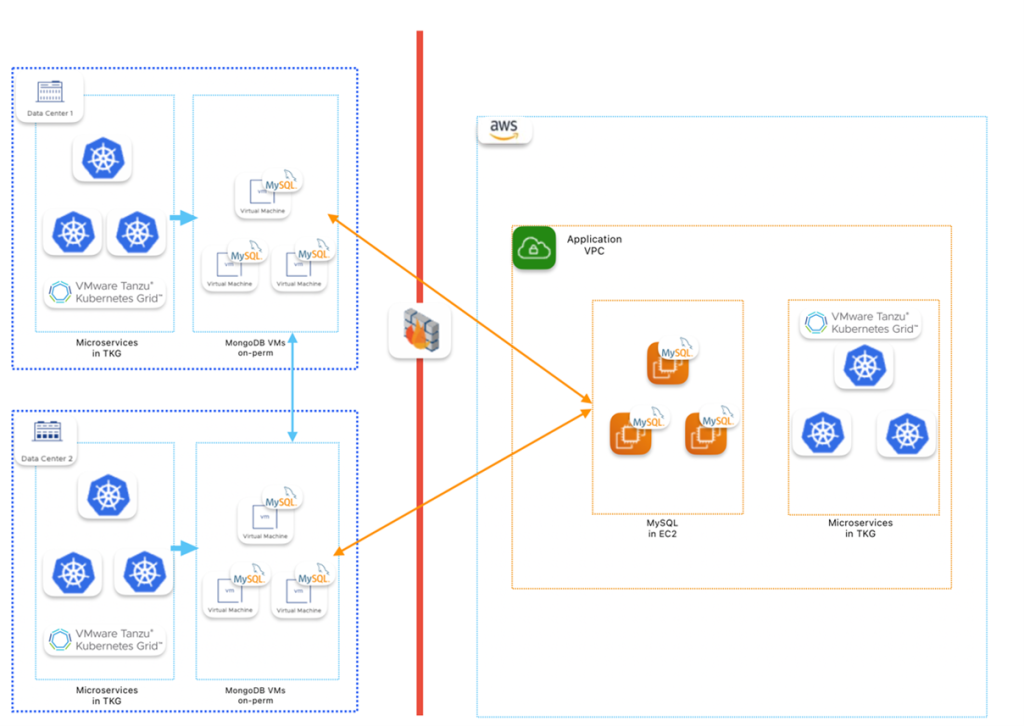
When we embarked on the multi-cloud journey for our customer-facing applications, one of our fundamental challenges was how to replicate databases hosted in our private cloud on VMs to the public cloud. The solution had to focus on high availability (HA), with the consistent tools and technology used on-premises, in a cloud-agnostic model. In on-premises, our applications were using microservices architecture deployed on the VMware Tanzu® Kubernetes Grid™, the VMware Kubernetes platform.
The solution
For databases running in on-premises VMs, there are two types: MySQL for RDBMS and MongoDB for Document Store or NoSQL. MongoDB is running as a replica-set cluster in two data centers providing failover capabilities in case of failures in the data center. For a third region (AWS), we decided not to extend the same cluster, but to use MongoDB Atlas, with Mongo Kafka connectors to synchronize data from on-premises.
This solution provided better resiliency since it is a managed service from MongoDB and has multi-cloud support. As the requirement was to replicate only a few collections and not the entire database, this was cost efficient when compared with the extended cluster option. AWS MSK service was used as the Kafka engine, while the connectors were running in EC2 instances. Since MSK Apache Kafka in combination with MongoDB Atlas was used, this same model will work with Azure or Google Cloud Platform (GCP) as Atlas is also available in those clouds.
The applications running out of Tanzu Kubernetes Grid in AWS can seamlessly connect to MongoDB Atlas via AWS Private Link, ensuring better security as the traffic stays within AWS. An isolated cluster in Atlas also provided better flexibility in version control and no code or driver change from an application perspective. Since Kafka connectors use change data capture (CDC), proper operations log (oplog) sizing must be maintained and any operation, such as index creation must be performed separately.
For any write operation when the AWS data center is active, the applications will make use of AmazonMQ, a fully managed service for open-source message brokers. The shovel feature of the RabbitMQ cluster is then used to send messages back to the on-premises RabbitMQ. This data consumed and written to on-premises MongoDB and Atlas will eventually be consistent.

For MySQL, we used Tungsten Multimaster (active-passive) clusters to provide a cloud-agnostic solution for high availability. For on-premises, both data centers had independent Tungsten clusters in a multisite/active-active topology, providing all the benefits of a typical data service at a single site but with the added benefit of replicating the data to another data center.
Tungsten cluster uses the Tungsten replicator, which enables bidirectional operation between the two sites. For the multi-cloud requirement, we enabled AWS as the third site. This ensures that data writes can also be handled provided data conflicts are avoided with offsets. Running in AWS EC2 made sure that the same can be extended to any public cloud of choice. Since the microservices that used MySQL as a data store were running in the Tanzu Kubernetes Grid platform with VMware NSX® Advanced Load Balancer™, there was no need to make code or drivers changes, providing a consistent experience, regardless of the cloud or on-premises.
The Road Ahead
We moved one of the most critical SaaS applications with this model and plan to move more SaaS and customer-facing applications. This model can be easily ported to any public cloud of choice, in line with the VMware multi-cloud SaaS journey.
The topic continues to evolve, so contact your account team to schedule a briefing with a VMware IT expert to hear the latest. For more about how VMware IT addresses queries related to modern apps, check out more blogs on the topic. For other questions, contact vmwonvmw@vmware.com.
We look forward to hearing from you.

VMware on VMware blogs are written by IT subject matter experts sharing stories about our digital transformation using VMware products and services in a global production environment. To learn more about how VMware IT uses VMware products and technology to solve critical challenges, visit our microsite, read our blogs and IT Performance Annual Report and follow us on SoundCloud, Twitter and YouTube. All VMware trademarks and registered marks (including logos and icons) referenced in the document remain the property of VMware.


