
During a recent customer visit to discuss an application modernization project, I was treated first hand to an Enterprise-level handling of a CI/CD tool outage. While the development team at this European Financial Services firm did eventually manage to bring this tool back online, in the end it took more than a week to get the system back to a point where they could resume their standard operating processes with expected delivery velocity.
During this week, the team was unable to deliver any new code. Bugs went unfixed, and feature delivery timelines were pushed. While the specifics of this story are unique to this organization— there are broader lessons to be learned from this experience. And upgrading to a more modern CI/CD toolchain might have helped mitigate this outage.
The tool in question that caused this delivery outage was a very popular, very widely used CI/CD platform. The monolithic and stateful architecture of the tool meant that it needed to be continuously backed up, and ultimately treated as a “pet,” to bring up an older but still relevant metaphor.
This development team ran their own instance of this tool (and still does, despite this failure), as all development teams at this firm do. Meaning this firm had (and still has) dozens of instances of this tool throughout their development organization. And each of these teams is operationally responsible for keeping their instance of the tool up to date, backed up, and functioning, along with all other tools the teams also uses.
Is this starting to sound familiar? Perhaps even at your current firm? If so, this post may help you avoid some of these pitfalls. Hindsight being what it is, we'll take a retrospective look into the signs that this failure was imminent, and why it went unnoticed. Then we will look at some ways you can mitigate the risk of this frustrating and costly event happening to you. Or perhaps it is time to move to a more modern CI alternative, like Concourse CI.
Sign #1—Your CI Platform Has Become a Snowflake
Often times, when tools have been around for long enough, they build up a layer of what I like to call “config cruft.” This cruft is not the core usefulness that your tool provides, but instead it is all of the one-off configuration options, plugins, or other solutions that were added to solve corner case problems—and then promptly forgotten about. Over time this cruft can turn your otherwise lean, mean, CI machine into a complicated, delicate snowflake. As was the case for this team.
Their tool used a plugin architecture. Over time this particular CI tool instance had accumulated hundreds of plugins, installed to cover everything from integrations with docker containers and Kubernetes, to user notification systems and RBAC controls. All of these need to be independently configured, managed, updated, and backed up.
To be fair, this CI tool does provide mechanisms for performing these activities. An internal backup utility will handle backup and restore on a regular schedule (with some scripting), and an update utility will walk through the update of both the platform itself, as well as the plugins. However, all of these powerful features require someone to own their operation—not just to set them up once, but to continuously test (particularly the customizations) and ensure functionality. Which brings me to my next point.
Sign #2—There Is a Lack of Operational Ownership
Ownership, in this case, means more than just signing up as the responsible party. It means actually performing the tasks. In this case, even though the team was responsible for their own tooling, no one was actually performing these duties. Their backup routines had broken long ago, and none of the configurations were stored anywhere outside the platform. The team had kept up on patch releases, but were several major versions behind what was available.
This zero-ownership problem meant that when this tool went down the team had little recourse. After days of trying to recover files from the downed server, the team resigned themselves to recreating everything from scratch. This tool had been in operation for years. It had been loosely managed by many team members—most of whom were no longer with the firm. The existing team had to undergo an archeological dig to uncover and try to understand past decisions. And with such a complicated system, this was a time-consuming, slow process. Which in turn, brings me to my final point.
Sign #3—Flexibility Has Turned Into Complexity
This financial services firm chose this particular tool for many reasons, but a major one was its flexibility. Since it was to be deployed to all development teams throughout the organization, they needed a tool that would fit everyone’s use case. But they would learn that selecting one “flexible” tool for the entire organization also has its costs.
In this case, the team had implemented good agile practices some time ago—pairing, retrospectives, and the like—in order to avoid information silos. Yet even with these practices implemented, this team still lacked effective information sharing around their CI platform because no one understood it effectively. They were facing confusing plugin configurations. Pipelines were written in multiple different languages calling scripts that had to be recreated since neither were backed up, nor held in a source control mechanism. Flexibility had become a landmine of complexity for this team.
To recover their CI function, the team had to come together, put all other work aside, and recreate the intricacies inherent in their system. They had to do this work instead of advancing their own applications. And they realized that once the tool was back up and running, the technical debt would start adding up all over again if they didn’t change their practices.
This team was eventually able to pull off this small miracle and get most of their system back up and running—the rest sacrificed on the altar of experience. They now have a dedicated developer rotation for all of their tooling to make sure things are running smoothly, and everyone gets a chance to learn. They are even training other teams how to avoid these costly mistakes.
This is the easiest lesson to take from this post: continuously evaluate your practices, identify risks, and if those risks are not within agreed upon thresholds—work to mitigate them. That said, it may also be time to simply reevaluate your choice of tooling. What was a reasonable decision years ago, like using a popular monolithic app to run your builds, may no longer be today. It may be time to look at a modern alternative to these traditional CI systems.
What’s the Modern Alternative in CI Systems?
Concourse CI was born from the need of a cloud-native developer. While developing Cloud Foundry, a project spanning tens of thousands of developers, and hundreds of separate projects, the teams quickly came upon limitations of scale with conventional products. Lack of configuration consistency, managing team access, complicated upgrade paths, and lack of available options in the market led to the formation of the Concourse CI team. This team built Concourse for the large scale, distributed, high-performance development teams working on Cloud Foundry. And they kept several key practices in mind.
Concourse Is Stateless
With Concourse, state is managed differently from traditional, stateful CI systems. Core functionality is distributed between stateless nodes, while internal state configuration is managed via a separate, standard PostgreSQL instance. In the event of a tool failure, this allows Concourse to be stopped, removed, and restarted easily.
External state is managed similarly to traditional CI systems, except that in Concourse the external resource integrations are also managed in pipelines. This takes the place of a plugin-based architecture and allows teams to run new pipelines quickly and with minimal, if any, tool configuration. (More on the architecture of Concourse can be found here.)
Managing failure is not the only benefit of this stateless architecture. Decoupling the tool data from the tool allows for the possibility of zero downtime upgrades. Additionally Concourse can be scaled to allow for high-availability configurations to further reduce the risk of downtime.
When your tool fails (and it will) how are you going to recover it? Or, if deployed on a platform like Kubernetes, will you even notice when it does?
For example, here I will delete the Web node pod in Kubernetes, and Kubernetes automatically recreates and restarts it. Since the Web node is stateless, there is hardly a blip in the UI.
First I will list the pods. The pod in question is joyous-olm-web-598fb4ddbc-msnbr.
av@av-kube:~$ kubectl get pods NAME READY STATUS RESTARTS AGE joyous-olm-postgresql-587d899bf-tpgsz 1/1 Running 0 6m joyous-olm-web-598fb4ddbc-msnbr 1/1 Running 0 6m joyous-olm-worker-0 1/1 Running 0 6m joyous-olm-worker-1 1/1 Running 0 6m
Then I tell Kubernetes to delete the pod…
av@av-kube:~$ kubectl delete pod joyous-olm-web-598fb4ddbc-msnbr pod "joyous-olm-web-598fb4ddbc-msnbr" deleted
…and list the pods again. We see here that the pod is already being recreated.
av@av-kube:~$ kubectl get pods NAME READY STATUS RESTARTS AGE joyous-olm-postgresql-587d899bf-tpgsz 1/1 Running 0 8m joyous-olm-web-598fb4ddbc-l9mq4 0/1 Running 0 6s joyous-olm-worker-0 1/1 Running 0 8m joyous-olm-worker-1 1/1 Running 0 8m
A few seconds later and one more listing of the available pods and the web node has been recreated while the GUI had no perceivable downtime.
av@av-kube:~$ kubectl get pods NAME READY STATUS RESTARTS AGE joyous-olm-postgresql-587d899bf-tpgsz 1/1 Running 0 8m joyous-olm-web-598fb4ddbc-l9mq4 1/1 Running 0 12s joyous-olm-worker-0 1/1 Running 0 8m joyous-olm-worker-1 1/1 Running 0 8m
Concourse Is an Opinionated CI Platform
The flexibility of traditional CI systems is both a gift and a curse. More flexible pipeline implementations allow for multiple methods to accomplish just about any task, but at the cost of more complex, less readable code. The solution to this problem is to use less complicated, more opinionated tools.
Concourse uses a declarative pipeline syntax that is easy to understand. Pipelines and external resources are defined in YAML. And while not everyone is a fan of YAML, a key quality it does have is that it is easy for just about anyone to read and write. There is even an extension for VS Code that will help you along the way!
Concourse pipelines include three basic primitives: resources, jobs, and tasks. This opinionated nature of Concourse pipelines enforces more consistency and good practices. Once you understand the principles, you can build a pipeline, as well as read and understand others. And when paired with the pipeline visualizations in the Concourse GUI, even complex pipelines become intuitive to understand.
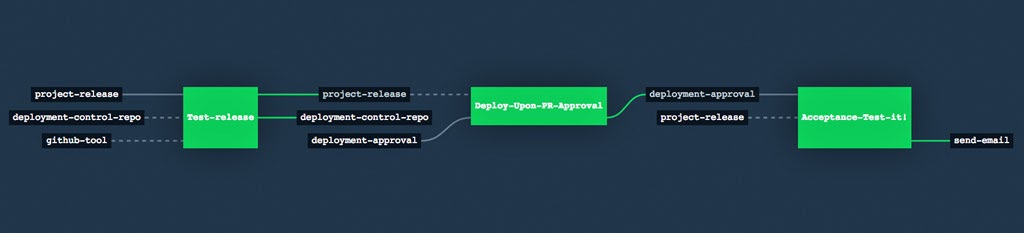
Concourse Build and Test Pipeline
Concourse GUI makes visualizing the status of any job its primary focus. This means in the event of a job failure, developers can see at a glance which job failed and why. This allows the team to find and resolve issues fast. The developer can then retrigger the job from the GUI with a click, or from their laptop with a simple Fly command.

Concourse Pipeline Dashboard
And if you don't want to log into Concourse to track your job status, Fly will show all the run logs on the local CLI with a flag. For example, here we are going to watch a recently triggered pipeline, courtesy of Stark & Wayne, and watch it complete.
av-kube:job-inputs av$ fly -t concourse-lab watch --job simple-app/job-test-app Cloning into '/tmp/build/get'... a3edcb3 restrict mkdocs packages until can make time to upgrade https://ci2.starkandwayne.com/teams/starkandwayne/pipelines/concourse-tutorial/jobs/website-master/builds/32 Cloning into '/tmp/build/get'... b55bfe1 switch to dep initializing waiting for docker to come up... Pulling golang@sha256:220aaadccc956ab874ff9744209e5a756d7a32bcffede14d08589c2c54801ce0... sha256:220aaadccc956ab874ff9744209e5a756d7a32bcffede14d08589c2c54801ce0: Pulling from library/golang 8e3ba11ec2a2: Pulling fs layer 8e6b2bc60854: Pulling fs layer 3d20cafe6dc8: Pulling fs layer ... 61a3cf7df0db: Pull complete ec4d1222aabd: Pull complete a2fb1cdee015: Pull complete Digest: sha256:220aaadccc956ab874ff9744209e5a756d7a32bcffede14d08589c2c54801ce0 Status: Downloaded newer image for golang@sha256:220aaadccc956ab874ff9744209e5a756d7a32bcffede14d08589c2c54801ce0 Successfully pulled golang@sha256:220aaadccc956ab874ff9744209e5a756d7a32bcffede14d08589c2c54801ce0. running resource-tutorial/tutorials/basic/job-inputs/task_run_tests.sh ok github.com/cloudfoundry-community/simple-go-web-app 0.002s succeeded
Concourse Has Teams
The team structure within Concourse allows organizations to scale a single Concourse instance across all development teams, while still maintaining team independence of structure and practices. Rather than distributing instances around your organization that must then be managed independently by each team, a single Concourse instance can keep things separate where they need to be (like pipeline configs, repos, and team structures) while integrating at the platform layer. This means platform level changes like upgrades, patches, or credential changes can be centralized, performed once, and automatically rolled out to each team.
Onboarding a new team, or team members, is incredibly easy as well. Simply create the new team by running the fly set-team command. Users can be added to that team within that same command. More complex team structures can be defined in YAML (which can then be managed within a source code management system), and applied to Concourse CI. Done! Your team is ready to start building pipelines.
And the fly CLI utility isn’t just for setting up teams. It’s a powerful tool which allows developers to build their pipelines locally, and apply to Concourse CI without ever logging into the interface. One simple command loads the pipeline into your Concourse testing environment, where builds run exactly as they will in production, and that same command, slightly modified to target your production Concourse instance, will load that pipeline into your production workflow.
To Deploy To Test
av-mbp:~ av$ fly -t [test-concourse-environment] set-pipeline -c [pipeline-yaml-file-name] -p [pipeline-name]
To Deploy To Production
av-mbp:~ av$ fly -t [prod-concourse-environment] set-pipeline -c [pipeline-yaml-file-name] -p [pipeline-name]
Easy as that!
Concourse Integrations Are Provided Natively
In Concourse, system integrations are provided out of the box through a construct called Resources. Everything Concourse needs to run a pipeline is intrinsic to the pipeline YAML itself, which can then be managed using source control platform like Git. This allows for developers to get up and running quickly, even with complicated pipelines and on fresh Concourse installs.
resources:
- name: my-awesome-git-project
type: github-release
source:
user: anthonyvetter
repository: main
uri: https://github.com/anthonyvetter/awesome-project.git
Example Resource block in a pipeline YAML
For example, in the above snippet, this tells Concourse to monitor a branch of my GitHub project for a new release. When there is a new release posted, this will trigger a job in Concourse to, for example, test this app version and ready it for eventual deployment.
There is nothing internal to Concourse that understands external resources. And that’s a good thing! Go ahead, give it a try!
Ready to Re-evaluate Your CI Tooling?
In agile teams, we are always looking for ways to continuously improve and evolve our practices with the end goal of delivering better software to our users, faster. If your teams are developing cloud-native apps, consider a tool that’s purpose built for the job. Consider Concourse CI.
For more detailed getting started guides and information, see the Concourse CI docs, here.
For information regarding other Concourse use cases beyond CI, as an open-source continuous thing-doer, see how Concourse can patch your PCF instances, how to develop custom resources, customer testimonials, or learn about the history of Concourse, and where it’s going!
A big thanks to Patricia Johnson and Ben Wilcock for their help with this post.









