
Getting a new AI agent to production introduces significant complexity to the software development and delivery cycle. Enterprise developers need secure, compliant access to many services and resources including Large Language Models (LLMs), Vector Databases, Agent Registry, Conversation Memory, a Message Bus, and more. Access to these services that also enables integrated security and governance capabilities can be achieved more easily with a platform like Tanzu Platform with Tanzu AI Solutions.
Tanzu’s core tenets can be summed up with this freshly updated haiku:
Here is my source code
Connect my AI model
I do not care how
This is to say that we are continuing our commitment to helping customers build and deliver agentic apps to production quickly and safely just like any other app!
In this blog we will discuss how and why you can expedite your agentic app delivery with Tanzu Platform through on-demand access to AI services.
Agentic Apps with Tanzu Platform
Tanzu Platform accelerates the delivery of secure, and higher quality software with a streamlined path to production with governance, observability, and secure integrations. With Tanzu, platform engineering teams can curate an experience that provides development teams the tools they need to go from prototype to production quickly and securely, while reducing toil, making it the ideal platform for agentic apps.
The architecture shown below demonstrates how Tanzu Platform can be used to build, deploy and manage AI enabled apps and connect to different AI services.
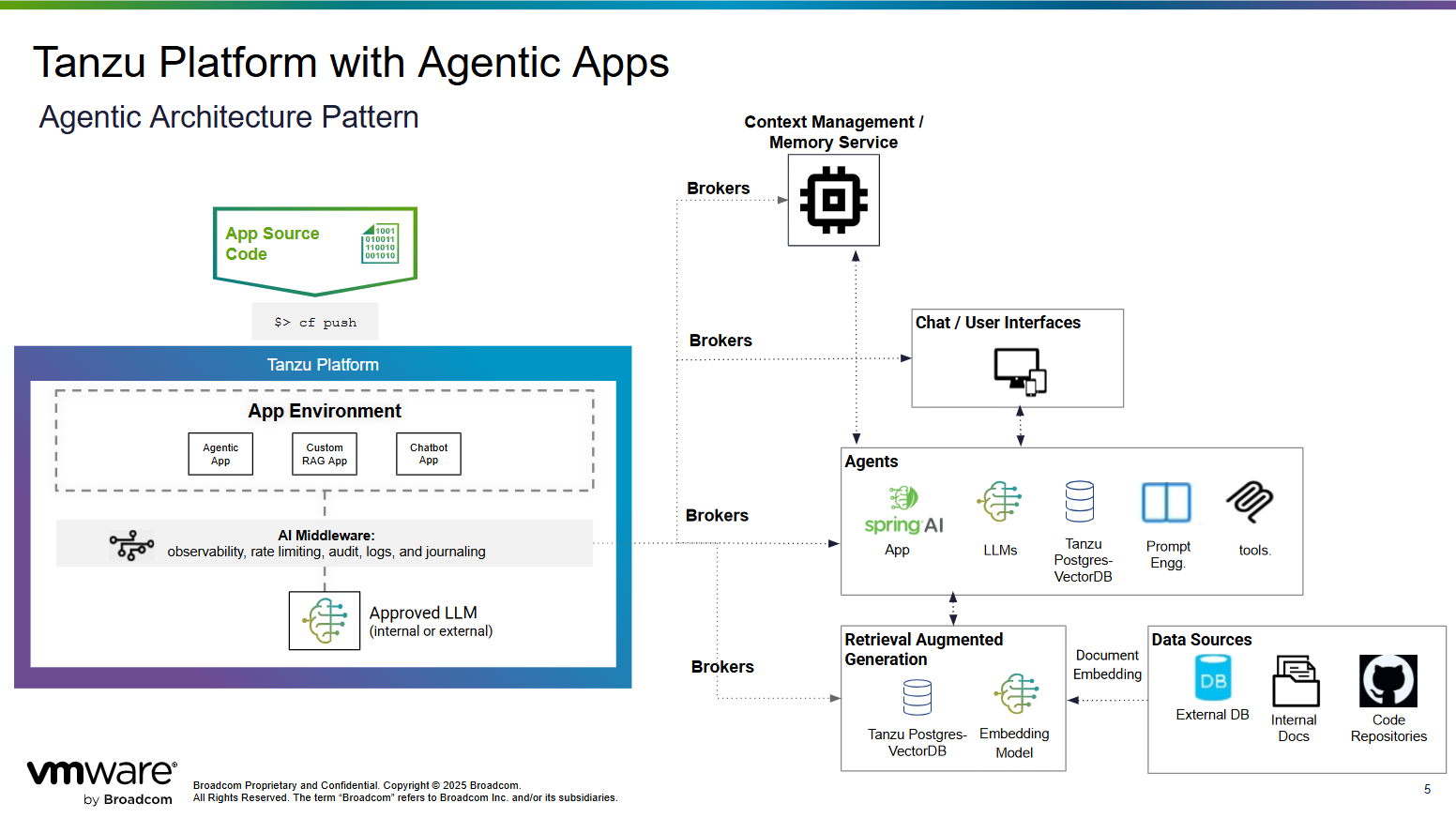
Fig 1. Tanzu Platform Agentic Architecture
Streamlining Agentic Applications Path to Production
Developers can easily build and deploy AI-powered applications using Tanzu Platform with its streamlined “cf push” workflow. These applications can be connected to a range of Generative AI services—such as chatbots, Retrieval Augmented Generation (RAG) systems, AI agents, and long-term memory capabilities—using Tanzu Cloud Foundry’s native service broker architecture. Tanzu Platform offers on-demand access to these Gen AI services, allowing developers to stay focused on coding rather than managing infrastructure.
These AI services typically require access to foundational and large language models (LLMs). Enterprises often curate a list of preapproved Gen AI models to ensure they align with internal standards for security, performance, and compliance. Tanzu Cloud Foundry supports both public and private model deployments, offering access via a unified API endpoint, and reinforces governance through access controls and rate limiting. AI engineers and data scientists can deploy these approved models, integrate enterprise data, and continuously refine them for accuracy, making them readily available for developers.
Because these AI services are integrated through a service broker pattern, they are inherently scalable, updatable, and easy to monitor. Tanzu Platform also includes built-in observability, compliance, and lifecycle management tools, enabling platform engineers and operators to create secure, repeatable deployment pipelines without the need to manage the underlying infrastructure.
Overview of AI Services
Now, let’s take a deeper look at Gen AI services such as chat, RAG, AI agents, and memory services deployed on the Tanzu Platform.
Chat
Enterprises often need to offer natural language interfaces, like chatbots, that interact with internal IT systems. These chatbots rely on foundation models or large language models (LLMs) to function effectively. With Tanzu Platform, platform engineers and operators typically deploy a set of preapproved models. Developers can then connect their applications to these models through a simple service broker interface, without needing to manage infrastructure like GPUs, orchestrators, or runtime environments. This approach accelerates innovation by enabling quick access to trusted, enterprise-ready models, eliminating long setup or approval processes.
Choosing the right model, however, is a crucial step. One of the most efficient ways to start is with prompt engineering or prompt tuning, where developers fine-tune input prompts to evaluate how well a model fits their specific use case. It’s a fast, low-overhead method that can yield strong results without retraining the model.
Tanzu Platform makes preapproved models, such as LLaMA 2, GPT, or Gemma, available through APIs, allowing developers to quickly plug them into their apps. It also supports easy swapping of models for A/B testing or tuning, all in a modular and governed environment.
Behind the scenes, the platform is highly flexible, supporting multiple inference engines like vLLM and Ollama, and running on either CPUs or NVIDIA GPUs depending on your infrastructure.
Another benefit of Tanzu Platform is the ability to privately host large language models. This is essential for organizations concerned about data privacy especially given the number of cases of data leaks through public models. Keeping models in-house not only ensures tighter data control and compliance, but also helps manage cost. Public models charge per token, and the cost of long responses can escalate quickly, posing a serious challenge for production-scale applications.
Retrieval Augmented Generation (RAG)
Foundation models are very capable tools for understanding natural language, but are not themselves databases. In most applications the model is being asked to know things about organization data, such as financial reports or technical product manuals. The pattern that injects your current and domain specific information is Retrieval Augmented Generation (RAG). Rather than modifying the model itself, RAG enhances the model’s output by supplying it with richer, more relevant context. Instead of sending a standalone prompt to the model, your system first performs a vector search across your internal knowledge base documents, manuals, policies, etc. to find the most relevant content.
These documents are preprocessed by:
- Splitting them into manageable chunks
- Generating embeddings (semantic vector representations) using a foundational model, and
- Storing those vectors in a vector database.
At runtime, when a user asks a question, for example about a specific company policy, the system semantically searches the database, finds the most relevant document chunks, and attaches them to the user’s question before passing it to the language model. This additional context significantly boosts response accuracy.
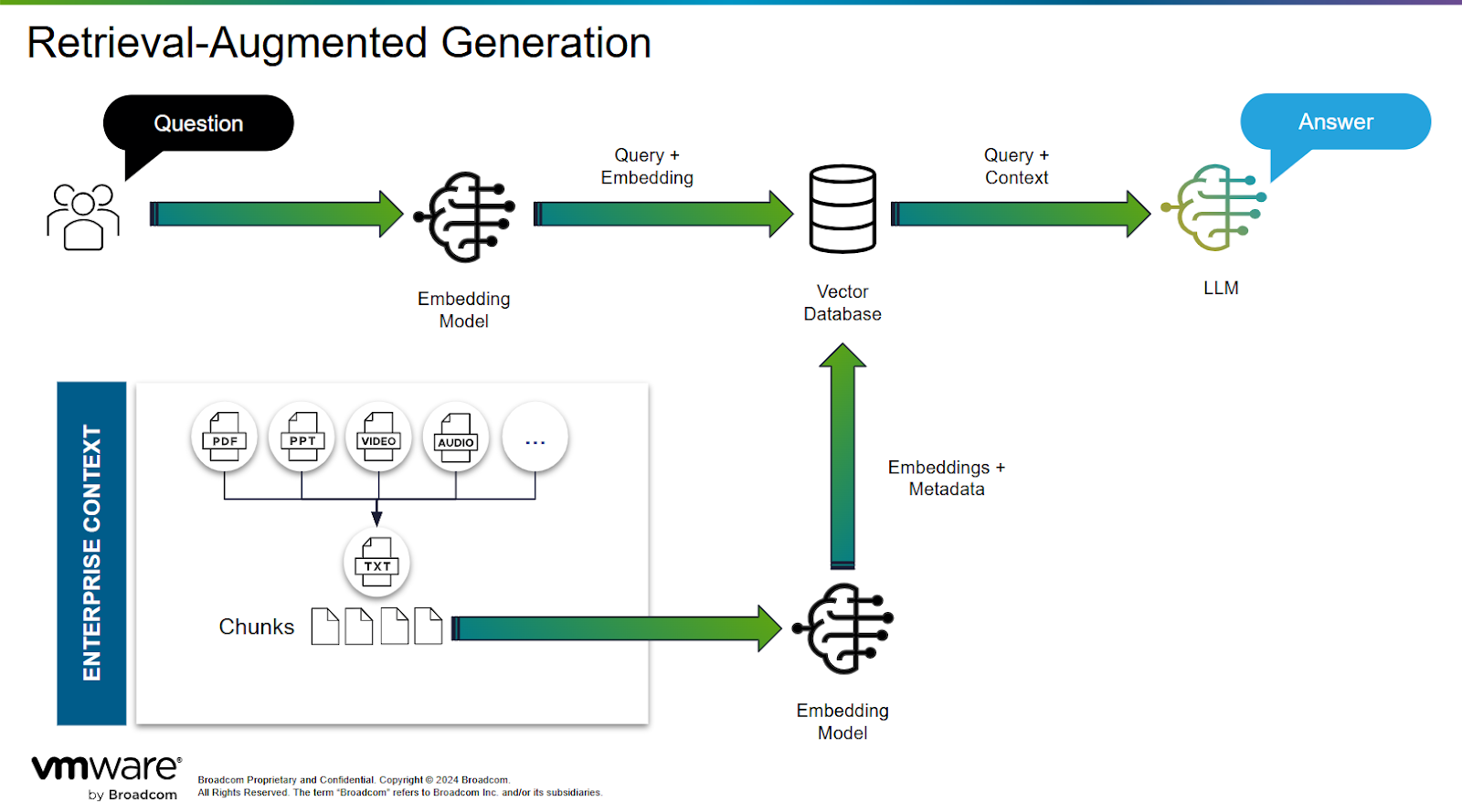
Fig 2: Retrieval Augmented Generation (RAG)
Tanzu Platform supports this RAG workflow by combining services like Tanzu Postgres for structured data and approved Gen AI models for semantic search and generation. With Cloud Foundry’s service broker model, these components can be easily provisioned and connected without complex infrastructure setup.
This setup enables the creation of natural language interfaces—such as chatbots—that can intelligently answer questions about your documents. For example, in a software company, a chatbot could help users navigate product manuals by querying a vectorized document database and generating clear, human-readable answers.
AI Agents
AI models are continuously improving, enhancing their reasoning capabilities and optimizing inference-time computation. Discussions around AI agents are gaining momentum, but questions remain, can these models be fully trusted? Are they truly effective? This challenge represents a “last-mile problem,” where significant back-office tasks and processes can still be automated, allowing people to focus on more valuable work.
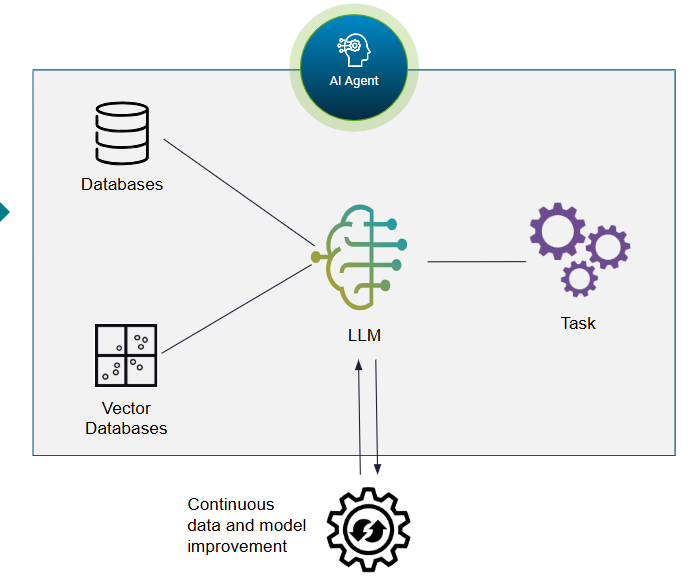
Fig 3. AI Agents
AI agents are structured blocks of code designed with reasoning capabilities. They leverage:
- LLMs for language understanding and decision-making
- Long-term memory via retrieval-augmented generation (RAG), vector databases, and graph databases
- Short-term memory for adaptability in dynamic contexts
- Task-specific training to optimize performance for designated workflows
- Integration layers that connect with enterprise applications and other automated systems
Model Context Protocol (MCP)
The AI landscape is evolving rapidly, but it’s highly fragmented. Each model provider has its own way of attaching tools, exposing different capabilities, and implementing unique frameworks for encoding rules and solving problems. This is why standardization through protocols is crucial.
The Model Context Protocol (MCP), created by Anthropic, is a model-agnostic approach that defines a universal interface for services. MCP enables AI models to interface with live software systems in a standardized way. If universally adopted, this will unlock powerful AI-driven automation and orchestration across various services, eliminating the inconsistencies in current frameworks and model implementations.
Spring AI added support for MCP in December 2024. Spring AI’s adoption of Model Context Protocol (MCP), and contribution of the official Java SDK for MCP, marks a major advancement in enabling AI integration with Java applications. As MCP adoption expands, the SDK will empower Java developers to seamlessly connect with a growing range of AI models and tools while ensuring consistent and dependable integration practices.
Tanzu Platform enables the building, deployment, and lifecycle management of agents. Because MCP agents can be deployed to Cloud Foundry, they will inherit platform-level capabilities like integrated authentication, secure connectivity to data services, scalability, and a safe path to production. In the architecture above, Model Context protocol server based agents are connected to an AI-powered application through service binding. The LLM (Large Language Model) connected to an AI enabled application dynamically selects the appropriate agent, to carry out the required task.
You can refer to the bitcoin MCP agent implemented using Spring AI as an example to understand how to build and deploy agents with Tanzu Platform.
Memory Service
This capability allows AI-powered apps to retain historical context, adapt based on previous interactions, and deliver more personalized user experiences over time.
The architecture for this typically includes:
- A Memory Service (either custom-built or native to the Tanzu Platform),
- Tanzu Postgres for persistent storage,
- An embeddings model to enable contextual search of long-term memory.
By offloading memory to a persistent backend, apps can “remember” user preferences, past conversations, or decision history without retraining models. Additionally, hosting memory and models privately helps reduce operational costs. Unlike public models that charge per token—potentially returning verbose, multi-line responses—private, memory-augmented systems offer better control over cost and performance, especially at production scale.
Tanzu Platform is your AI-Ready Private PaaS
Tanzu Platform includes Tanzu AI Solutions which enables organizations to deliver enterprise-grade, agentic applications. Agentic architecture represents the next step in application modernization, where AI isn’t just an add-on, it’s a key innovation enabler. Tanzu Platform provides a secure, private PaaS experience for building and deploying agentic apps whereas Tanzu AI Solutions helps you to build, govern, observe and optimize agentic applications over time.
By integrating GenAI models, RAG patterns, memory services, and automation agents directly into Tanzu AI Solutions in Tanzu Platform, we’re empowering teams to build faster, and with greater confidence as the platform handles the plumbing and operations. Tanzu Platform is the fast lane from model selection to application integration to real business value.
To learn more about the how Tanzu Platform supports your AI modernization efforts, check out these additional resources:
Video: What is MCP? How can you use it with CF?
Blog: VMware Tanzu Unlocks GenAI ROI for the Enterprise by Accelerating the Delivery of Agentic Applications
Video: What is AI Middleware? How to build AI-embedded applications with Tanzu AI Solutions
Interview: VMware ups Tanzu’s gen AI support, sheds Kubernetes dependence
Cloud Foundry Day NA 2025: Session Recordings







