

by: VMware Application Developer Dinakaran Ramadurai
Is it right to use the public cloud to back up your infrastructure that is also running in the public cloud? What could happen to your business if your vendor’s infrastructure became compromised, even though it is rare?
For organizations who use cloud for some, or all their business needs, the solution is to use on-premises backup for in-cloud infrastructure and data. On-premises backups are those in which a copy of data is saved to in-house storage devices.
On-premises backups have several clear advantages over trusting everything you own and protecting data compared to cloud vendors. The best practice is for an organization to evaluate its system and then implement a secure backup, archiving, and recovery solution.
Why back up data on-premises?
- Data backup is not optional: a business should be able to continue working on its data and attachments if the cloud vendor’s application is down, no matter the reason.
- Any business can suddenly shutter underperforming units and even close their doors when the economy turns and everything goes off the rails.
Advantages of data backup
- Low monthly cost: on-premises backup solutions are usually more cost-efficient than cloud-based services.
- Security: despite cloud solutions being exceptionally secure in almost all cases, using an on-site, end-to-end encryption solution means that data is not sent over the Internet and stays secure behind the firewall. This does not mean your data is invulnerable.
- Machine learning: can apply machine learning techniques and customized operations to data to get statistics.
Notable points on backup
- We must ensure frequent data backup as we must have the most recent data on-premises. The frequency can be decided based on business needs and application criticality.
- We must encrypt the data at rest, in the database, and attachments in storage areas.
Challenges
- How can we connect to Salesforce to get data?
- How can we copy data from Salesforce with attachments?
- Where can we save Salesforce attachments?
- What happens when an error occurs when downloading an attachment from Salesforce?
- How can we perform data archival/data clean up?
- How can we always show data with required attachments in the front end?
- How can we generate powerful reports based on huge amounts of data without making use of large resources?
Our approach
IT used several VMware products, such as VMware Tanzu® Observability™ by Wavefront, VMware Tanzu® Kubernetes Grid™, VMware vRealize® Log Insight Cloud™ and VMware Workspace ONE®. See Figure 1.
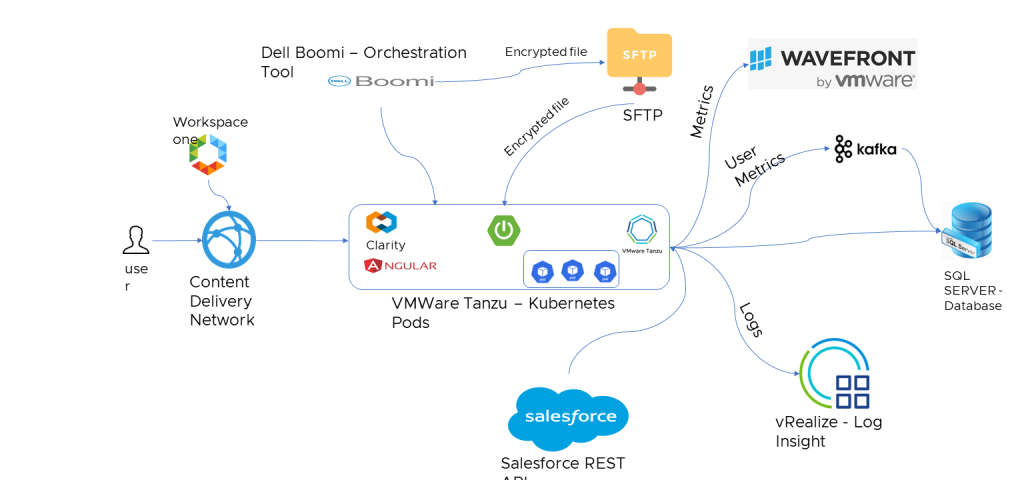
Figure 1. Architectural diagram of how IT automatically backs up data on-premises.
Other infrastructure components
- Salesforce REST API: we used Salesforce REST APIs (Standard API + Custom API) to fetch data from Salesforce.
- Dell BOOMI: acts as an orchestration tool that pulls data from Salesforce and places it in a staging database through spring boot rest APIs. It also downloads the attachment from Salesforce, encrypts it and stores it in secure file transfer protocol (SFTP), updates the path of the record in database so that it can be downloaded through angular front end when Salesforce application is down.
- Spring boot: exposes rest APIs to save salesforce metadata into an SQL server, saves attachment path, gets SOQL queries, saves error record IDs, allows front-end APIs to view and download Salesforce metadata and reporting APIs.
- Angular: to see the Salesforce metadata, with attachments, through front end developed using Angular and Clarity design systems. It also allows us to design with the same look and feel as Salesforce.
- VMware Tanzu Kubernetes Grid: we deployedspring boot and Angular pods in Tanzu Kubernetes Grid, which runs across data center, public cloud and edge for a consistent, secure experience.
Design details
- Database design: We used a staging database to maintain consistency of data. This allows only records with associated attachments downloaded, encrypted, and placed in SFTP location to enter the main database. Boomi inserts the data into the staging database, spring boot validates it and transfers it to main database.
- Data load: We divided the load into two: history load and daily load. In history, we load the data from 120 days (about 4 months) before, up to today (decided based on the business requirement and can change anytime) in a batch of 10 days record. The batch is split based on the last modified date of each record. In daily load, we run the load from the last successful data time to current data time.
- Error handling: We maintained the error table. If some error happens during a load, the record ID is loaded into the error table with table name. Once the daily load is completed, we run the process again for error IDs after investigating the issue.
- Data archival/clean up: Once all the load is completed, it will trigger the job that will clean up the data older than 120 days (based on business requirement) with the attachment associated with it.
- Data encryption: All the attachments stored in the SFTP server are encrypted using PGP encryption.
- Authentication and authorization: We used VMware Workspace One for application authentication and authorization. We have service token authentication for Dell BOOMI Integration and JSON Web Token (JWT) authentication for users. Salesforce REST API uses OAuth2 authorization (token-based authentication) through connected apps. SFTP is connected through passwordless authentication (using a private and public key with passphrase).
- CDN: Reporting is one of the most powerful features required in the backup tool. Since we are dealing with huge amounts of data, reporting is challenging with limited resources. Caching the report in CDN helps to reduce the report processing time and provide a seamless experience to users downloading the report.
- High availability (HA): We deployed the application across two mirrored data centers. We also added a mirrored database that takes a backup every five minutes.
Monitoring and observability
- Monitoring: We used VMware vRealize Log Insight Cloud for monitoring the container logs.
- Metrics: We used VMware Tanzu Observability by Wavefront to provide in-depth monitoring of the applications running on Tanzu Kubernetes Grid.
- User Metrics: We used Kafka to track user metrics, such as the number of reports generated by specific users. See Figure 2.
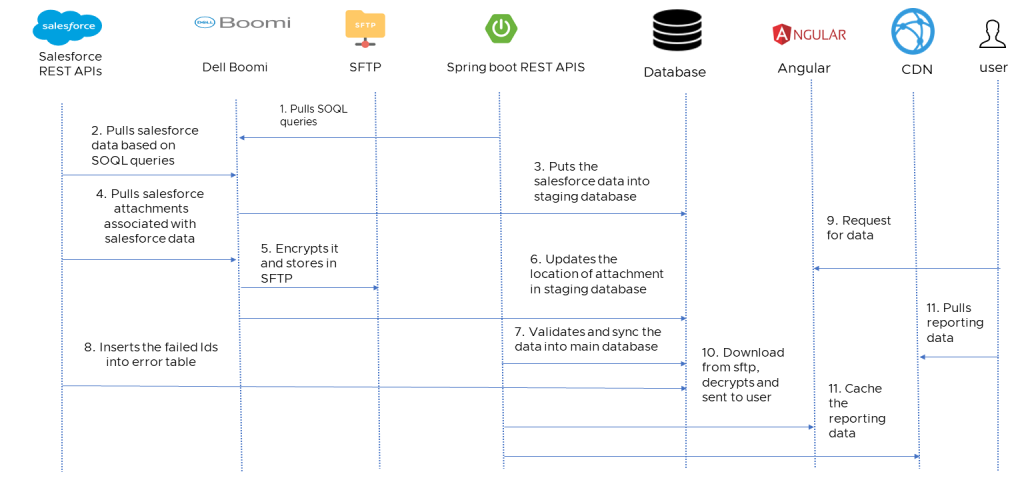
Figure 2. Flow diagram
Accomplishments of the design
- VMware IT can back up .2 million records from Salesforce.
- VMware IT can transfer nearly 200GB of attachments to on-premises.
- Using CDN cache, VMware IT can pull .1 million data in less than a minute
- We can be able to work on data and attachments, even if the cloud solution is down for any reason.
Future enhancements
Replace SFTP with Dell S3 buckets: Dell s3 buckets support streaming APIs allowing us to stream large files in chunks on demand, instead of downloading and sending the entire file.
We also plan to use Kafka between Dell Boomi and Spring Boot REST APIs.
VMware on VMware blogs are written by IT subject matter experts sharing stories about our digital transformation using VMware products and services in a global production environment. Contact your sales rep or vmwonvmw@vmware.com to schedule a briefing on this topic. Visit the VMware on VMware microsite, read our blogs and follow us on Twitter.


