

By Lan Vu and Hari Sivaraman
Deploying machine learning/artificial intelligence (ML/AI) solutions in enterprises is challenging because it requires integrating many different hardware and software components. The increasing demand for delivering the latest advanced technologies in ML/AI makes ML infrastructure in enterprises more complex. VMware vSphere seamlessly integrates Tanzu capabilities (including Tanzu Kubernetes Grid) with NVIDIA AI Enterprise and helps organizations save time and money on building ML infrastructure.
In our recent technical paper, we provide best practices for ML/AL workload deployment in Tanzu with NVIDIA AI Enterprise and show you how to optimize and scale ML applications in vSphere.
Performance of ML/AI Workloads in vSphere with Tanzu & NVIDIA AI Enterprise
VMware vSphere 8 U1 and U2 with VMware Tanzu support the latest GPUs (like H100, A100, L40, etc.). This combination of software delivers good performance for ML/AI workloads while enabling the best-in-class Kubernetes environment for running and scaling these workloads. To demonstrate, we tested the performance of several popular ML/AI workloads—including Mask R-CNN, BERT, and RNNT—in Tanzu with TKG and compared results with their performance when running in a non-Tanzu environment (which does not use TKG and GPU Operator).
Zero Overhead of ML/AI Performance
The ML/AI workloads were tested in the two following scenarios using a 40c vGPU profile with 40GB of GPU memory per vGPU.
- With Tanzu: Workloads were deployed with Tanzu TKG and NVIDA GPU Operator
- Without Tanzu: Workloads were deployed in the traditional way of NVIDIA AI Enterprise without Kubernetes (Tanzu Kubernetes Cluster) or NVIDIA GPU Operator.
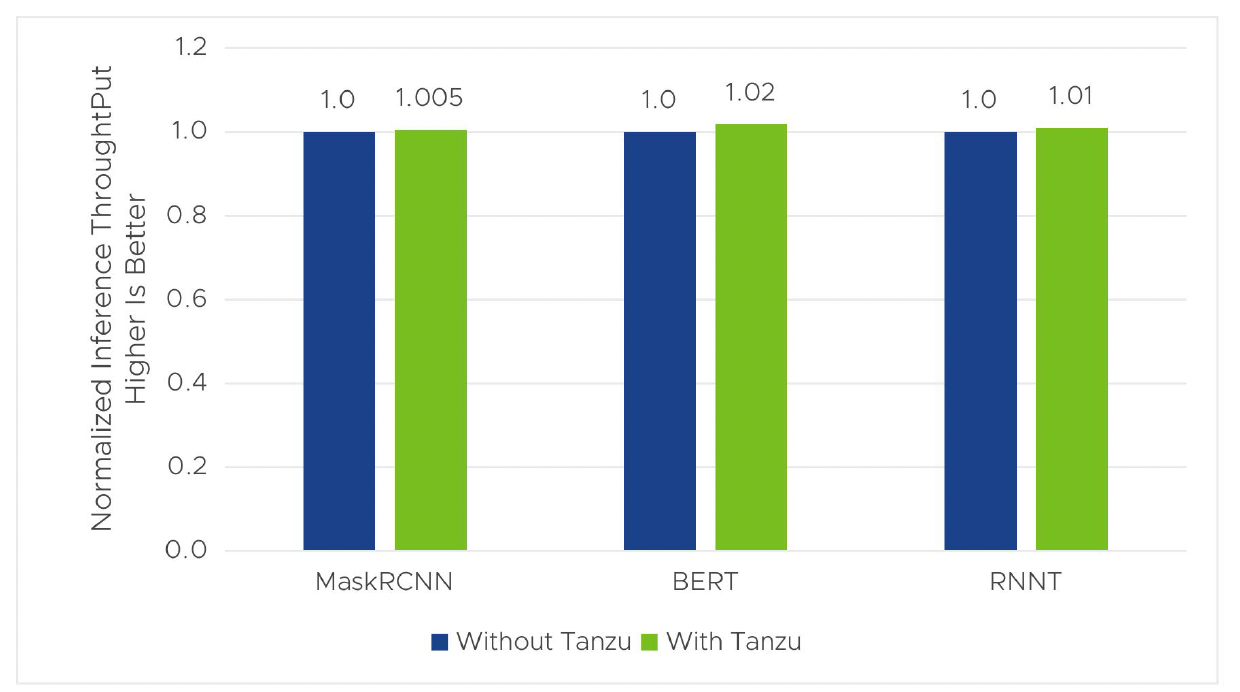
Figure 1. Inference throughput with and without Tanzu
The results in figure 1 show that the inference throughput of Mask R-CNN, BERT, and RNNT with Tanzu is almost no difference or slightly better (1%–2%) when compared to the ones without Tanzu. The results are normalized to those without Tanzu. In vSphere 8 U1 with Tanzu, we used the default image of Ubuntu 20.04 provided by VMware. This reduced the effort of preparing VMs to run the workloads and provided optimized performance for the ML/AI applications.
Improvement of ML/AI Performance with vSphere 8 U1
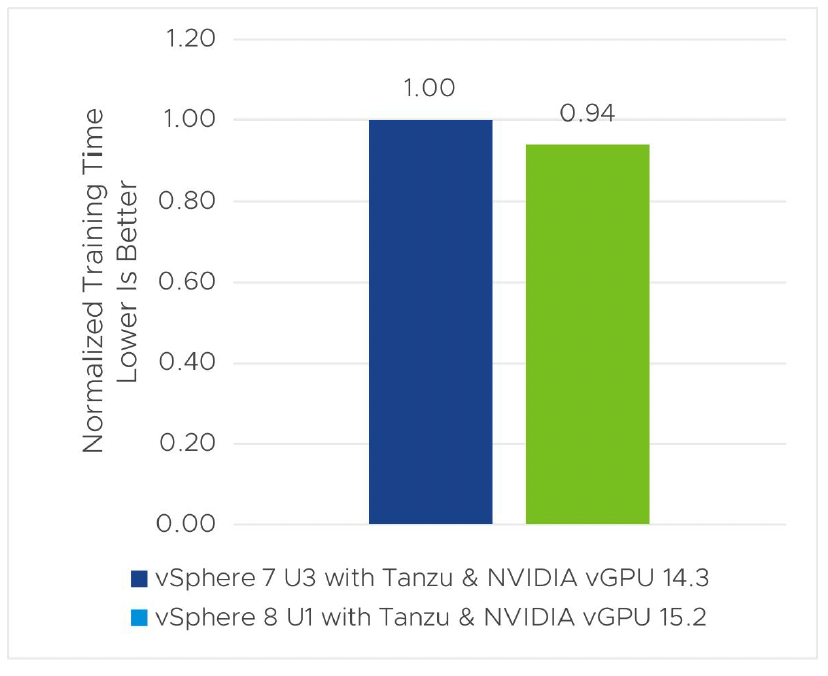
vSphere 8 U1 with NVIDIA AI Enterprise delivers better performance for ML/AI workloads when compared to vSphere 7 U3. Figure 2 shows a 6%–7% performance improvement of vSphere 8 U1 over vSphere 7 U3 in training time and throughput of Mask R-CNN. For the inference of Mask R-CNN, we also see a 2% improvement in inference time and throughput, as shown in figure 3.
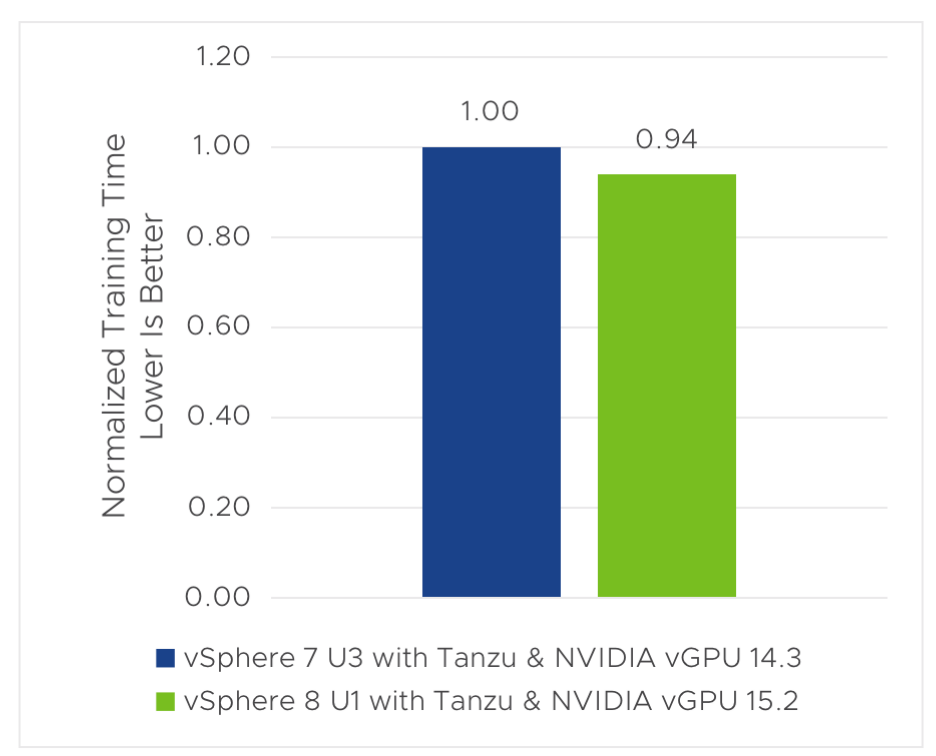
Figure 2. Training time of MaskRCNN in vSphere 8 U1 vs vSphere 7 U3 with Tanzu
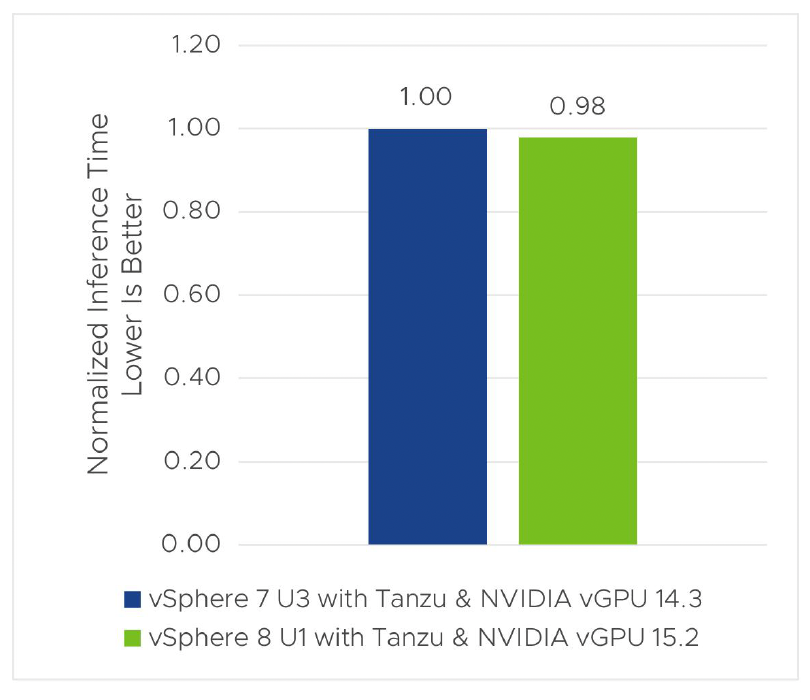
Figure 3. Inference time of MaskRCNN in vSphere 8 U1 vs vSphere 7 U3 with Tanzu
Optimizing ML/AI Workload Performance
NVIDIA AI Enterprise offers two options to share GPUs among multiple VMs in VMware vSphere. You can use NVIDIA vGPU with a time-sliced scheduler or with multi-instance GPU (MIG) technology. With these two options, which one should you choose for your ML/AI workload? In this section, we conducted experiments that involved Mask R-CNN training and inference in two scenarios (shown in table 1) that mimic the light and heavy loads of ML applications. The results of these experiments in figures 6 and 7 provide some guidelines on selecting a suitable option for your workload.
|
Light Load |
Heavy Load |
|
|
Workload |
Mask R-CNN |
Mask R-CNN |
|
Batch Size |
2 |
8 |
|
Type of vGPU / MIG profile |
5c or 1-5c |
40c or 7-40c |
|
Number of VMs |
4 |
1 |
Table 1. Test scenarios for sizing the ML workloads
In general, if your workload is light and does not fully utilize GPU resources, especially the compute resource, MIG vGPU will be a better option. Because compute cores are partitioned and independently executed among MIG vGPUs, MIG helps multiple VMs (Kubernetes nodes in a TKG cluster) that are running a light workload (like a small ML model or a model with a smaller batch size) to maximize the utilization of all available CUDA cores. vGPU uses time-sliced scheduling for GPU sharing and can have a large portion of CUDA cores underutilized when the workload is very light, and this makes it not work as well as MIG in GPU sharing for light workloads.
With heavy loads where you need one vGPU per GPU, vGPU gives better performance than MIG vGPU for the tested workload. When the workload has unknown characteristics, it is better to test both to select the right one. Please note that, when multiple full vGPUs are assigned to a VM for training a larger model, the time-slicing mode is required.
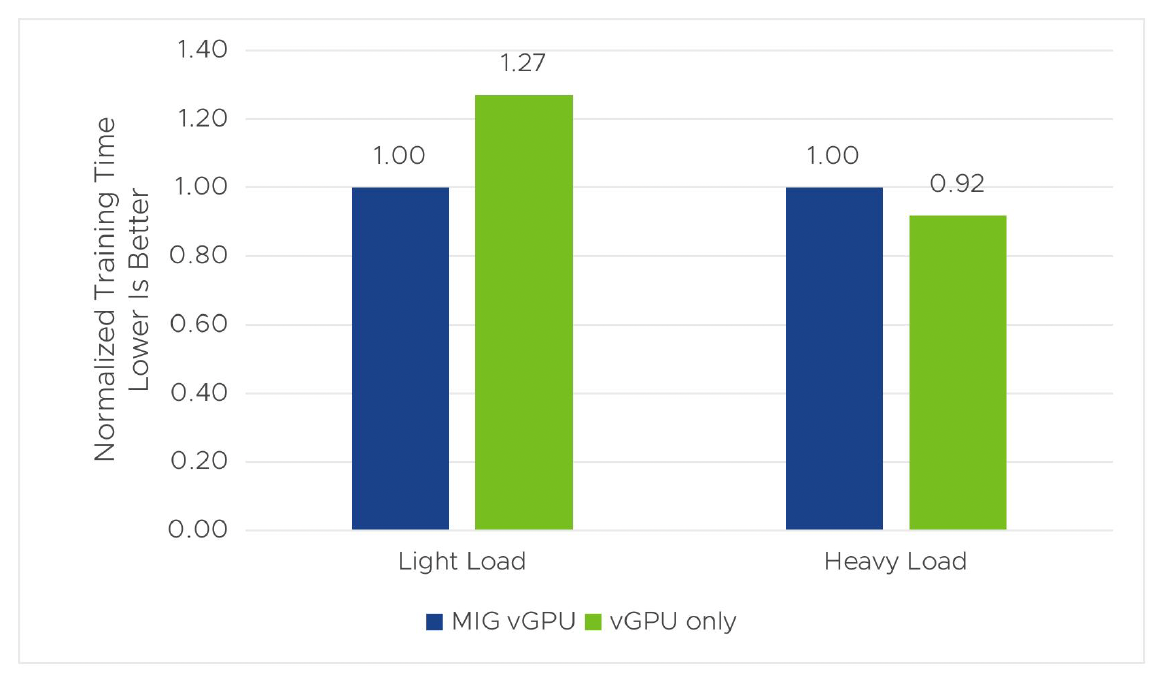
Figure 4. Training time of MIG vGPU vs. vGPU only in vSphere 8 U1 with Tanzu
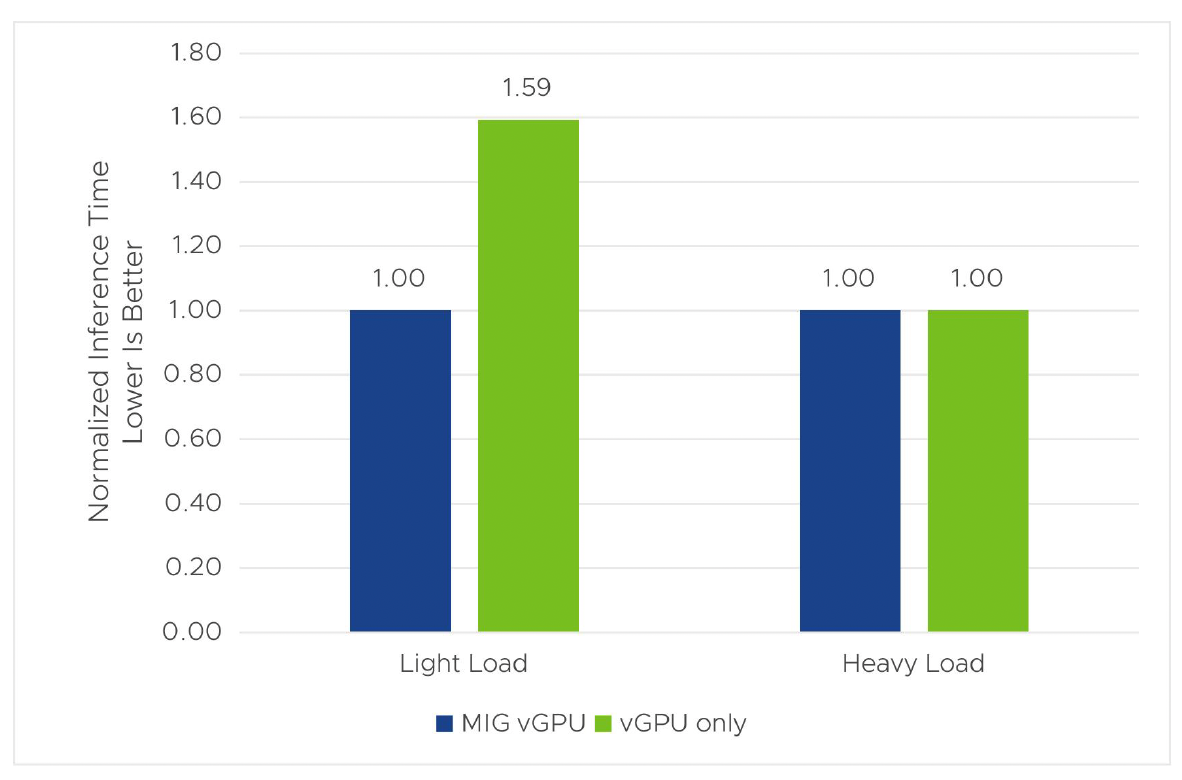
Figure 5. Inference time of MIG vGPU vs. vGPU only in vSphere 8 U1 with Tanzu
Scaling ML/AI Workloads Sharing a GPU
One of the key benefits of deploying ML/AI workloads with TKG is the fast and easy way of scaling ML/AI workloads by simply applying deployment configuration in a YAML file, similar to the way we usually do with Kubernetes. Virtual machines (or nodes in a Kubernetes cluster) are provisioned and scheduled based on the configurations we specify. Tanzu with TKG and NVIDIA AI Enterprise also provides good performance when scaling with more nodes running ML/AI workloads in a TKG cluster.
We demonstrate this in figures 7 and 8. In our experiments, we ran the Mask R-CNN workload scaling from 1–7 VMs (or TKG nodes) concurrently, sharing a single A100 GPU using a MIG vGPU profile. Since we usually apply GPU sharing for a light load, we set batch size = 2 for Mask R-CNN so that the ML load was very light. We chose the lowest vGPU (profile A100-1-5c) when configuring the VM class in the workload management of the vSphere Client and used this VM class to deploy a TKG cluster with the number of nodes ranging from 1–7. The results (figures 8–9) show linear scaling in throughput with multiple nodes sharing the same GPU, and the training and inference time have minimal impact with multiple VMs running concurrently. This comes from the use of MIG for the light-load case.
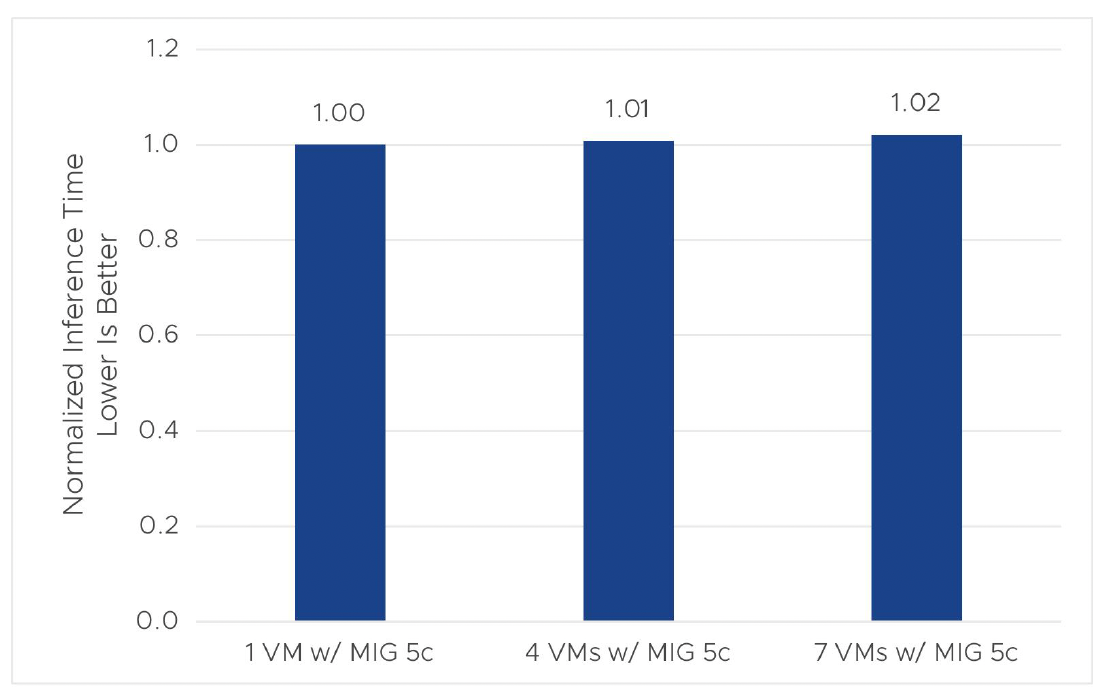
Figure 6. Inference time when scaling in vSphere 8 U1 with Tanzu
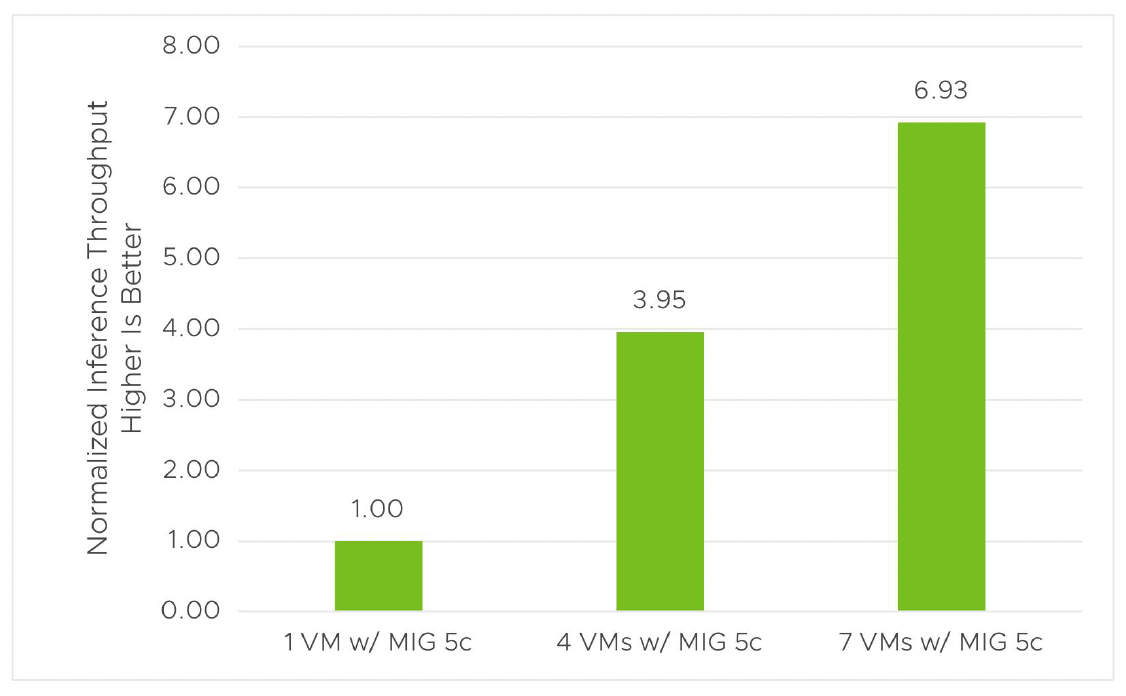
Figure 7. Inference throughput when scaling in vSphere 8 U1 with Tanzu
Takeaways
We explored ML/AI workloads in vSphere 8 U1 with TKG and NVIDIA AI Enterprise and provided best practices on optimizing and scaling these workloads. A few key takeaways from our performance study include:
- Compared to the traditional way of deploying ML/AI workloads with vGPUs, the deployment with TKG has no overhead or even gives better performance with an optimized configuration.
- ML/AI workloads in vSphere 8 U1 perform slightly better (2%–7%) than in vSphere 7 U3.
- When your workloads are lightweight (small models, small batch sizes, and small input data) and won’t utilize all available CUDA cores, choosing MIG vGPU can give you a higher consolidation of VMs (TKG nodes) per GPU with better performance. This also means saving money for your ML/AI infrastructure.
- Scaling ML/AI workloads with TKG is fast, easy, and has good performance. This is one of the key benefits of using TKG for ML/AI.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.






{kind=link}