
By Uday Kurkure, Lan Vu, and Hari Sivaraman
VMware, with Dell, submitted its MLPerf Inference v1.1 benchmark results to MLCommons. The accepted and published results show that high performance with machine learning workloads can be achieved on a VMware virtualized platform featuring NVIDIA GPU and AI technology.
The testbed consisted of a VMware + NVIDIA AI-Ready Enterprise Platform, which included:
- VMware vSphere 7.0 U2 data center virtualization software
- NVIDIA AI Enterprise software
- Three NVIDIA A100 Tensor Core GPUs
- Dell EMC PowerEdge R7525 rack server
- Two AMD EPYC 7502 processors with 128 logical cores
To learn of any virtualization overhead, VMware benchmarked this solution against an identical system that ran on bare metal (no virtualization). The MLPerf benchmark results showed the virtualized system achieved from 94.4% to 100% of the equivalent bare metal performance with only 24 logical CPU cores and 3 NVIDIA vGPU A100-40c. By using the virtualized platform, you’d still have 104 logical CPU cores available for additional demanding tasks in your data center. This solution displays extraordinary power by achieving near bare metal performance while providing all the virtualization benefits of VMware vSphere: server consolidation, power savings, virtual machine over-commitment, vMotion, high availability, DRS, central management with vCenter, suspend/resume VMs, cloning, and more.
Read more about these solutions:
- VMware and NVIDIA AI Enterprise
- Architectural Features of NVIDIA GPU Ampere A100 and TensorRT
- Virtualized NVIDIA A100 GPUs in vSphere
Or go straight to the benchmark result:
VMware vSphere and NVIDIA AI Enterprise
VMware and NVIDIA have partnered to unlock the power of AI for every business by delivering an end-to-end enterprise platform optimized for AI workloads. This integrated platform delivers best-in-class AI software: the NVIDIA AI Enterprise suite. It’s optimized and exclusively certified by NVIDIA for the industry’s leading virtualization platform: VMware vSphere. The platform:
- Accelerates the speed at which developers can build AI and high-performance data analytics
- Enables organizations to scale modern workloads on the same VMware vSphere infrastructure in which they have already invested
- Delivers enterprise-class manageability, security, and availability
Furthermore, with VMware vSphere with Tanzu, enterprises can run containers alongside their existing VMs.
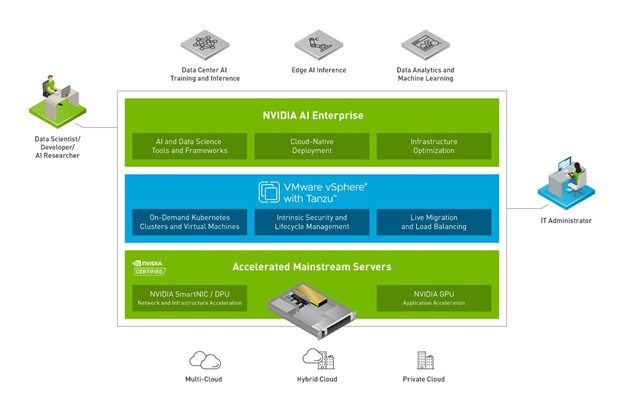
Figure 1. NVIDIA and VMware products working alongside each other
VMware has pioneered compute, storage, and network virtualization, reshaping yesterday’s bare metal data centers into modern software-defined data centers (SDDC). Despite this platform availability, many machine learning workloads are still run on bare metal systems. Deep learning workloads are so compute-intensive that they require compute accelerators like NVIDIA GPUs and software optimized for AI; however, many accelerators are not yet fully virtualized. Deploying unvirtualized accelerators makes such systems difficult to manage when deployed at scale in data centers. VMware’s collaboration with NVIDIA brings virtualized GPUs to data centers, allowing data center operators to leverage the many benefits of virtualization.
Architectural Features of NVIDIA GPU Ampere A100 and TensorRT
VMware used virtualized NVIDIA A100 Tensor Core GPUs with NVIDIA AI Enterprise software in vSphere for MLPerf Inference v1.1 benchmarks. VMware also used NVIDIA TensorRT, which is included with the NVIDIA AI Enterprise software suite. NVIDIA TensorRT is an SDK for high performance, deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning inference applications.
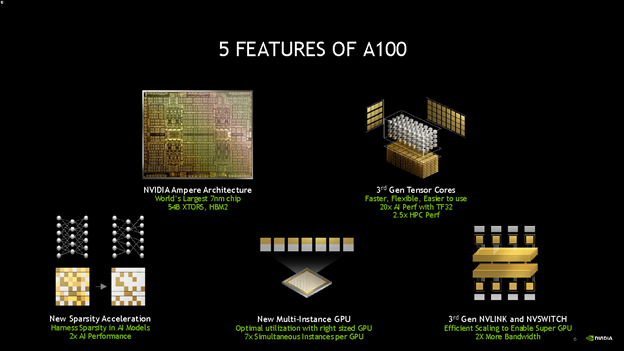
Figure 2. Five features of NVIDIA A100 GPUs
The NVIDIA Ampere architecture is designed to accelerate diverse cloud workloads, including high performance computing, deep learning training and inference, machine learning, data analytics, and graphics. We will focus on NVIDIA’s virtualization-related technologies: NVIDIA Multi-Instance GPU (MIG) and time-sliced vGPU.
NVIDIA A100 GPUs are shared among multiple VMs in two ways:
- Temporal Sharing/Time Slice: All the CUDA cores are time multiplexed while the GPU HBM2 memory is statically divided equally between VMs. This sharing is also known as time-sliced sharing.
- Spatial Sharing/MIG: Each NVIDIA A100 GPU can be composed of seven physical slices. These slices can be combined to make bigger slices. This is also known as Multi-Instance GPU (MIG). The GPU can be partitioned in up to seven slices, and each slice can support a single VM. There is no time slicing.
Table 1 below describes NVIDIA Ampere for data center deployment.
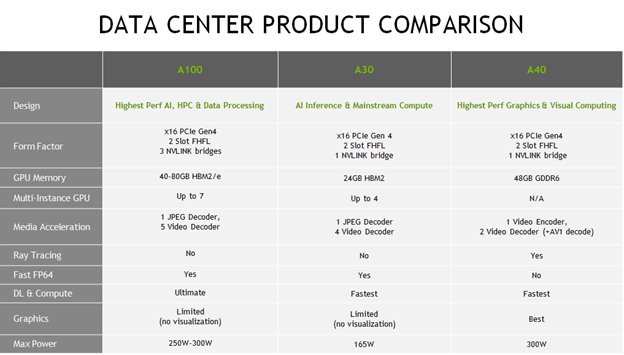
Table 1. NVIDIA GPUs for Data Center Deployment in VMware vSphere
Virtualized NVIDIA A100 GPUs in VMware vSphere
NVIDIA AI Enterprise software suite includes the software needed to virtualize an NVIDIA GPU, including the NVIDIA vGPU manager that is installed in VMware ESXi hypervisor. Multiple, different guest operating systems running in the VMs can share the GPU. They could be running diverse ML/AI workloads. See figure 3.
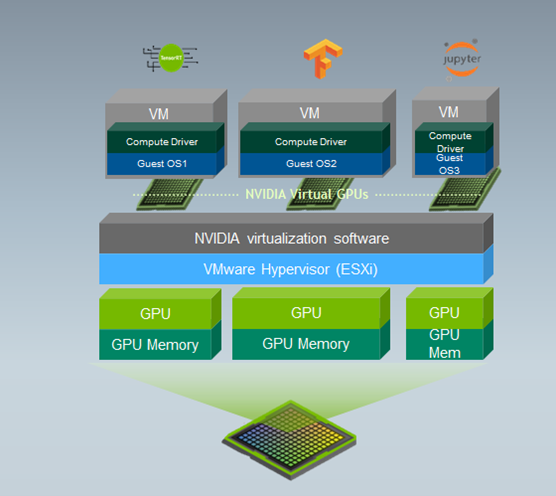
Figure 3. Virtualized NVIDIA A100 GPU with MIGs in VMware vSphere
Time-Sliced Virtual GPU Types for NVIDIA A100 PCIe 40GB
These vGPU types support a single display with a fixed maximum resolution.
For details of GPU instance profiles, see NVIDIA Multi-Instance GPU User Guide.
Table 2 shows different types of vGPU profiles in time-sliced mode to be attached to VMs.
| Virtual NVIDIA GPU Type | Intended Use Case | Frame Buffer (MB) | Maximum vGPUs per GPU | Maximum vGPUs per Board | Maximum Display Resolution | Virtual Displays per vGPU |
| A100-40C | Training Workloads | 40960 | 1 | 1 | 4096×2160 | 1 |
| A100-20C | Training Workloads | 20480 | 2 | 2 | 4096×2160 | 1 |
| A100-10C | Training Workloads | 10240 | 4 | 4 | 4096×2160 | 1 |
| A100-8C | Training Workloads | 8192 | 5 | 5 | 4096×2160 | 1 |
| A100-5C | Inference Workloads | 5120 | 8 | 8 | 4096×2160 | 1 |
| A100-4C | Inference Workloads | 4096 | 10 | 10 | 4096×2160 | 1 |
Table 2. A100 vGPU profiles
MIG-Backed Virtual GPU Types for NVIDIA A100 PCIe 40GB
For details of GPU instance profiles, see NVIDIA Multi-Instance GPU User Guide.
Table 3 shows MIG-backed vGPU profiles for the A100 GPU.
| Virtual NVIDIA GPU Type | Intended Use Case | Frame Buffer (MB) | Maximum vGPUs per GPU | Slices per vGPU | Compute Instances per vGPU | Corresponding GPU Instance Profile |
| A100-7-40C | Training Workloads | 40960 | 1 | 7 | 7 | MIG 7g.40gb |
| A100-4-20C | Training Workloads | 20480 | 1 | 4 | 4 | MIG 4g.20gb |
| A100-3-20C | Training Workloads | 20480 | 2 | 3 | 3 | MIG 3g.20gb |
| A100-2-10C | Training Workloads | 10240 | 3 | 2 | 2 | MIG 2g.10gb |
| A100-1-5C | Inference Workloads | 5120 | 7 | 1 | 1 | MIG 1g.5gb |
| A100-1-5CME | Inference Workloads | 5120 | 1 | 1 | 1 | MIG 1g.5gb+me |
Table 3. A100 MIG-backed vGPU Profiles
MLPerf Inference Performance in VMware vSphere with NVIDIA vGPU
VMware benchmarked the following datacenter applications from the MLPerf Inference v1.1 suite. See Table 4. The official results for these two benchmarks are published by MLPerf.
ML/AI workloads are becoming pervasive in today’s data centers and cover many domains. To show the flexibility of VMware vSphere virtualization in disparate environments, we chose to publish two of the most popular types of workloads: natural language processing, represented by BERT; and object detection, represented by SSD-ResNet34. To find what virtualization overhead there was (if any), we ran each workload in virtualized and bare metal environments.
| Area | Task | Model | Dataset | QSL Size | Quality | Server latency constraint |
| Vision | Object detection (large) | SSD-ResNet34 | COCO (1200×1200) | 64 | 99% of FP32 (0.20 mAP) | 100 ms |
| Language | Language processing | BERT | SQuAD v1.1 (max_seq_len=384) | 10833 | 99% of FP32 and 99.9% of FP32 (f1_score=90.874%) | 130 ms |
Table 4. MLPerf Inference Benchmarks presented
We focused on Offline and Server scenarios. The Offline scenario processes queries in a batch where all the input data is immediately available. The latency is not a critical metric in this scenario. In the Server scenario, the query arrival is random. Each query has an arrival rate determined by the Poisson distribution parameter. Each query has only one sample and, in this case, the latency for serving a query is a critical metric.
Hardware/Software Configurations
Table 5 describes the hardware configurations used for bare metal and virtual runs. The most salient difference in the configurations is that the virtual configuration used virtualized A100 GPU, denoted by NVIDIA GRID A100-40c vGPU. Both the systems had the same 3x A100-PCIE-40GB physical GPUs. The benchmarks were optimized with NVIDIA TensorRT and used NVIDIA Triton Inference server.
| Bare Metal | Virtual Configuration | |
| System | Dell EMC PowerEdge R7525 | Dell EMC PowerEdge R77525
|
| Processors | 2x AMD EPYC 7502 | 2x AMD EPYC 7502
|
| Logical Processor | 128 | 24 allocated to the VM |
| GPU | 3x NVIDIA A100-PCIE-40GB | 3x NVIDIA GRID A100-40c vGPU |
| Memory | 512 GB | 448 GB for the VM |
| Storage | 3.8 TB SSD
|
3.8 TB SSD
|
| OS | CentOS 8.2 | Ubuntu 20.04 VM in VMware vSphere 7.0.2
|
| NVIDIA AIE VIB for ESXi | – | vGPU GRID Driver 470.60 |
| NVIDIA Driver | 470.57 | 470.57 |
| CUDA | 11.3 | 11.3 |
| TensorRT | 8.0.2 | 8.0.2 |
| Container | Docker 20.10.2 | Docker 20.10.2 |
| MLPerf Inference | V1.1 | V1.1 |
Table 5. Bare Metal vs. Virtual Server Configurations
MLPerf Inference Performance Results for Bare Metal and Virtual Configurations
Figure 4 compares throughput (queries processed per second) for the MLPerf Inference workloads using VMware vSphere 7.0 U2 with NVIDIA vGPUs against the bare metal configuration. The bare metal baseline is set to 1.00, and the virtualized result is presented as a relative percentage of the baseline.
Figure 4 clearly shows that VMware vSphere with NVIDIA vGPUs delivers near bare metal performance ranging from 94.4% to 100% for offline and server scenarios for MLPerf Inference benchmarks.
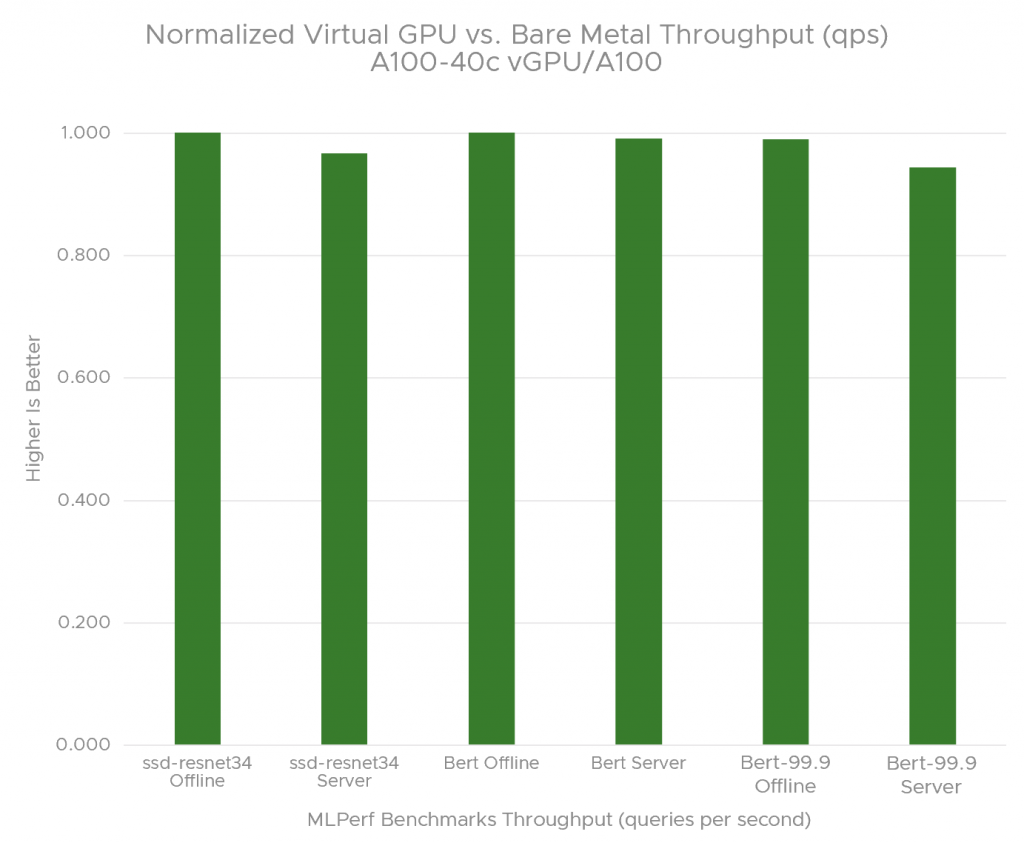
Figure 4. Normalized throughput (qps): NVIDIA vGPU vs bare metal
Table 6 shows throughput numbers for MLPerf Inference workloads.
| Benchmark | Bare Metal 3x NVIDIA A100 |
NVIDIA vGPU 3x A100-40c |
vGPU/BM |
| Bert Offline | 8465 | 8475 | 1.001 |
| Bert Server | 7871 | 7801 | 0.991 |
| Bert-99.9* Offline | 4228 | 4183 | 0.989 |
| Bert-99.9* Server | 3814 | 3602 | 0.944 |
| ssd-resnet34 Offline | 2450 | 2452 | 1.001 |
| ssd-resnet34 Server | 2390 | 2310 | 0.967 |
Table 6. vGPU vs. bare metal throughput (queries/second)
* Bert-99.9 is a 99.9% accuracy achieving deployment.
The above results are published by MLCommons.
Takeaways
- The VMware/NVIDIA solution delivers from 94.4% to 100% of the bare metal performance for MLPerf Inference v1.1 benchmarks.
- VMware achieved this performance with only 24 logical CPU cores out of 128 available CPU cores, thus leaving 104 logical CPU cores for other jobs in the data center. This is the extraordinary power of virtualization!
- VMware vSphere combines the power of NVIDIA AI Enterprise software, which includes NVIDIA’s vGPU technology with the many data center management benefits of virtualization.
Acknowledgements
VMware thanks Liz Raymond and Frank Han of Dell and Vinay Bagade, Charlie Huang, Anne Hecht, Manvendar Rawat, and Raj Rao of NVIDIA for providing the hardware and software for VMware’s MLPerf v1.1 inference submission. The authors would like to acknowledge Juan Garcia-Rovetta and Tony Lin of VMware for the management support.
References
- MLCommons
https://mlcommons.org/en/ - MLCommons v1.1 Results
https://mlcommons.org/en/inference-datacenter-11 - NVIDIA Ampere Architecture
https://www.nvidia.com/en-us/data-center/ampere-architecture - NVIDIA Ampere Architecture In-Depth
https://developer.nvidia.com/blog/nvidia-ampere-architecture-in-depth - NVIDIA Enterprise Documentation: Virtual GPU Types for Supported GPUs
https://docs.nvidia.com/ai-enterprise/latest/user-guide/index.html#supported-gpus-grid-vgpu - MIG or vGPU Mode for NVIDIA Ampere GPU: Which One Should I Use? (Part 1 of 3)
https://blogs.vmware.com/performance/2021/09/mig-or-vgpu-part1.html - Introduction to MLPerf Inference v1.1 with Dell EMC Servers
https://infohub.delltechnologies.com/p/introduction-to-mlperf-tm-inference-v1-1-with-dell-emc-servers - MLPerf Inference Virtualization in VMware vSphere Using NVIDIA vGPUs
https://blogs.vmware.com/performance/2020/12/mlperf-inference-virtualization-in-vmware-vsphere-using-nvidia-vgpus.html - NVIDIA TensorRT
https://developer.nvidia.com/tensorrt - NVIDIA Triton Inference Server
https://developer.nvidia.com/nvidia-triton-inference-server - J. Reddiet al., “MLPerf Inference Benchmark,” 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2020, pp. 446-459, doi: 10.1109/ISCA45697.2020.00045.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.