

by: VMware Database Architect Charlene Huang; VMware Director, IT Applications Development Jerry Li; and VMware Director, Cloud Infrastructure Operations Zaigui Wang
In this two-part blog, VMware IT shares its perspective on its goal of one hour of downtime for disaster recovery (DR) failovers within the enterprise. The first blog explores the IT management perspective on why limiting the impact of DR is critical to any enterprise. The second blog (below) explores IT’s current DR environment and the valuable lessons learned.
When VMware IT first undertook disaster recovery (DR), the business requirement was to fail over and run the production SAP application on our DR site for one weekend every quarter. Because of our virtualized environment, we turned to VMware Site Recovery Manager (SRM), which provides automated orchestration and non-disruptive DR testing for all protected applications. SRM has a proven record of success in many VMware virtualized environments and would streamline our implementation because it was already integrated with vSphere, vCenter, NSX, and other VMware components.
We began by capturing some high-level requirements for our SAP DR plan:
- Production and DR would be at two different data centers, with a 500-mile separation.
- We would stretch our layer 2 networks across the sites so that our workload could be failed over and back without needing an IP change. VMs would retain their IP addresses as they move from Production to DR site and vice versa.
- SRM, already integrated with vCenter and vSphere, would orchestrate the actual DR process to ensure the process was automatically executed and the clusters were brought up in the correct order.
- We needed to be able to validate both infrastructure and application changes that could impact the DR plan without disrupting Production.
- The DR test would occur quarterly, and the applications need to run the business workloads at the DR site over a weekend.
- The Production data had to be replicated to the DR site within a business-accepted SLA.
The DR Process

The DR process was intuitive to set up once the requirements were finalized, and architecture was established. The DR infrastructure was quickly installed, and the sites were paired. Then the protection groups and recovery plans were built. The application administration team provided the custom scripts to check the dependencies and enable the databases and applications can start and follow the right sequence after the VM reboot. We used a six-step process, with the majority of the work being completely automated by the default configuration of SRM.
- Execute pre-failover checklist
- Initiate automatic failover of clusters by SRM
- Validate infrastructure at DR site by admin team
- Validate IT and business functionality
- Run workload at DR site for approximately 24 hours
- Fail back to Production site
Ensuring a smooth failover and failback, especially for mission-critical systems, was essential. But automation does not guarantee that everything will execute perfectly as business requirements and the infrastructure change constantly. On-demand bubble testing was our solution to testing changes without affecting Production. Testing happens up to three times a week compared to the quarterly failover.
DR Bubble Testing
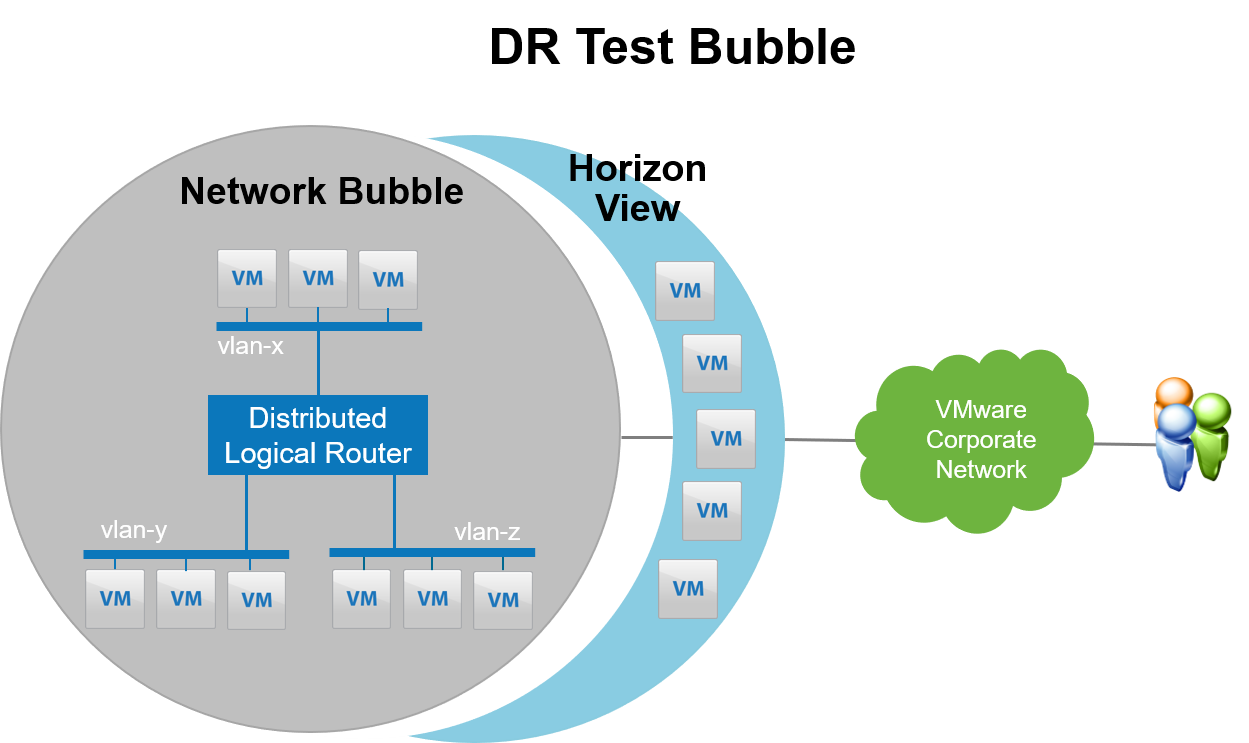
Our DR test bubble provides an isolated and complete test environment for us to validate the DR process in between, and right before, our quarterly DR tests. The test bubble is built on top of SRM’s test bubble network feature and enhanced with NSX logical networks to provide connectivity across multi-tiered applications. All production networks are recreated on the DR site using NSX logical switches (aka “virtual wires”) and the virtual wires are attached to a distributed logical router (DLR) to enable routing. The DLR is not attached to any edge device to allow traffic to leak out of the bubble and disrupt our production environment. VMware Horizon View is also deployed to enable test users to connect from their desktop devices and complete the tests as needed.
This DR solution is both clean, streamlined, and robust. By automating much of the process, we reduced our RTO (recovery time objective) to under three hours. Our target is to reduce our RTO to under an hour. We will update our readers as we evolve to meet this goal.
Read about VMware IT’s DR strategy in this blog.
VMware on VMware blogs are written by IT subject matter experts sharing stories about our digital transformation using VMware products and services in a global production environment. Contact your sales rep or vmwonvmw@vmware.com to schedule a briefing on this topic. Visit the VMware on VMware microsite and follow us on Twitter.


