

By Avinash Chaurasia, Lan Vu, Uday Kurkure, Hari Sivaraman, Sairam Veeraswamy
Network Function Virtualization (NFV) is increasingly adopted by service providers to reduce cost and improve the efficiency and scalability of NFV services. Virtualization and cloud technologies are key to obtain these goals. With NFV, network functions (NF) that are traditionally performed by specialized hardware are now replaced by NF software executing on generic compute units such as x86 cores.
In order to obtain high performance NFV, accelerators like NVIDIA GPUs are used to enhance the NFV throughput, which in turn can help to reduce cost and simplify the large-scale deployment of NFV. In the cloud environment, using virtualized GPUs for NFV has a lot of potential to further enhance the performance of NFV, but it hasn’t had wide adoption in the industry yet.
In this blog, we present our study of using virtualized GPUs to maximize the benefits of NFV in VMware vSphere and of analyzing NF performance with respect to virtual GPU in multiple use cases. We demonstrate using virtual GPU to increase GPU utilization as well as to provide higher performance and throughput for GPU-based NFs. Our test results show that virtual GPUs can help NFV deliver up to 5.4 times more throughput compared to using passthrough GPUs.
NVIDIA GPU Virtualization for Network Function Virtualization Deployment in vSphere
Network functions such as firewall, HTTP proxy, IPSec, and so on can be deployed in a vSphere-based cloud as virtual network functions (VNFs) in a telco cloud infrastructure for deploying and managing VNF workloads. VNFs can access GPUs or other accelerators in vSphere for their computing needs. Accelerating NFs using GPU is enabled with the use of passthrough GPU or NVIDIA virtual GPU (vGPU) technology:
- Passthrough GPU requires each virtual machine (VM) to have at least one dedicated GPU; hence NFs deployed on multiple VMs cannot share all the GPUs available on a server.
- NVIDIA vGPU technology allows many GPU-enabled VMs to share a single physical GPU, or several GPUs to be aggregated and allocated to a single VM, thereby exposing the GPU to VMs as one or multiple vGPU instances. With NVIDIA vGPU, a single GPU can be partitioned into multiple virtual GPU (vGPU) devices as shown in Figure 1. Each vGPU is allocated a portion of GPU memory specified by the NVIDIA vGPU profile.
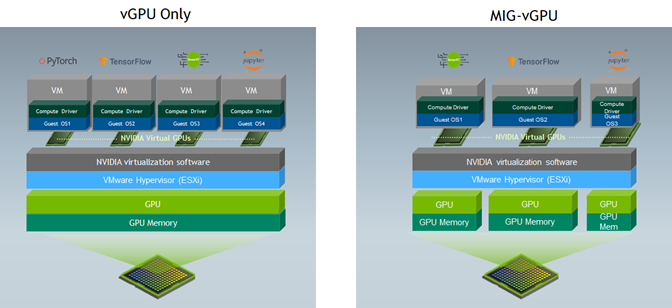
Figure 1. Multiple VMs sharing GPUs using vGPU or MIG-vGPU
There are two ways of sharing a vGPU:
- Using only NVIDIA vGPU software—CUDA cores of the GPU are shared among VMs using time slicing.
- Using NVIDIA multi-instance GPU (MIG) technology[1] with vGPU software—Each GPU can be partitioned into as many as seven GPU instances, fully isolated at the hardware level with their own high-bandwidth memory, cache, and compute cores, and then statically partitioned among VMs as separate vGPUs.
GPU virtualization is managed by the drivers installed inside the VM and the hypervisor. It exposes vGPUs to VMs and shares a physical GPU across multiple VMs.
Our analysis shows that many NFs are both I/O-intensive and compute-intensive, which means sharing a GPU among NFs can boost GPU utilization and hence can increase the NFV throughput.
NVIDIA vGPU software is available in different editions designed to address specific use cases. For the virtualized compute use case with VMware vSphere, NVIDIA AI Enterprise software should be used.
[1] MIG technology is available on the NVIDIA A100 and A30 Tensor Core GPUs
Experiments and Evaluation
To demonstrate the benefits of vGPU for NFV, we present in this blog our experimental results and analysis that highlight the capability of vGPU in supporting and scaling NFV workloads as well as the best practices and use cases for NFV.
GPU-based IPSec and NIDS implementation
For this purpose, we implemented two well-known and compute-intensive network functions:
- Network Intrusion Detection System (NIDS)
- Internet Protocol Security (IPSec)
These NFs perform computation over the payload segment of the packet. IPSec performs both HMAC and AES operations on each packet; both algorithms (cryptography) are considered compute-intensive.
NIDS performs string matching against a predefined set of rules for intrusion detection. We implemented both IPSec and NIDS in CUDA. Our IPSec used HMAC-SHA1 and AES-128 bit in CBC mode. OpenSSL [1] AES-128 bit CBC encryption and decryption algorithm was rewritten in CUDA as part of our implementation. NIDS was implemented using the Aho-Corasick algorithm [2], which is based on deterministic finite automata (DFA). In our implementation, we used 147 rules for building the DFA state. Our design allocated a CUDA thread per packet. In each round, we first copied the packets in GPU memory, then, a kernel was launched where CUDA threads performed computing on their respective packets. On completion, the kernel terminated, and the result was copied back to host memory. To optimize the performance of these NFs, we heavily used constant memory for read-only data access. These read-only data were copied to GPU constant memory at the initialization stage.
The memory footprint of these data varied according to NF. For instance, IPSec accesses big tables for encryption/decryption, and keeping these tables in cache-friendly constant memory greatly boosts the performance. NIDS, however, does not have much predefined read-only data. To provide a further performance boost, we used multiple CUDA streams for NF computing. In such scenarios, we always used an asynchronous mechanism of data copy between the host and device. Furthermore, the total number of CUDA threads were equally divided among the streams. Data (packets and results) were also divided equally among streams and asynchronously transferred between host and device to leverage parallel execution and data copy.
We found that the performance of NF does not monotonically increase with the increase of CUDA streams. When we increased the number of CUDA streams, NF performance also increased until it reached a certain optimal level; after that, it stayed the same or dropped. In our experiments, the number of CUDA streams was kept at this optimal value for the best achievable throughput. Our experiments in the later sections show that using multiple CUDA streams provides better performance than using the default CUDA stream for computing.
Test Setup
Our test setup included host machines (Dell EMC PowerEdge R740xd model) consisting of 32 Intel Xeon cores operating at 2.30 GHz with 766GB of memory. It ran ESXi 7.0 U2 with an NVIDIA A100 Ampere architecture–based GPU [3] and NVIDIA AI Enterprise software.
The VMs that ran our CUDA-based IPSec and NIDS were installed with Ubuntu 18.04 OS, 32GB RAM, and 8 vCPU cores. Packets were generated and kept in memory so that I/O overhead (NIC to main memory and main memory to NIC) did not act as a variable in our analysis.
In this blog, we analyze the experimental results of NFs (IPSec and NIDS) over vGPU and compare it with passthrough mode performance. In most cases, we use the NVIDIA vGPU best effort scheduler. Additionally, we use the term nostream or without stream when the default CUDA stream was used, because every CUDA program uses a default stream of 0. When we mention streams in experiments, it is for the cases where we specially programmed it to use multiple CUDA streams.
Passthrough GPU vs. vGPU for NFV
Passthrough GPU in vSphere can deliver the performance of an NF workload as close to that of a bare metal system. However, passthrough GPU requires a dedicated GPU per VM, which limits the workload consolidation of the server.
NVIDIA vGPU can provide better workload consolidation by enabling GPU sharing among VMs. In case only one vGPU is used, its performance is as close as passthrough GPU; hence, it is also close to bare metal. The throughput performance of an IPSec network function when we used 1 GPU in passthrough mode vs. NVIDIA AI Enterprise with 20C profile is presented in figure 2a, while the one of NIDS is presented in figure 2b. The experiments were performed on the server with an A100 GPU.
Some of the observations seen from these test results are:
- The performance of NFs using passthrough GPU is not much different from using a single vGPU. In most cases, this shows low overhead of the vGPU solution. In some cases, we see vGPU performance is even better than passthrough.
- Both NFs behave differently with respect to packet size. While IPSec throughput decreases with increased packet size, NIDS NF throughput rises with an increase in packet size.
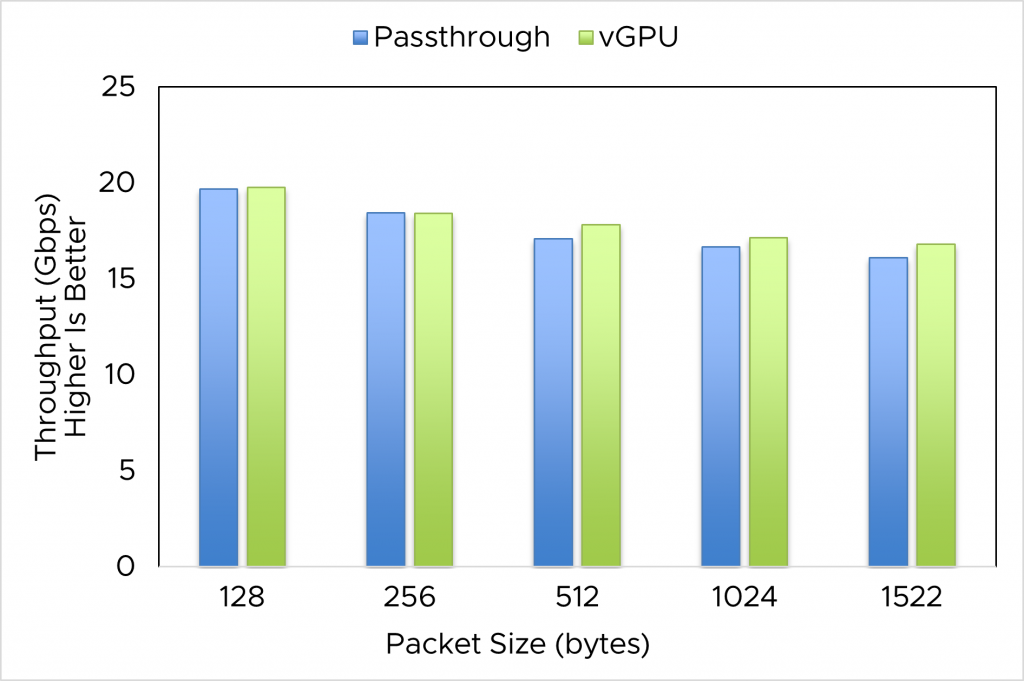
Figure 2a. Throughput of IPSec (with stream) in 1 VM with passthrough vs. vGPU with respect to packet sizes
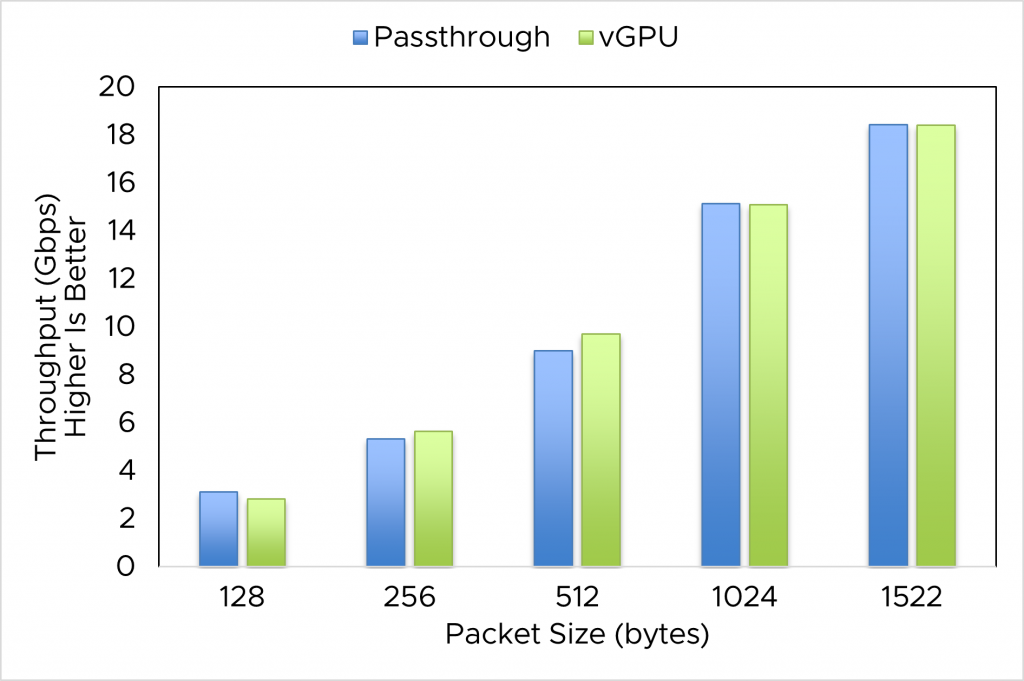
Figure 2b. Throughput of NIDS (with stream) in 1 VM with passthrough vs. vGPU with respect to packet sizes
Maximizing Performance of NFV with Multiple vGPUs Sharing a Single GPU
The key benefit of NVIDIA AI Enterprise for NFV is the throughput increase of up to 5.4 times when we use vGPU to share among NFs compared to no GPU sharing. Most NFs are I/O-intensive and many of them are compute-intensive. Sharing a GPU among multiple NFs using NVIDIA vGPU can help to
- Increase GPU utilization
- Reduce GPU idle time due to waiting on I/O communication
- Hence enhance the throughput of these NFs
By avoiding a dedicated GPU per VM, the hardware cost for GPU-based NFs is reduced, while the isolation and the security of NFs can be preserved because NFs can be deployed in separate VMs.
Figure 3 shows the experimental result of combined NF throughput of all vGPUs ranging from 1 – 10 for an A100 GPU server. Combined throughput means the sum of throughput obtained by executing NF in all the possible vGPU-enabled VMs.
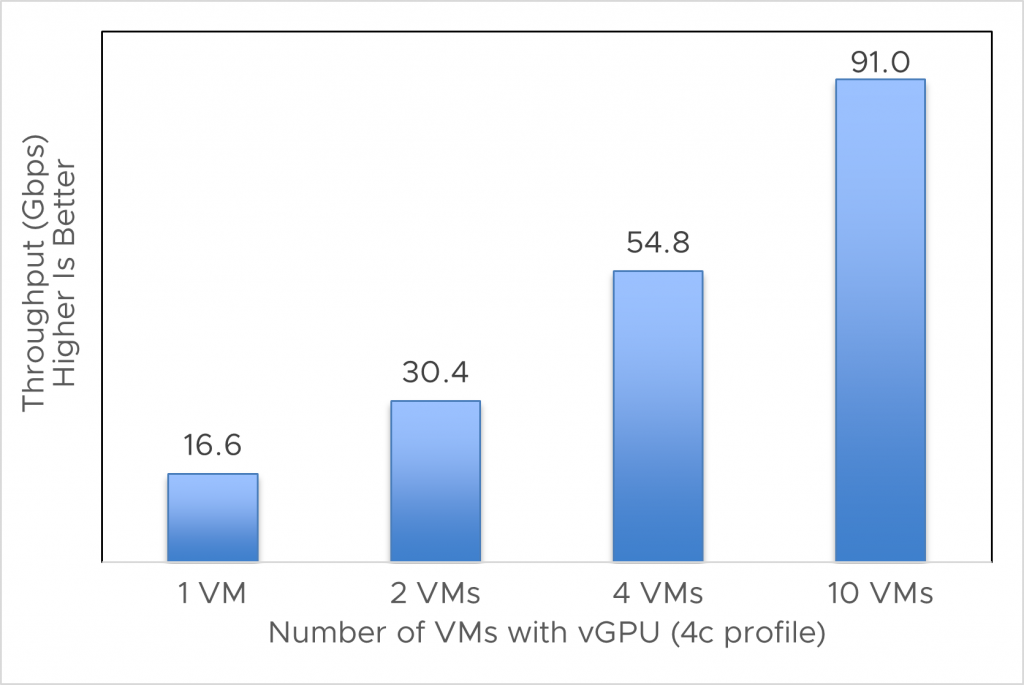
Figure 3. Combined throughput of IPSec (nostream) with different number of concurrent VMs per A100 GPU with NVIDIA AI Enterprise
When we used the NVIDIA AI Enterprise 4C vGPU profile for our experiments, we observed that the combined throughput of either scheduler (equal share scheduler and best effort scheduler) exceeded passthrough mode throughput or one active VM throughput. With A100 GPUs, we can scale to 10 NFs per GPU and each NF per VM with vGPU. In this case, we have seen the throughput of IPSec up to 5.4 times better throughput than their respective one-active-VM throughput.
Sharing GPU Among NFV Workload and Machine Learning Workload
In the trend of growing network-based applications that apply machine learning for processing network data (for example, network instruction detection, network data analysis, and so on), a network chain may include traditional NFs (no machine learning) and machine learning–based NFs. In such cases, GPUs can still be shared among VMs running different types of workloads using vGPUs. This provides flexibility in the deployment of applications that need GPU and reduces the requirement of a dedicated server for each type of workload.
To demonstrate this capability, we ran an NF workload in one VM and a machine learning application on another VM on the same server that shared a single GPU. We analyzed the impact of NF performance when it shared a GPU with other machine learning workloads using vGPU.
Our experimental setup in this case was as follows:
- One vGPU-enabled VM was allocated for NF
- The rest of the vGPU-enabled VMs executed a machine learning workload: the MaskRCNN inference for image segmentation. MaskRCNN is implemented with Python and is a part of NVIDIA Deep Learning Examples [4].
- We used an A100-10C vGPU profile for this experiment.
The throughput performance of IPSec and NIDS with stream (when the MaskRCNN workload is present) with respect to packet size is shown in figures 4a and 4b.
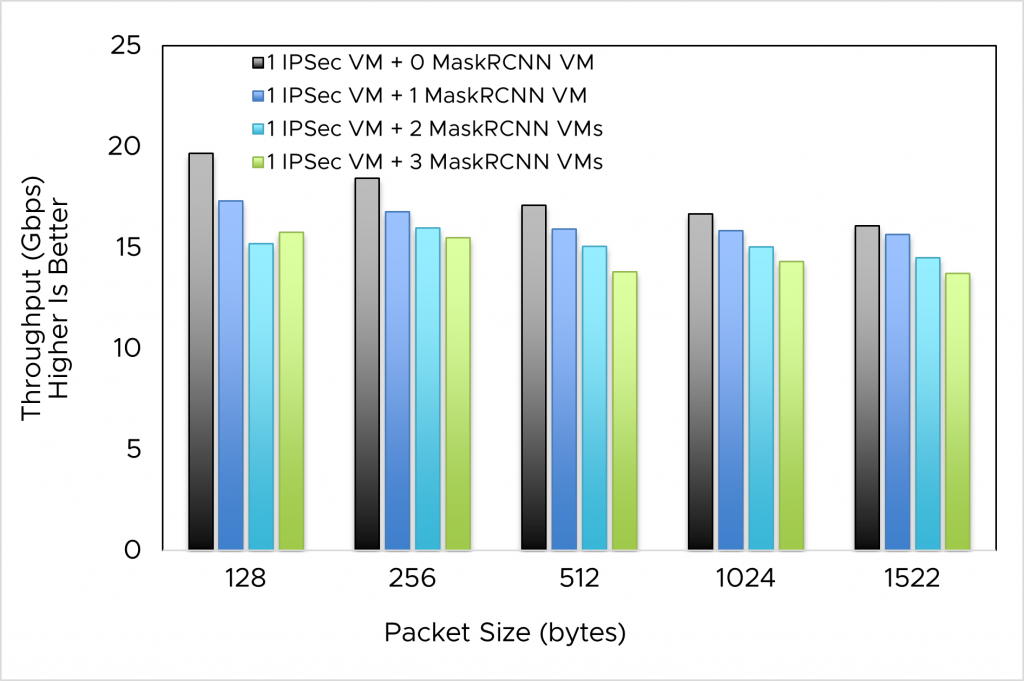
Figure 4a. IPSec (with stream) – NF performance when running concurrently with machine learning workload (MaskRCNN)
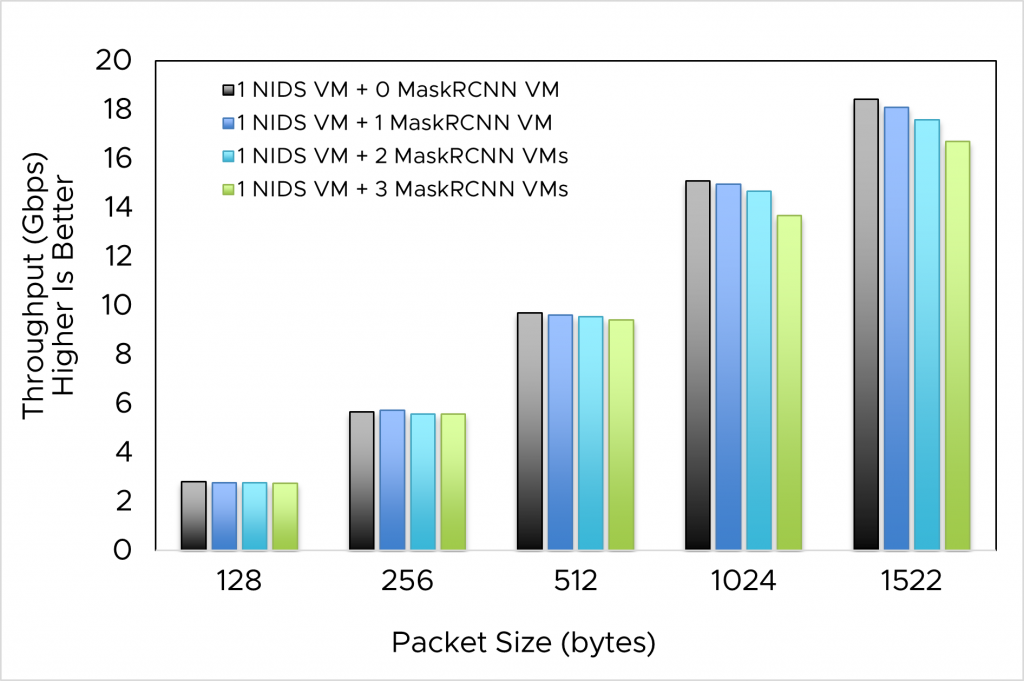
Figure 4b. NIDS (with stream) – NF performance when running concurrently with machine learning workload (MaskRCNN)
The MaskRCNN workload lowers the throughput of the NFs: as the number of VMs with this workload increases, throughput of NF decreases. However, a decrease in throughput for either NFs (IPSec and NIDS, with or without CUDA streams) is not proportional to an increase in the number of VMs with MaskRCNN.
In real-world use cases when cloud providers want a flexible deployment of multiple GPU-based workloads (like both NFs and machine learning) on a single server, we demonstrate such deployment is possible with vGPU. Because machine learning jobs like MaskRCNN are very compute-intensive, they consume all GPU cycles assigned to them, which means reducing the GPU cycles used for NFs. This explains the reduction of NF throughput as the number of VMs running MaskRCNN jobs increase. Hence, we suggest the optimal use of NFs with vGPU is sharing multiple vGPUs with the same NF functions.
Takeaways
We demonstrated the benefits of using vGPU to accelerate an NFV workload. This is important for data-intensive 5G workloads that require huge computing power, from devices like GPU, to be able to deliver the real time processing of network data. A few key takeaways from this blog post are:
- NVIDIA vGPU technology provides performance as good as passthrough GPU or bare metal GPU for an NFV workload.
- Enabling multiple NFs sharing a single GPU using vGPU can help to increase the throughput of an NFV workload up to 5.4 times.
- One of the important benefits of using vGPU for NFV is the ability of sharing a GPU with other GPU-based applications like machine learning. This configuration provides much more flexibility in a cloud infrastructure deployment.
- Our study proves that NFs accelerated with vGPU can provide both good throughput along with hardware-enabled isolation.
Acknowledgements
We would like to thank Juan Garcia-Rovetta, Tony Lin, and Nisha Rai at VMware, as well as Charlie Huang and his team at NVIDIA for the support and feedback of this work.
References
[1] OpenSSL. Tls/ssl and crypto library. https://github.com/openssl/openssl, 2019.
[2] Alfred V. Aho and Margaret J. Corasick. Efficient string matching: An aid to bibliographic search. Commun. ACM, 18(6):333–340, June 1975.
[3] NVIDIA A100 Tensor Core GPU Architecture. https://images.nvidia.com/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf
[4] NVIDIA Deep Learning Examples. https://github.com/NVIDIA/DeepLearningExamples
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.