

by: VMware IT Director Sarita Kar, VMware Director of Observability Services Jois Raghavendra B P and VMware Sr. Manager of Observability and Tools Ravishankar Rao
Beyond improving cloud infrastructure capabilities and optimizing costs, multi-cloud plays an extensive role for an organization in the world of ever-advancing technology. And that’s why building and maintaining multi-cloud or rather running Day 2 operations and monitoring all the applications becomes extremely critical. Let’s see how VMware monitors all its applications in the multi-cloud.
Monitoring strategy at VMware
VMware Director of Observability Services Jois Raghavendra said that in light of our SaaS transformation journey, our strategy is to ensure end-to-end observability of all our revenue-impacting services. Observability, a key topic of discussion in the IT industry, is the second most discussed topic after Kubernetes regarding a cloud-native computing foundation. Here’s why: just like the VMware SaaS transformation journey, most major organizations are going through one or another type of transformation, and IT sees its share of this.
In the era of business systems with multi-cloud, multi-tier, and complex architecture, IT teams are handicapped without observability. Plain monitoring was okay when critical business systems were hosted in data centers with a monolithic or relatively simple architecture.
Newer systems are containerized with microservice architecture hosted on hybrid or multi-cloud environments, which requires end-to-end observability.
The focus of observability is to understand the health of the system as a whole, not merely individual parts of it. This also means that observability can’t just be achieved by external monitoring tools; it requires instrumenting our systems to externalize their state with which we infer system behavior.
Difference between observability and monitoring
VMware Sr. Manager of Observability and Tools Ravishankar Rao explained that VMware Monitoring is more of a reactive stance and a failure-centric activity while observability is more of a behavioural analysis regardless of incidents; monitoring will tell you whether a particular system or service is working as expected or not. See Figure 1.

Monitoring will tell you if something is wrong, while observability will tell you what is wrong, where and possibly why (root cause).
In simple terms, observability encompasses monitoring. It is more about the ability to observe the system at any given point in time. The intent is to have an accurate “state” of a service or application in real time, be it healthy or unhealthy.
How VMware executed observability strategy
We must understand that observability can’t just be achieved by external monitoring tools. It requires instrumenting our systems to externalize their state. To achieve this, we needed a fundamental mindset change, including:
- Shifting up from infrastructure/application-centric monitoring to business-centric monitoring
- Enabling end-to-end traceability for business flow transactions
- Developing a culture of observability that is front and center, starting from the architecture design phase rather than as an afterthought.
Traceability is one of the pillars of observability—logs and metrics being the other two—that we were missing and needed to install in our coding standards. This helped us introduce the concept of “observability-driven development.” See Figure 2.

The bottom line is that it’s all about collaboration. Every component in the business stack must emit what we call, “current-state” metrics. And it’s an evolving journey.
Role of VMware solutions in executing the observability strategy
- First, we needed to understand that there is no single solution that fits all; hence we must approach observability on a case-by-case basis. Each service and its dependencies must be instrumented to achieve true end-to-end observability.
A key factor in enabling observability is the ability to identify or map out dependencies. We use VMware Aria Operations™ for Networks that performs a flow-based auto discovery.
- We then rely on Aria Operations™ for Logs for event logging, which gives us an immutable, timestamped record of discrete events that happen over time.
- Third, we need metrics. The key aspect here is to consider the “metrics that matter” for a specific system. For example, an application transaction dashboard on a streaming analytics platform like VMware Aria Operations™ for Applications (previously VMware Tanzu® Observability™ by Wavefront) that shows where in the flow or transaction there is an issue.
These metrics from disparate systems are collated into VMware Aria Operations for Applications. Internal application metrics are also integrated via traces. We now have a centralized platform that provides a holistic view of the ecosystem and its inter-dependencies.
Further deep-dives may be carried out in the respective solutions (VMware Aria Operations™ for Logs, VMware Aria Operations™)
Challenges faced while putting observability in the multi-cloud
VMware IT is at a unique juncture. We have workloads running on both private and public clouds, as well as in traditional data-centers, and regardless of the platform, they need to be observed holistically. Apart from that, there are situations where services are in the process of being migrated to the cloud, and we need to observe those in flight.
Another key challenge is related to legacy systems, in which vendor support may be void if any customization or modifications are made, such as installing an agent or probe, modifying configuration, unsupported tech versions (older Java versions). See Figure 3.

Today, apart from the multi-cloud complexity, we have microservice-based applications that are containerized, and observing all these is not a trivial exercise due to their transitional state.
And there are more challenges in the form of infosec regulations, compliance, locked-down operating systems, and hardware-based network devices, where we cannot really install or configure anything, but still need to observe.
Overall, we have not quite achieved full-fledged observability. It’s an evolving journey, in which we continue to ideate and collaborate with various teams.
Factors to consider when choosing tools monitoring/observability tools
We first deconstruct the application stack behind a service that needs to be observed and the possibility of monitoring it with the current set of tools and solutions.
We don’t shy away from looking at external vendors if our solutions are not comprehensive enough for the need. See figure 4.
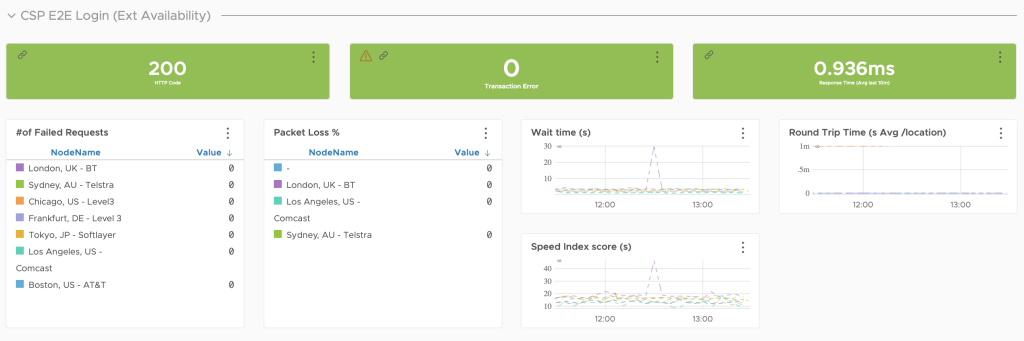
Further, we have a dynamic onboarding process that checks:
- Where the service is deployed (on-premises, cloud, container).
- If the tool is running in disaster recovery mode.
- What type of datastore the tool uses.
- If there are compliance requirements.
- Most importantly, the total cost of ownership and overall value proposition.
Be it vendor procured or our own product, every tool continuously evolves. So, onboarding a tool does not mean we are married to that solution forever; the assessment and evaluation process happens continuously.
Future for observability
Self-healing and self-remediation are logical next steps, determining if the tool or solution can evolve into self-healing is important. But we still have a long way to go in achieving true end-to-end observability.
As we evolve, more and more adjacent functions, like change-control, code check-in metadata, incident, payload data, etc., are becoming a part of the observability landscape.
The end goal is to have the ability to observe a system holistically and be in-sync with the dynamics of the system itself, and this must be achieved in a non-intrusive way.
The journey is to move from being reactive to becoming proactive, with the vision to be “predictive.” VMware IT is currently somewhere in the middle.
To be predictive requires AI ops on top of observability. With all the metrics, traces and logs correlated, the future looks bright for the VMware SaaS transformation journey and our solutions in this space.
This topic continues to evolve, so contact your account team to schedule a briefing with a VMware IT expert to hear the latest. For more about how VMware IT addresses queries related to modern apps, check out our modern apps and multi-cloud blogs on the topic. For other questions, contact vmwonvmw@vmware.com.
We look forward to hearing from you.

VMware on VMware blogs are written by IT subject matter experts sharing stories about our digital transformation using VMware products and services in a global production environment. To learn more about how VMware IT uses VMware products and technology to solve critical challenges, visit our microsite, read our blogs and IT Performance Annual Report and follow us on SoundCloud, Twitter and YouTube. All VMware trademarks and registered marks (including logos and icons) referenced in the document remain the property of VMware.


