


The Pivotal Data Science team often engages with customers who are in the initial stages of transforming into data-driven organizations. These customers many times know that there is significant business value hidden in their data, which they could uncover with the right mix of technology and best practices. They face challenges around the ‘what’, ‘why’ and ‘how’s’ of getting started on this journey. In these scenarios, we partner with our customers to identify the best problems to get started on and further enabling them to extract continuous value by combining and analyzing different data assets. In the following blog post, we describe a recent enablement-focused successful engagement with a global automobile manufacturer.
Personalizing the Driving Experience
In the modern era of disruptors like Tesla and Uber, large and established automobile manufacturers know they need to develop better, more personalized products and services to compete. This requires auto companies to use data and analytics to better understand their customers and driving behavior. For example, using sensor data automakers can program a vehicle’s software to adjust the internal air conditioning, window positions and seat inclinations automatically per a passenger’s preference. That is truly personalized service.
Data science at scale is the means for modeling sensor data to profile a customer in the auto industry. We were able to demonstrate this when an automobile manufacturer presented us with a challenging task to ‘profile and identify the drivers’ of their cars to personalize the customer experience. This required processing and analyzing large volumes of sometimes messy data. Throughout the engagement, we paired with the client’s domain experts to learn how they thought about profiling drivers and their driving habits to gain insights using sensor data and advanced machine learning tools.
Following our data science methodology, the main objective of the engagement was to identify drivers using currently available data related to:
-
Physical attributes of a driver (e.g. how tall or short the driver is)
-
Seat position/(s)
-
Rearview mirror positioning,
-
Moonroof/sunroof usage, etc.
-
-
Surrounding cruising environment (e.g. routes frequently visited)
-
Trip coordinates
-
Traffic news events along the journey route
-
Weather conditions, etc.
-
-
Driving behavior (e.g. how hard the driver brakes)
-
Acceleration usage
-
Steering directions, usage
-
Turn indicator usage etc.
-
Data Exploration
With twenty different car models of both ‘sold’ (a.k.a. customer) and ‘R&D’ (a.k.a. company) vehicles, we explored a data set of approximately one hundred thousand ‘trips’. A ‘trip’ includes two dimensions: (1) the distance covered between ‘on’ and ‘off’ states of a car’s engine and (2) the elapsed time between ‘on’ and ‘off’ states.. ‘Sold’ cars were instrumented with two sensors that capture trip data, which was then automatically uploaded at the end of each trip to a central database. R&D vehicles were equipped with more pre-production sensors, but their ability to collect data was hampered by frequent software updates. These updates were often untimely, managed by different R&D groups in the organization, and interfered with the accuracy of collected readings. In short, vehicle sensor data was non-standardized, varied in quality and was semi-structured.
We initially analyzed data representing trips taken by approximately five hundred cars in ten-plus different countries across the globe. We quickly realized certain features of drivers, especially identifying gender, was going to be extremely challenging, given the variety of individual drivers, similarity in characteristics of drivers, demographics, different driving laws and the variety of car models. Furthermore, there were only twenty cars with identified drivers. Out of those twenty, ten cars were single owned. Ten other cars were genuinely identified as multiple driver cars or cars shared by many drivers.
Approximately two thousand attributes per car per trip were obtained from sensors in the cars. With a goal to fully leverage the entire dataset, we developed a customer-centric view of the data to better allocate resources, provide customer-focused targeting, and forecast subsequent sales. In addition, data science labs helped the company better understand how data science can help optimize future sales and vehicle manufacturing pipelines.
We started the data science lab by first identifying and cleaning messy data early on in the data analysis pipeline. This step was further useful in enhancing the quality of software programs written to capture the state of a car, it’s environment and calibrate the operation of sensors used in production-ready cars.
There were plenty of data inconsistencies introduced into the central datastore during data collection from car sensors and data staging on data lake. For example, there were similar properties of a particular car model which were described under different names used in different languages. Properties referring to a particular car feature can sometimes hold conflicting values. Also, absence of vital car features during trips adversely affected data quality and trust. Another example is incomplete trips which were identified as having no meaningful beginning and end.
The data quality issues included, for example, certain trips with trip-ending-mileage lower than trip-beginning-mileage. These trips and cars were identified as having faulty sensor and/or faulty configurations. In the process, we also identified some company cars that were equipped with work-in-progress sensors that were spewing large quantities of unrealistic values and inconsistent feature statistics.
We developed various data cleansing PL/Python functions, mainly filtering techniques like Kalman filter, to reconcile multiple attributes from different sensors. We distributed data representing the operations of thousands of cars across a Pivotal Greenplum cluster to process in parallel. The customer was amazed by the in-database, parallel processing capabilities of Pivotal Greenplum, something they were not able to do with their previous data warehouse.
The customer had attempted such analysis before, but only in fits and starts. The customer was aware of data issues that they observed on samples of selected, highly-aggregated data set. Pivotal Greenplum helped the auto manufacturer’s engineering team see the entire analysis and understand all the facts and insights in their data.

Earth Center Earth Fixed coordinates in relation to latitude and longitude. Image via Wikipedia.
Feature Engineering
There were various data attributes that the customer had never previously joined together in a single analytics pipeline. One example of data that the customer had not used before due to pre-aggregation challenges was spatial data in the form of GPS readings.
In our next step of feature engineering, we created multiple temporal and spatial features. In any spatial analysis, the first step is processing GPS values of the moving objects. We converted the reconciled GPS recordings into ECEF (Earth-Center-Earth-Fixed) coordinates to help satisfy the laws of lateral movement in physics. This is specifically useful for very longer trips. We derived behavioral features like the rate of change, frequency, duration, moments and percentiles of mechanical features per trip per car.
While visualizing the spatial and temporal feature distributions, a unimodal feature space came as a surprise, mostly for cars driven by multiple people. But that validated our assumption that in similar geographical locations, climatic conditions and environmental constraints, driving behaviors were mostly similar. In other words, any person driving in a given geographical region would demonstrate the same average driving behavior. However, the distinguishing driving behaviors of an individual could only be observed in extreme or sparse driving events (e.g. high acceleration while merging onto a freeway.) . The most astonishing details were hidden in the tails of the distribution of the behavioral attributes. These sparse events captured the most interesting information that could accurately identify each individual driver.
Hence, we based our models on features derived from any differences in the tails of the distributions of various temporal and spatial features. We computed the probability density area over/under a threshold and chose a conservative threshold so as not to have too many zero values.

Area under the curve beyond a threshold.
Upon visualization, these new features showed separations feature space where multiple drivers are involved. For example, for one group of cars we observed one large density identifying the primary driver and several smaller densities identifying several infrequent drivers of the cars. Some company cars showed characteristics of 50 different drivers, which our customer later confirmed as true findings.
These features would enable the auto manufacturer to better target data engineering and manufacturing efforts for extreme events, thereby reducing uninformative data captured by multiple sensors for extreme events.
Model Building
For model building, we used unsupervised analysis as the appropriate analytics strategy, because only 0.04% of the vehicles had correctly identified primary and secondary drivers with correct physical attributes. We introduced our customer to new, scalable analytical tools, such Apache MADlib, an open source machine learning library. Apache MADlib has numerous machine learning and statistics algorithm implementations that leverage the underlying parallel infrastructure of Pivotal Greenplum. Using the procedural language extension functionality of Pivotal Greenplum, we were able to scale models written in open source machine learning libraries like scikit-learn. Together with the customer’s domain experts, we produced multiple models at different granularity levels, ( e.g.models per car, models across cars in a region, models across males in a region, models across females in a region, models cohort of trips, etc.) as well as independent models for the above mentioned feature categories to understand the desirability of different vehicle characteristics in each car model.
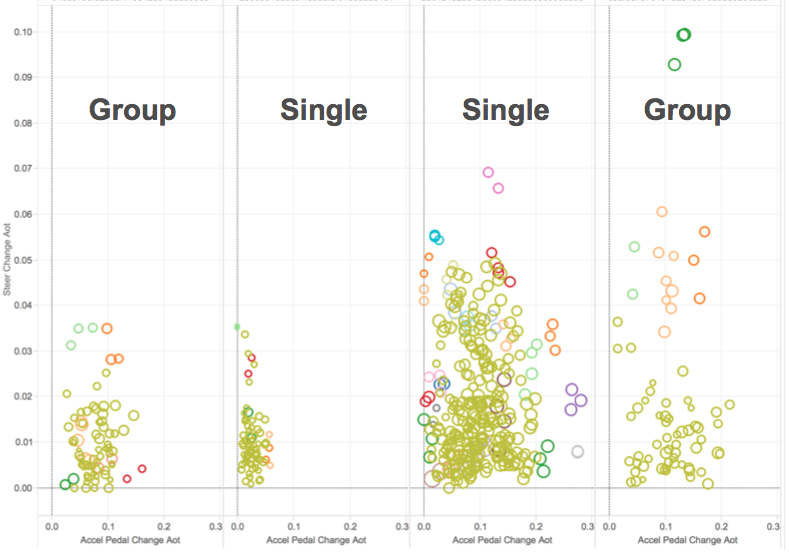
Distinct behavior in a group and single cars.
The independent clustering models gave us clues to the potential presence of multiple drivers. We sampled multiple single cars with both male and female drivers to identify distinctions between the driving patterns of both. For each car we also considered only those trips that were in the same dominant group of seat height positions and GPS start-end coordinates. This ensured the high probability of a singularly driven car. We were able to identify female drivers in some dominant clusters. Male drivers were present in all clusters. We observed male drivers with different driving styles with different car models.
We reliably identified trips undertaken between the same pair of start and end points by the same driver of any particular car. Trips not taken frequently (identified as outliers) could also be mapped to individual drivers. Also, data from different seat positions served as reliable proxies for the physical attributes of a driver.
Conclusions
Data exploration at scale not only helped the R&D teams identify the drivers but also helped them identify potential areas of improvements in their embedded vehicle and sensor software. Our models helped the auto manufacturer segment drivers with different driving behavior into categories with high sales potential. This will enable the automaker to focus appropriate efforts and resources on developing vehicle characteristics that consumers really want.
To summarize, by leveraging tools for data science and analytics at scale, such as Pivotal Greenplum and Apache MADlib, we worked with our customers to:
-
Summarize and visualize an extremely large and complicated data set and manage its various intricacies;
-
Process and analyze ‘poor quality’ data at scale using Pivotal Greenplum;
-
Apply advanced modeling techniques to drive sales in the right direction.
Pivotal Greenplum played an important role in transforming large volumes of data into actionable insights in this engagement. Interested in learning more? Check out the Pivotal Data Suite and more customer success stories on the Pivotal blog.








