
Tactics to prevent legacy software from slowing down innovation
This is an excerpt from the draft of “the second edition” of my Cloud Native Journey PDF. Check out the rest of the work in progress and tell me what you think!
Digital transformation is about rethinking those legacy business processes and doing stuff in a new way. –Marc Geall, SAP
I like to think of legacy software as any software you’re afraid to change, but must change. The exact age or technology of the system is less important than that fear of change. You fear changing it because you don’t have a reliable and/or trustworthy enough way to test if your changes broke the software, or other services that rely on the legacy software. If you have software that you have to change, but are happy to change, you usually just call that “software.” And, of course, if you don’t have to change the software, who cares?
When people talk about “dealing with legacy,” there’s usually four buckets of concern:
- Transforming legacy process — changing your approach for software creation and delivery.
- Revitalizing legacy code — fixing issues in your software, the code and the architecture, that prevent you from making changing as quickly and cost effectively as you’d like.
- Living with legacy — integrating with “legacy services” that you cannot change, at least change as quickly as your core software evolves.
- Avoiding legacy pitfalls — putting effective portfolio management in place to prevent getting saddled by legacy in the first place.
The first bucket is what much of the discussion in this paper is about: changing how an organization thinks about, organizes, and then executes on software as a whole. Let’s take a look at the rest of the issues.
Revitalizing Legacy Code
One of the more popular definitions of legacy code comes from Michael Feathers’ classic in the field, Working Effectively With Legacy Code: “legacy code is simply code without tests.” Most code will need to be changed regularly, and when you change code, you need to run tests — to verify not only that the code works, but that your new code didn’t negatively affect existing behavior. If you have good test coverage and a good continuous integration and delivery processes in place, changing code is not that big of a deal and you probably won’t think of your code as legacy. Without adequate, automated testing, however, things are going to go poorly.
Thus, one of the first steps with legacy code is come up with a testing strategy. The challenge, as Feathers points out, is going to be testing your code without having to change your code to make testing possible. Or, as Feathers summarizes:
The Legacy Code Dilemma
When we change code, we should have tests in place. To put tests in place, we often have to change code.
Feathers’ book is 456 pages of strategies for dealing with this paradox that I won’t summarize here. What I want to emphasize is that, until you have sufficient test coverage, you’re going to be hampered. In other words, this is one of those pesky prerequisites for being a successful Cloud Native enterprise.
If you code lacks good test coverage, and especially if you don’t have build pipelines in place, you likely won’t be able to fix all of the problems at once. This is especially true in a large organization. Gary Gruver, in Start and Scaling DevOps in the Enterprise, describes a process to incrementally tackling these problem while still moving towards the goal of thorough testing and build automation. Once you’ve introduced proper CI/CD you have a policy in place that stops failing builds from progressing down the pipeline; the product teams are responsible for making sure the builds don’t break, the tests pass, and their code integrates with the rest of the system. When bringing in new code, you can’t test everything at once, so instead you choose some key build acceptance tests (BATs) as a starting point for increasing test coverage. As you find failures in the build and integration, you write more BATs around those failures. These failures may be in the code, the infrastructure, or elsewhere. The point is, as you discover problems, you stop everything, write a test, and fix the issue.
Coupled with the code level changes Feathers describes, this long, trying process of building out your build pipeline tests allows you to discover what needs to be tested and build up the confidence in your test coverage to start making changes more fearlessly.
This type of work is tedious and can be disheartening. But if you want to improve how you do software, proper test coverage of your code and automation thereof in your pipeline are table stakes.
Living with legacy
In many cases, you have no control over legacy software and services. You’re “forced” to use them and rely on them. Think of external systems like airline and hotel booking platforms, or at the infrastructure layer networking and CDN configuration. When you can’t directly or quickly modernize these legacy systems, you need to put in a scheme to quarantine these systems and, longer term, a scheme to modernize or replace them.
Fork-lift with caution
People often dream of “lift-and-shift” schemes where-in software is simply boxed up and moved to new, better environments. This may be the case with simple, well written, and low priority applications, but in many cases, simply “lifting and shifting” is chimera of improvement. As Forrester’s John Rymer points out, this approach looks the easiest but has the worst long-term payoff. This is because simply changing how you manage the lifecycle of the application without changing the application itself can limit the benefits of a DevOps-driven approach, namely, the ability to quickly add new features while maintaining a high level of availability in production. Evaluate these so called “forklift” fixes carefully: they could be exceeding easy, or deceptively disastrous.
Strangling with APIs
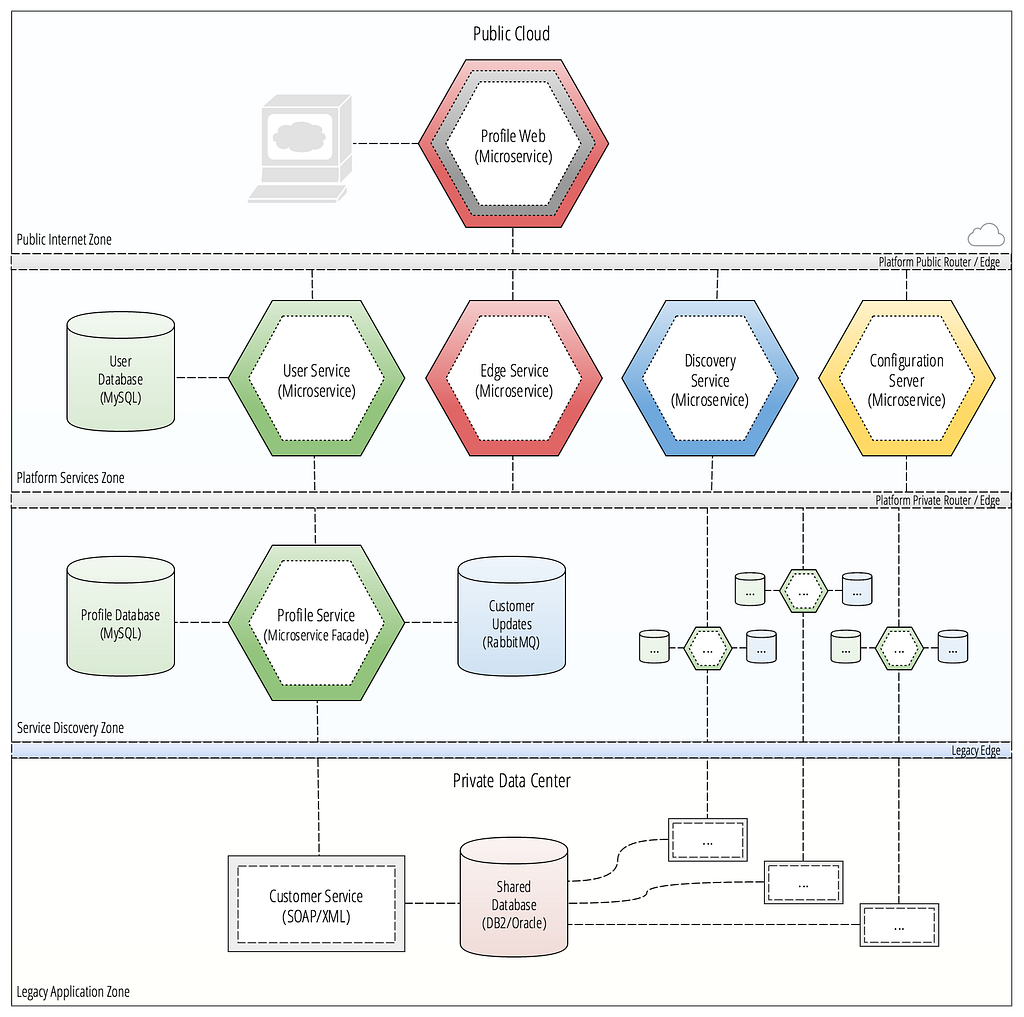
The first step is to properly “hide” legacy services behind APIs, shifting all of your code over to using those APIs that you control. At first, and perhaps forever, these will just be “pass through” calls, but they give you an important architectural optionality: you can selectively replace what happens when those APIs are called. Now, this is a pattern as old as time in software development, what’s important is to actively garden that optionality rather than thinking that one day you might just magically “swap out the implementation.”
The “strangler pattern” describes this gardening over time. You create APIs as a front-end to legacy services and processes, and slowly start replacing various subcomponents of those legacy systems. At first, all of the actual work will be done by the legacy service, but just like a strangler vine, your new code will take over slowly until the legacy code is no longer used, rotting out and leaving just the new code. This slow and steady pace generally makes this a safe, time conscious approach to working with and then modernizing legacy services. This pattern is covered numerous places, including Matt Stines’ book on migrating to Cloud Native applications, which contains numerous other approaches for modernizing legacy architectures.
One variant of this looks to convert your ESB and SOAP driven SOA services over to new approaches, like microservices, slowly but surely. Rohit Kelapure’s paper on this topic describes a general approach and key tactics for this type of conversion. Comcast’s Vipul SavJani and Christopher Tretina describe an approach they off-handedly call “two layers of trickery” to deal with similar issues.
Finally, dealing with data is often the most difficult process. How do you move from rigid, risky and slow to change relational databases? The book Refactoring Databases describes several tactics. Kenny Bastani has described a clever approach that focuses on slowly changing your data over time, even moving it to new data stores.
In all these cases, the first step is to isolate and hide the legacy services, but still keep using it. This quarantining allows you to better manage how you interact with the legacy service. If you can swing it — or need to! — you can then focus on replacing, or simply augmenting, the legacy service and even data.
Avoiding legacy pitfalls
While you’re digging your way out of a pile of legacy code, it’s good to ask yourself how you got in this dilemma in the first place. Acquisitions are a common path, especially for large organizations: you end up not only with another organization’s legacy software, but software that’s so different and incompatible with yours that it has many of the same productivity and quality drag effects as legacy software.
More commonly, though, organizations have failed to put proper portfolio management in place that helps prevent legacy problems. If you’re stuck in legacy, now’s a good time to fix that. As in the discussion of agile software methods above, you should start by verifying that you’re actually following any legacy management strategies you have in place.
Prioritize your portfolio
In the context of managing legacy, portfolio management means monitoring and managing the full life-cycle of software. You should first have an inventory of all the software in place — or the ability to create an inventory on demand. Next, you need to know who’s the owner for that application and who’s responsible for keeping it up and running. Finally, you’d like to know where application is in its life-cycle: is it brand new, operating in a state of full usefulness, or sort of just puttering along. Know all of this — the software itself, the stakeholders, the operators, and the current business value — will allow you to prioritize what you do with each piece of legacy software.
Clearly, software that sees heavy use should be well taken care of; you should spend much preventative energy to keep the software as hygienic as possible, for example, keeping tests up-to-date so that integration builds run green and paying close attention to technical debt.
Lower priority software should be treated accordingly as well. If it’s of low enough value, ensure that you’ve fully virtualized the application, if not moved it to a managed service provider or a SaaS version of the application if that makes sense. The goal with low-priority software in legacy management is to reduce its slowing down your ability to create and evolve innovative software. It’s just like paying down debt to free up money for investing in growth.
Turn it off and see who complains
If you’re extremely lucky, There may also be applications that can be decommissioned. There may be applications that remain just to keep up access to the data they hold in databases, for example, for regulatory reasons or historical analysis. Could these just be extracted to a general purpose database or even flat files, removing the need to maintain the actual application? In other instances, you may have software that simply isn’t used anymore.
The tried and true pattern of monitoring for usage over a period of time (say one to three months) and then, if there’s no activity, turning the application off and seeing who, if anyone, complains could be applied. You could also follow a more mature approach and try to track down the owners, asking them if it’s OK to turn the application off. For those owners who are reluctant to turn off applications, use a tried and true trick from software vendors who want users to upgrade to newer version: charge an arm and a leg to keep running the out of date software.
GOTO rewrite
Finally, as an annoying rhetorical GOTO loop, it may be time to rewrite the application. If a legacy application has high business value, yet is impossibly risky to change, it’s worth spending to effort to rewrite it. This may take time and even carry risk, but it might be less risky than doing nothing. One company I spoke with has been doing just this. Part of their portfolio consisting of around five core applications and services had grown from in-house development and acquisitions. The portfolio was over ten years old and showing signs of legacy drag. A third party analyzed different options and concluded that rewriting the applications over the course of two years would actually be more cost effective and less risky than “refactoring” the existing code.
In all of these cases, it’s good to use the pain of dealing with legacy as a reminder to actively manage your portfolio and ensure overall code hygiene; that is, to avoid creating legacy problems through neglect. The best time to start flossing is yesterday, barring that, before all your teeth rot out, today is a pretty good time to start.
If you liked the above, check out two other excerpts: living with auditors and picking which projects to start with. Also, I’d appreciate your input as I finish up the full draft of this booklet.
✹
This article is part of Built to Adapt, a publication by Pivotal that shares stories and insights on how software is changing the way businesses are built.

Deal with Legacy Before it Deals with You was originally published in Built to Adapt on Medium, where people are continuing the conversation by highlighting and responding to this story.






