Performance and Security Optimizations on Intel Xeon Scalable Processors – Part 1
Contributors
Manish Chugtu — VMware
Ramesh Masavarapu, Saidulu Aldas, Sakari Poussa, Tarun Viswanathan — Intel
Introduction
VMware Tanzu Service Mesh built on open source Istio, provides advanced, end-to-end connectivity, security, and insights for modern applications—across application end-users, microservices, APIs, and data—enabling compliance with Service Level Objectives (SLOs) and data protection and privacy regulations.
Service Mesh architecture pattern solves many problems, which are well known and extensively documented – so we won’t be talking about those in this blog. But it also comes with its own challenges and some of the top focus areas that we will discuss in this series of blogs are around:
- Performance
- Security
Intel and VMware have been working together to optimize and accelerate the microservices middleware and infrastructure with software and hardware to ensure developers have the best-in-class performance and low latency experience when building distributed workloads with a focus on improving the performance, crypto accelerations, and making it more secure.
In Part 1 of this blog series, we will talk about one such performance challenge (with respect to service mesh data path performance) and discuss our solution around that.
The current implementation of Service Mesh in Istio involves an overhead of TCP/IP stack, since it uses Linux kernel’s netfilter to intercept and route traffic to and from sidecar proxy (envoy based), by configuring iptables. A typical path between client pod to server pod (even within the same host) traverses the TCP/IP stack at least 3 times (outbound, envoy client sidecar to envoy server sidecar, inbound), causing degradation in the data path performance.

Figure 1: Typical Istio (Envoy) based data path within a Kubernetes node.
To solve this problem, Tanzu Service Mesh uses eBPF to achieve network acceleration by bypassing the TCP/IP networking stack in the Linux kernel. This reduces latency and increases throughput because the data is being written directly into the receiving socket.

Figure 2: TCP/IP bypass in Tanzu Service Mesh using eBPF
In essence, this effort is also aimed at using eBPF for data transfer enhancement without changing the way the service mesh works. If you look at the current implementations of eBPF in the industry, most revolve around more performant observability and traffic control. Some implementations also suggest a no-sidecar model with eBPF, but that comes up with certain limitations and if you want complete L7 control around traffic management/API security, etc., it will still have to rely on an L7 proxy. There are of course pros and cons around that – but that could be a separate blog topic in itself.
With the solution outlined in this blog for utilizing eBPF for performance purposes, the crux is that you can still use your favorite service mesh AS IS with no changes (daemonset deployment model), be that Istio or Tanzu Service Mesh, and still enjoy the benefits of eBPF and completely remove the TCP/IP stack from any inter and intra pod communication within a node. This provides a substantial performance enhancement without eliminating the sidecars. Because, why eliminate the side cars? It is the most elegant solution for service mesh implementation if you can use it as is WHILE gaining the performance we are looking for.
eBPF Background
Before we go into the details of this solution, a basic understanding of eBPF is needed. The below section talks about a very high-level overview of eBPF.

Figure 3: eBPF Develop and Load Flow
Extended Berkeley Packet (eBPF) provides a highly flexible and efficient virtual machine/sandbox mechanism within the Linux Kernel that allows user space applications be executed. The user space applications are compiled into bytecode and are executed in the kernel in a secure manner.
So, when certain kernel events happen, eBPF modules can be invoked. Figure 3 shows how an eBPF module is executed in the Linux kernel space.
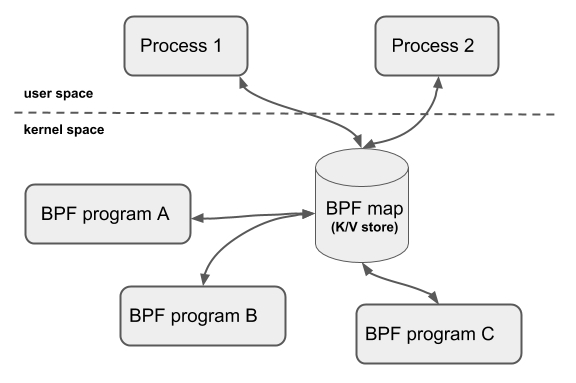
Figure 4: eBPF modules executing in Kernel Space.
There are many different Berkeley Packet Filter (BPF) program types available; two of the main types for networking are explained in the subsections below.
Program Type
SOCK_OPS
BPF_PROG_TYPE_SOCK_OPS (SOCK_OPS for short) allows BPF programs of this type to access some of the socket’s fields (such as IP addresses, ports, etc.). It is called multiple times from different places in the network stack code. In addition, it uses the existing BPF cgroups infrastructure so the programs can be attached per cgroup with full inheritance support. We use SOCK_OPS to capture the sockets that meet our requirements and add them to the map accordingly.
-
- Help functions: BPF_MAP_UPDATE_ELEM, BPF_SOCK_HASH_UPDATE
SOCK_MSG
BPF_PROG_TYPE_SK_MSG (sock_msg for short) can be attached to the sockhash map to capture every packet sent by the socket in the map and determine its destination based on the msg’s fields (such as IP addresses, ports, etc.)
-
- Help functions: BPF_MSG_REDIRECT_HASH
HELPER FUNCTION
Helper functions enable BPF programs to consult a core-kernel-defined set of function calls to retrieve data from or push data to the kernel. Available helper functions may differ for each BPF program type. For example, BPF programs attached to sockets are only allowed to call into a subset of helpers, compared to BPF programs attached to the TC layer. One helper function is explained below.
BPF_MSG_REDIRECT_HASH
This helper is used in programs that implement policies at the socket level. If the message *msg* is allowed to pass (i.e. if the verdict eBPF program returns **SK_PASS**), redirect it to the socket referenced by *map* (of type **BPF_MAP_TYPE_SOCKHASH**) using a hash *key*.
MAP
This helper is used in programs that implement policies at the socket level. If the message *msg* is allowed to pass (i.e. if the verdict eBPF program returns **SK_PASS**), redirect it to the socket referenced by *map* (of type **BPF_MAP_TYPE_SOCKHASH**) using a hash *key*.
SOCKHASH
Sockhash and Sockmap are data structures used to store kernel-opened sockets. Sockmap is currently backed by an array and enforces keys to be four bytes. This works well for many use cases. However, this has become limiting in larger use cases where a Sockhash would be more appropriate. When the Sock_msg program which is attached on the Sockhash is called to redirect a msg, the lookup key can ensure that the peer socket can be found as soon as possible.
How does the Solution Work?
Workflow of eBPF programs
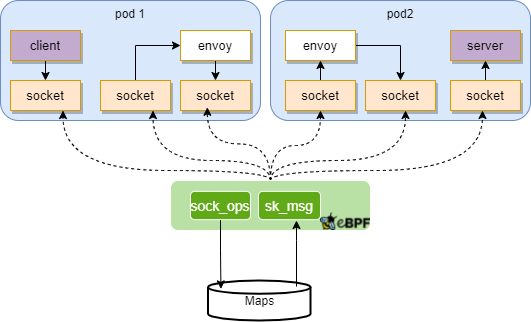
Figure 5: Workflow of eBPF Solution for TCP/IP Bypass.
The workflow of TCP/IP bypass could be separated into two phases:
- Adding SOCKET pairs to HASHMAP
SOCK_OPS is attached to unified cgroups, which will monitor all sockets globally. It takes effects at the point of TCP state changing, capturing the socket in specific TCP states, and populating the maps such as SOCKHASH with socket information.
- Redirection for SOCKET in HASHMAP
SK_MSG is attached to a SOCKHASH map, which will monitor sockets in the map. It takes effects at the point of the socket sending msg, looking up the peer socket from the maps, and redirecting the msg to the peer socket.
Accelerating Tanzu Service Mesh Datapath
Now let’s deep dive into the internals of what happens at each stage of the packet traversing from the client to the server pod.
Outbound Acceleration

Figure 6: TCP/IP eBPF Bypass Acceleration for Outbound Traffic
For outbound, the client application tries connecting to another service, but after iptables rule is applied, traffic is redirected to envoy sidecar (client application sets up a TCP connection with the sidecar). So, client app holds the active socket which has cluster IP and port as its remote address, and envoy holds the passive socket which has localhost IP, and 15001 as a local address. Only recording socket 4-tuple address and socket fd like the inbound case is not enough here to find out peer socket. To resolve this problem, a proxy map is introduced to record the socket pair addresses during TCP handshake. Source address never changes during communication, it helps figure out which two sockets belong to the same connection.
Envoy to Envoy Acceleration on the Same Host

Figure 7: TCP/IP eBPF Bypass Acceleration between Envoy side cards on the same host.
Envoy-to-Envoy acceleration is almost the same as outbound. Because from perspective of kernel, they are all redirected by iptables, and destination address is modified. But the two envoys might be on different hosts, in this case proxy map will not be populated because two hosts cannot share map content, the mapping between original destination and new address cannot be established on one single host. Therefore SK_MSG can’t match any entry to get peer socket address in the proxy map when sending msg, in this cross-node case package is sent out through TCP/IP stack.
Inbound Acceleration

Figure 8: TCP/IP eBPF Bypass Acceleration for Inbound Traffic
For inbound, server-side envoy connects server application actively. Envoy will hold an active socket, and server app holds a passive socket. SOCK_OPS is used to define and insert the callback function to kernel; therefore, corresponding callback will be invoked when TCP state changes. When active socket hits the active established state and passive socket hits passive established state respectively, socket 4-tuple address and socket fd of these two sockets are recorded to the SOCKHASH map. After TCP handshake done, and the socket tries to send msg, its peer socket can be looked up from the map based on peer socket 4-tuple address by reversing itself local and remote address.
NOTE: This design requires an Istio version greater than v1.10 which has the flag INBOUND_PASSTHROUGH set by default. This flag makes the envoy using pod IP as destination IP to communicate with the server app, and if this flag is not set, the envoy will use localhost IP, then it causes conflict when populating the map since our SOCK_OPS program is attached to unified “cgroup”.
Benchmarking Performance Numbers – Tanzu Service Mesh
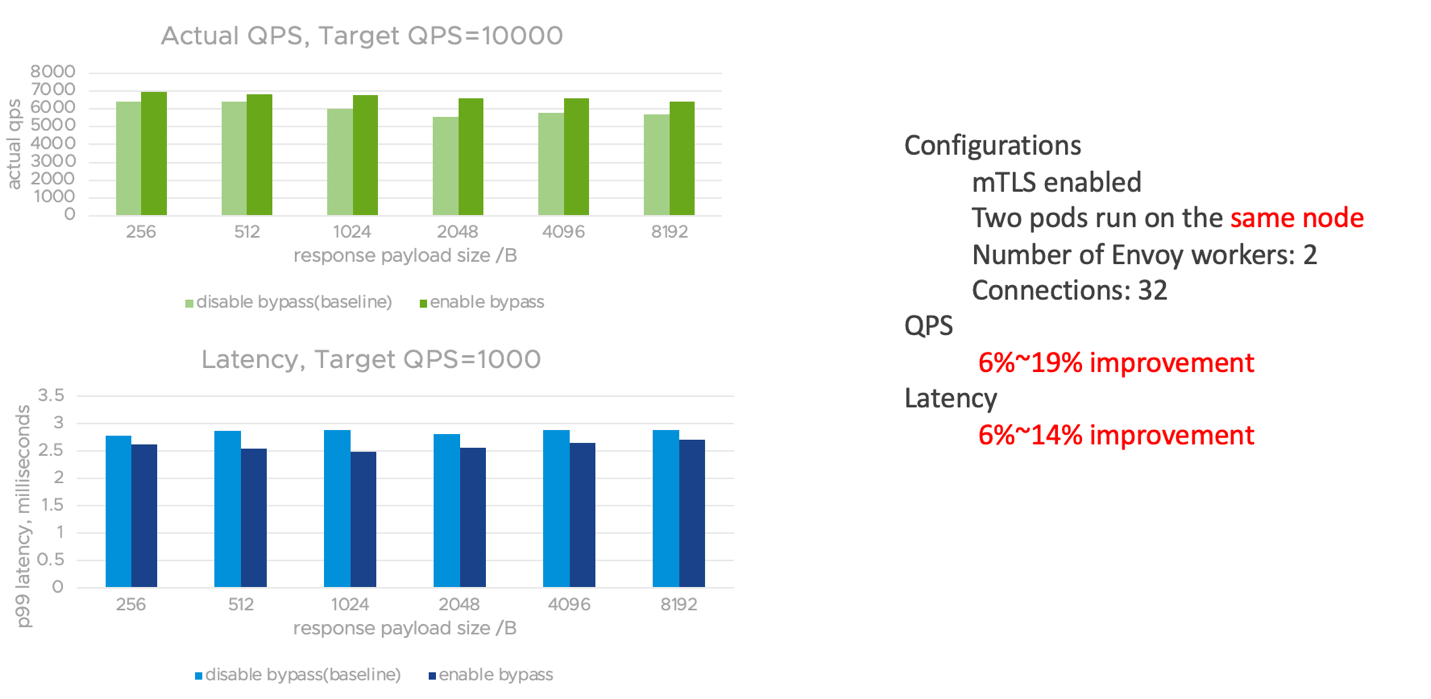
We have been testing Tanzu Service Mesh with this capability enabled in our joint lab environments and the results are impressive, both in terms of latency and QPS.
Connections Based:

Payload Based:
Deployment Model
To make the deployment model for this feature seamless with Tanzu Service Mesh, the eBPF bytecode and load scripts are packaged into a docker image and deployed as daemonset on the onboarded Kubernetes cluster.

Figure 9: Enabling TCP/IP bypass in Tanzu Service Mesh
This daemonset deployment model makes it simple to enable/disable this feature. After the pod spawns, the eBPF program is loaded into host kernel. Also, disabling this feature on Tanzu Service Mesh removes the daemonset and will cause eBPF programs unloaded from the kernel. In this manner, the data path falls back to the default iptables-based approach of Istio.
In this blog, we saw how enabling eBPF in a non-disruptive manner on existing Service Mesh (Tanzu Service Mesh, and Istio), helps in accelerating the existing data path for the same. In the next blog we will deep dive and showcase how Intel and VMware have been working together to accelerate the crypto use-cases of Tanzu Service Mesh (mutual TLS use-case) and improved the performance of asymmetric crypto operations by using Intel® AVX-512 Crypto instruction set that is available on 3rd Generation Intel Xeon Scalable Processors.
NOTE: The integration of this TCP/IP bypass feature in Tanzu Service Mesh is in development/testing phase (We are working on an experience that is simple and seamless). The underlying code for TCP/IP bypass is open source and is available on https://github.com/intel/istio-tcpip-bypass (can also be used directly with Istio) and we look forward to more contributions in this space.
References:
Demystifying Istio’s Sidecar Injection Model
Accelerate Istio Dataplane with eBPF
See the Rest of the Series
Part 2: TLS Handshake Acceleration with Tanzu Service Mesh
Part 3: Tanzu Service Mesh Security Enhancements using Confidential Computing


Comments
0 Comments have been added so far