

by: Technical Staff Member Sayali Kulkarni, Site Reliability Engineer Alexandra McCoy, Site Reliability Engineer Feargus O’Gorman, Site Reliability Engineer Brendan Winter, and Engineering Manager James Wynne
Have you ever used a product that was continuously unavailable or experienced numerous outages? Most of us are familiar with the story of the out-of-service ice cream machines at McDonald’s. It happened so frequently in many locations that it became a social media meme. It seems that the only place bad press is actually good press is on reality TV.
Similarly, when a company produces and sells a product, that product is a representation of company, its brand, and its reputation. It is then extremely important to ensure that companies maintain a solid understanding of their target audience or consumers to understand expectations and how to meet customer needs. At VMware, we take a similar approach to ensure we are always considering our customers and communities we affiliate with.
This is where the VMware Tanzu™ software-as-a-service (SaaS) reliability enablement (TSRE) team comes in. The TSRE Team is a group of globally dispersed site reliability engineers (SREs) who work to determine the reliability of applications and platforms, as well as the processes and operations used to support them. The short version is our site reliability team is a group of engineers that support the internal VMWare SaaS engineering team to help improve reliability practices by using service-level indications (SLIs) and service-level objectives (SLOs) at the foundation of our SRE layer. Providing this enablement for our internal teams ensures we remain customer-centric when building and offering VMware SaaS products and services.
We support our engineering teams through project-based work that impacts multiple teams, which isn’t always easy. Working in an environment such as ours requires a lot more than technical expertise. It requires being:
- Detail oriented
- Effective communicators
- Collaborative
- Leaders who own and drive projects to success
- Naturally curious
Our team is small, so it’s a requirement that we can move together with urgency and minimal guidance. In fact, we’d argue that the less guidance you need the more successful you are likely to be. But you must top it off with communication and collaboration skills, which encompass core VMWare values and strategic goals.
We support our SaaS teams through a series of technical projects that align with each other in order to measure our SaaS services’ reliability through metric-based dashboards. Our team focuses on the following:
- SLIs, SLOs and error budgets—to internally measure our reliability
- Infrastructure management—to manage tooling and hardware that supports our ability to measure reliability
- Incident management—to align alerting, monitoring, and incidents with capturing customer experience
Each of the projects we work on falls into one of these workstreams. They work together to quantify and present a holistic view of how reliable our services are for respective customers.
SLIs and SLOs monitoring and alerting
The original goal of the team was to implement SLO dashboards for VMware Tanzu® SaaS services that reported customer-centric reliability using SLIs. The team created executive dashboards for the VMware Tanzu® Mission Control™ and VMware Tanzu® Observability™ by Wavefront programs, which include top-level SLIs (representing the most customer-impacting service workflows for the overall service) and service-level SLIs, which are at either the individual component or microservice level. See Figure 1.
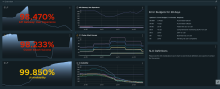
Tanzu Observability suite
The Tanzu Observability suite is a terraform module that allows teams to create simple, opinionated SLO dashboards and SLI-based alerts. The TSRE team uses the suite to
create, manage and destroy Wavefront for Observability charts, dashboards, and alerts.
Currently, the TSRE team is at a crossroad—where it is a good fit for Tanzu Mission Control and Tanzu Observability but needs further development to be more generally exploitable by any Wavefront user. The concept of Tanzu Observability as code is extremely valuable and could be the start of the next generation of observability tools.
Probe controller framework
The TSRE Probe Controller Framework is a standardized means to create user journey probes to measure service SLI. Using the probe controller framework libraries, complex probes can be created and deployed as containers to measure service availability. Existing probes can also be wrapped to create containers that use the framework. The benefit of the framework is that it provides a standard way to feed SLI data into Tanzu Observability. In conjunction with the Tanzu Observability suite, this allows the simple creation and management of SLI dashboards.
Incident management
The incident management workstream was established to improve the incident management process for SaaS engineering teams.
What’s next?
Our next blog will address why Tanzu Observability as code is extremely valuable in today’s world of technology and illustrate how it has benefited us as a globally dispersed reliability engineering team. Contact your sales rep or vmwonvmw@vmware.com to schedule a briefing on this topic


