

CJ ENM is a Korean entertainment conglomerate that produces dramas, award-winning movies, and reality entertainment. The business has produced and distributed more than 600 film titles, including the Oscar-winning “Parasite” and Cannes award-winning “The Handmaiden.” It’s also a major player in K-POP, animation, and produces musicals for Broadway, the West End, and Asia.
As an entertainment company, many of CJ ENM’s tech services are outsourced to affiliates, which creates a more complex operating environment. Let’s consider this ship as a service.

In order to keep on course, we need a variety of people with particular skill sets, but because they each do different things, it’s difficult to ensure uniform management of resources and tracking changes. That’s why we made the decision to operate this large ship we call Kubernetes ourselves.
First, we conducted Proof of Concept for all Kubernetes solutions we could find in our market.
Next, we looked to establish a container-based running environment. Here’s our story of how we streamlined our entertainment services with VMware Tanzu Platform.
Migrating to Kubernetes
To migrate to the Kubernetes environment, we focused on determining the appropriate size of the cluster as we conducted performance tests, and then we went through the process of operational transition. In this diagram, the cells colored in light green are the services we have migrated, which range from planning, production, distribution, marketing and advertising to commerce, data analysis and the ERP system.
There was a lot of trial and error over the course of the migration. with Tanzu Platform, these issues have been resolved with patches, and we have established an architectural configuration that we think is most optimal for us. This diagram shows the CJ ENM Kubernetes architecture currently in operation.
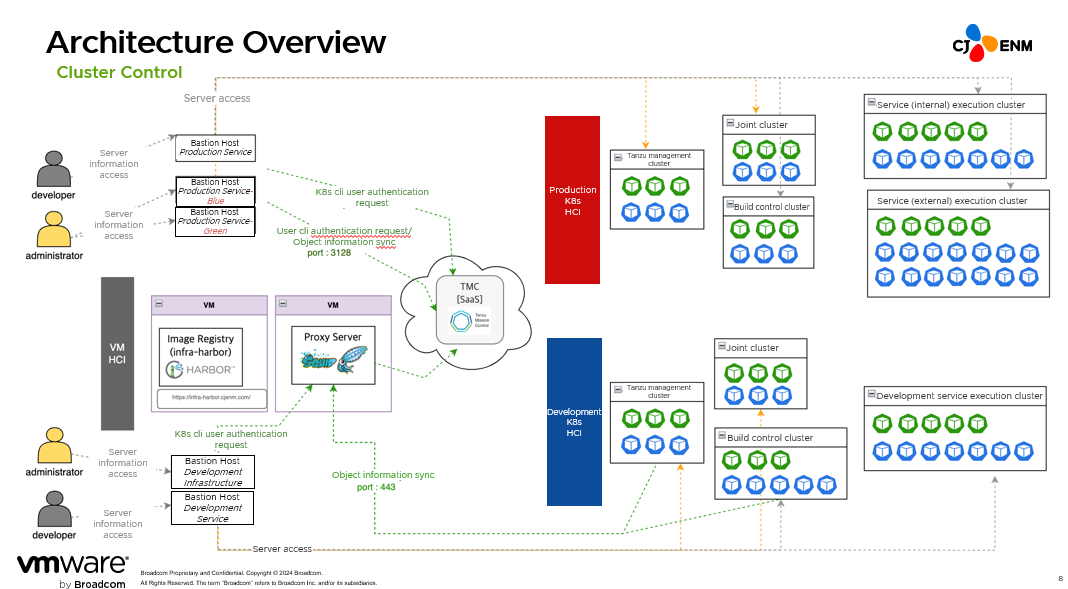
We have configured Bastion Host to handle Kubernetes. Initially, we only operated one Bastion Host to manage this cluster, but this created a risk of extortion of authority to access the infrastructure, so we now have separately operated Bastion Hosts for development and infrastructure.
Our company has a closed network for development. Therefore, for services that must reference external resources such as builds or Tanzu management clusters, we have configured a proxy server to enable outbound communication. Tanzu provides an installation guide for closed network environments, which simplified the work.
When we first set up Kubernetes, we tested rolling updates, but this created delays related to pod pending at specific worker nodes. For this reason, we formed a blue zone and a green zone and also divided the C class and set it in the same manner as the D class for firewall control to configure each zone. When we upgrade, the installation takes place in the green zone while the blue zone is taken down and vice versa.
When developers connect to the Bastion Host, we don’t want them to know whether the environment to which the pods are uploaded is a blue zone or a green zone, so we created shell scripts and configured the environment to enable them to check the active state of the blue and green zones and clusters for RBAC they access can be automatically set into shells.
In Kubernetes, there is a concept of Ingress. This means that, after coming in as a single VIP, services ultimately become separated with FQDN but all the internal resources are shared. That’s why we performed some work to separate clusters by service type. For internal services, we are able to predict the amount of incoming traffic, so we have organized it tightly whereas, for external services, we allocated more room.
We thought carefully about the appropriate size of worker nodes, and we tried to verify the size continuously through performance tests. We concluded that there will be no issues if we perform load tests as long as we leave the equivalent of 30% of available space of the services that are going to be loaded.
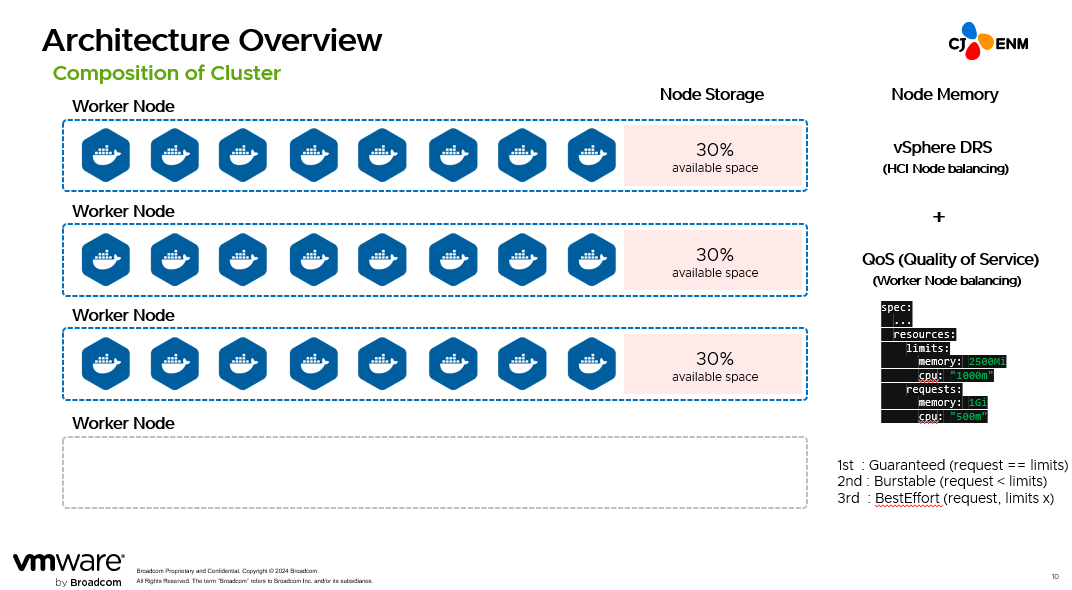
Memory
When we used a VM, we used to allocate 8 to 16GB. However, in Kubernetes, we used the monitoring analysis index of Zabbix and allocated the average index at the point of the highest peak in the particular service as its memory. Even so, there have been many instances of OOME.
We learned two things from the experience:
- When installing Tanzu for the first time, the DRS feature of vSphere must be turned on.
- In the process of generating loads, a worker node is a VM in vSphere, and this VM is eventually loaded somewhere in an HCI node. But this DRS disperses and balances worker nodes depending on the memory status of actual physical nodes, which made us think that DRS needs to be bigger for memory management in Tanzu.
Next is QoS. As the amount of memory use increases in a worker node, Kubernetes sequentially kills this memory. We set the request and limit of a resource, and if these two are set identical, they are designated Guaranteed, which means they are least likely to be killed.
One of the advantages of Tanzu is the fact that it can scale out to worker nodes and that it uses software load balancing, which we have tested as well. But we concluded that it is risky to increase worker nodes beyond a certain loading point. When we timed the addition of each worker node, we found that it took 12-15 minutes for each one. If too many are added, it leads to pod churn. For this reason, we established governance to detect memory or storage and expand it in advance.
Central management
The main reason we adopted Tanzu Platform was for central management. Whenever we create a container, we need to go through nine steps, and because we outsource the work, we need to train our developers on these steps.

Also, we needed everything from governance on docker files that can package manifest YAML or docker containers to solutions that can manage it all. And Tanzu has packaged this build using an open source called Paketo. So it allows us to only use JDK, OS and a library that we have announced and designated.
Tanzu packages everything by configuring OSI layers. As a result, developers don’t need to know about Kubernetes dockers. They can just write workload YAML to run a service. That makes it a powerful solution for businesses like ours that depend on outsourcing. All we had to write in a workload YAML were the name of the application, which supply chain to use, GitLab, repository, branch and Java tool option.
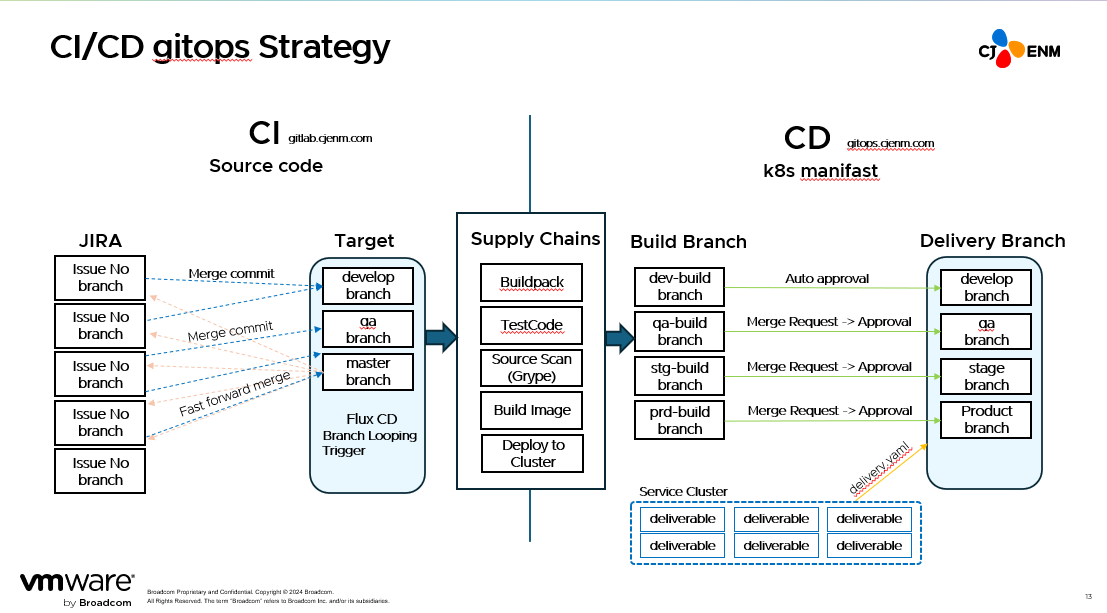
In the beginning, we only used a single Git, but as the load increase we experienced malfunctions. As we have had to deal with issues simultaneously occurring in CI/CD, we eventually separated the two.
For CI, we established governance by creating branches in the unit of SR by JIRA’s issue number and then merging them to the target side. Our affiliates all manage Git differently. If we incorrectly merged Git in the past, we could just reset or recover via cherry-pick, but in GitOps it would cause a malfunction.
Now, when we go to develop or GA in a JIRA issue, we do merge commit, but for master we make sure to use fast forward merge and squash, and once distribute is complete the issue branches that have not been distributed are rebased. Tanzu Build Service allows us to easily customize such pipelines.
We currently operate about five supply chains that suit our needs. For these, we aimed to distribute development and operation as quickly as we could. We’ve configured development to be distributed immediately without an approval process whereas operation requires an approval. Distribution without approval wasn’t provided in the Tanzu supply chain, but the Tanzu team customized it for us.
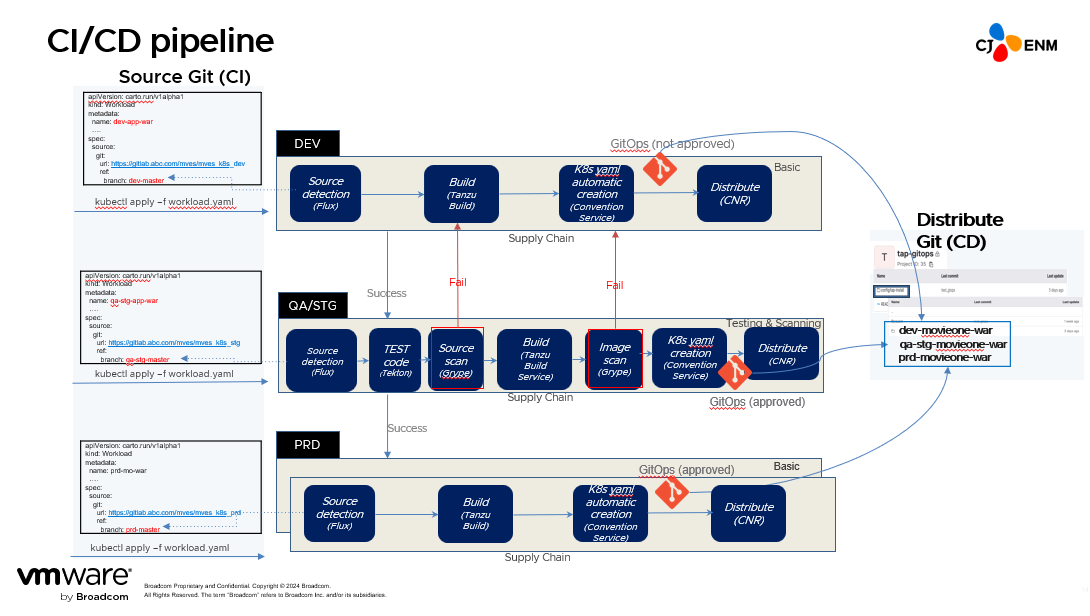
We wanted to create an environment in which developers can concentrate on ID tools, so we push and here for VS code or IntelliJ, plugins are offered. When using these plugins, everything from the overall build status to various resources can be seen in the ID tool. This is how we configured the environment. And after distribute finishes up to the stage, operation distribute occurs on the same day. So our pipeline enables a build to take place with the stage distribute and operation distribute tied together in the pipeline. Then, once stage confirmation finishes, operation distribute occurs within 10 seconds.
We have also set up an environment in which all managers need to enter via GATEON and the CLI that was entered in GATEON can leave all-in logs. In the beginning, we composed this RBAC YAML on our own. But there were cases where developers worked on several services at once. Our existing solution led to YAML contents becoming too lengthy and difficult to manage.
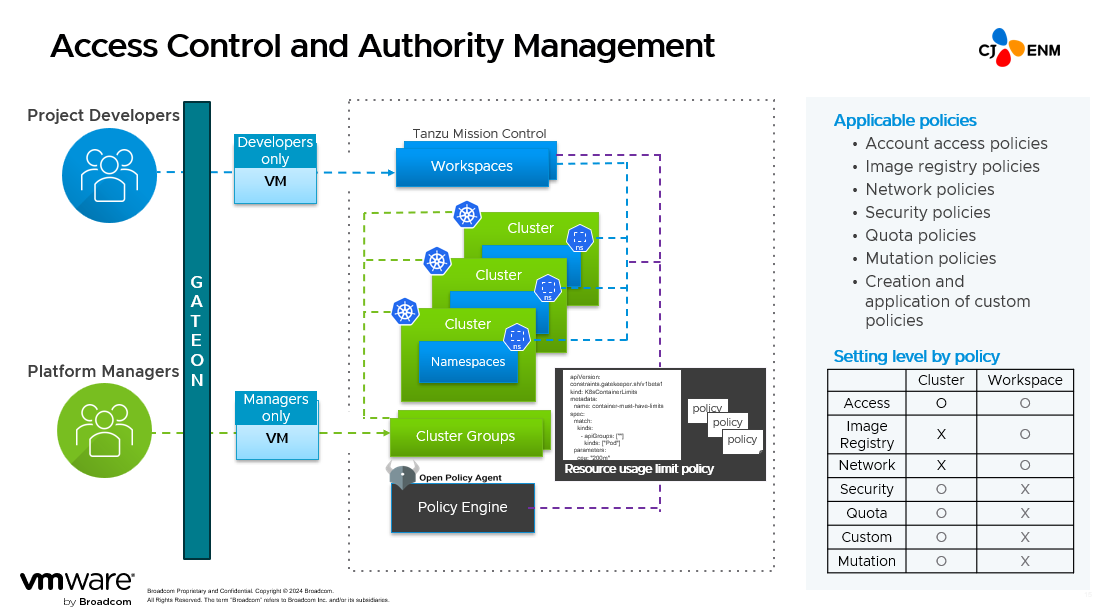
That’s why we started using Tanzu Mission Control. It has a feature called multi-tenancy, which ties such main spaces into a workspace for management. Now, we use this workspace to have separated namespaces in service units. We group these namespaces and assign a person in charge to each one. We have set up an environment that can manage over 100 of our engineers.
Monitoring
Tanzu is a solution created by packaging hundreds of open sources. We used GitOps for the purpose of central management and I’ve listed the major services of the open sources installed in Tanzu in order to configure this GitOps. But it was virtually impossible for us to monitor open sources listed under the build cluster, service cluster and common cluster.
To address this issue, we provide a piece of information called custom resource define. Here, if we check the status, we can perform complete monitoring of GitOps. But it is a custom resource, because there is currently no commercial monitoring solution available. We developed a way we can manage the metrics ourselves and connected monitoring to a commercial solution.
We also set up an environment that can send an alert through Webhook. Because this is GitOps, we need to send alerts for any push or merge on the CI or CD side. So we created a channel for each responsible service team and built the environment to send alerts even for any change in Git.
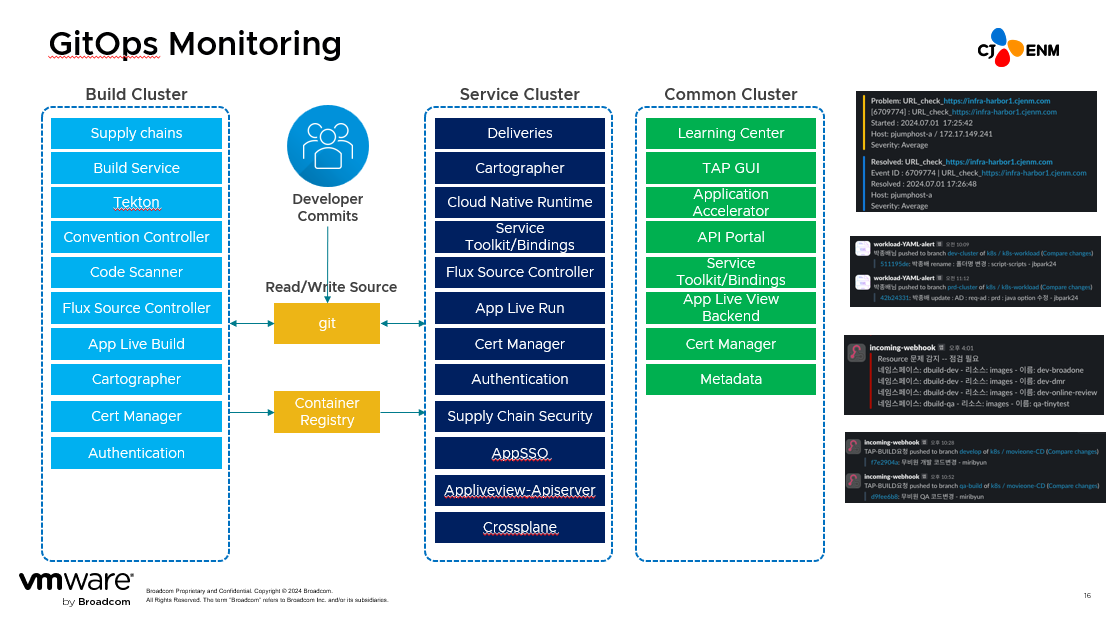
What’s ahead?
Our next goal is a hybrid cloud to cater to specific events. We currently have Kubernetes configured in a private cloud. But there are many services based on certain fandom platforms or services only provided at specific times and periods.
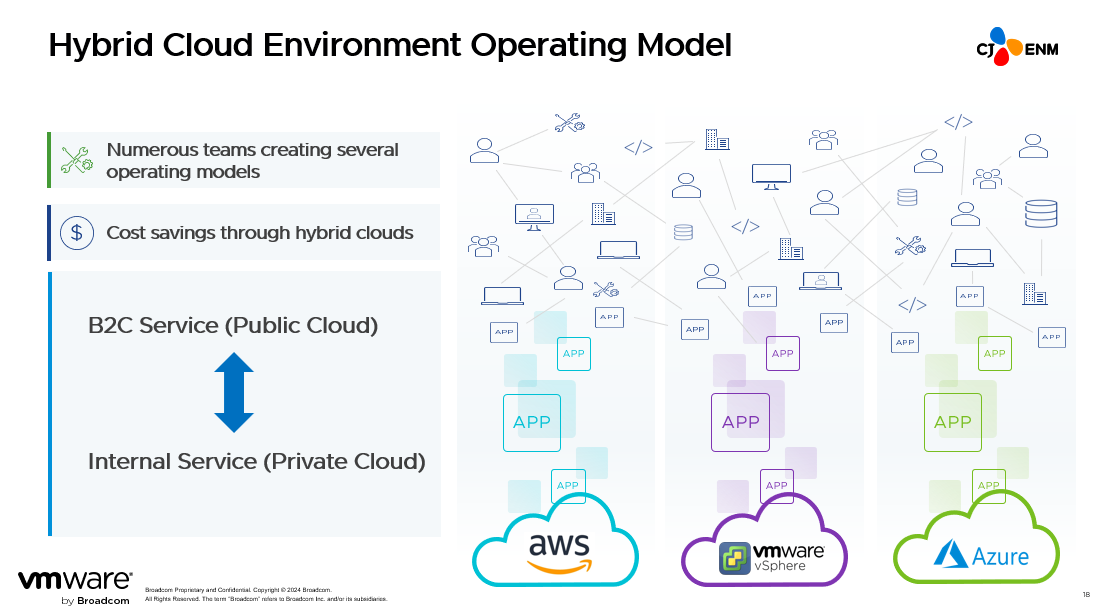
MAMA, for example, is a global event that attracts hundreds of millions of users for a few says, but almost no users once it ends. For services like this, we can move them to a private cloud when they are not in use and also put development and QA of the services that are out in public right now into our private cloud. This way, we can monitor their governance allowing us to continue to convert our environment to a hybrid cloud.




