
This is the third post in my series on Hands-on Labs behind the scenes. You can find the previous post on comparing cloud catalogs here.
To date, my biggest problem with synchronizing data between vCD instances has been the time required to export vApp templates from one cloud and import them into another. If you want to preserve vApp structure and (most) metadata, there is really only one way into or out of a vCD cloud. Simply having the VMDKs and VMX file from the backend vSphere is not enough. For those who have had to deal with these mechanisms on a regular basis, you know what I mean.
A vPod containing our base infrastructure for VMworld 2013 development looked something like the following. Most of our final vPods are quite a bit larger than this, but this is a pretty standard starting point.
| Single Site Base vPod | ||||
| VM Name | vCPU | vRAM (GB) | Disk (GB) | |
| controlcenter | 1 | 2 | 20 | |
| esx-01a | 2 | 4 | 2 | |
| esx-02a | 2 | 4 | 2 | |
| stgb-l-01a | 1 | 2 | 68 | |
| vc-l-01a | 2 | 4 | 33 | |
| vpodrouter | 1 | 0.25 | 0.25 | |
As you can see, this vPod has 9 vCPUs, and 16.25 GB RAM, and a 125.25 GB storage allocation. It contains our basic nested datacenter with AD, DNS, NTP, DHCP, one vCenter appliance, two vESXi hosts, a router to handle multiple L3 networks (vpodrouter), and an NFS appliance (stgb-l-01a) for shared storage. This pretty much embodies our smallest functional pod for the VMware Hands-on Labs. As you can see, about 2/3 the storage in the pod is allocated to the NFS datastore. We have a few nested VMs on that NFS datastore as examples that our lab teams can use, or they can remove ours and replace them with their own.
Note that not all of the space allocated within this vPod is in use: some of the space is free for lab teams use as needed, and most operating systems do not like to see completely full file systems. When then environment is not very busy and I export this base vPod from our development environment, it requires roughly 90 minutes to “prepare,” another 30 minutes to download, and produces a bundle of files that consumes roughly 36.7 GB on disk (about 30% of the vPod’s storage allocation).
Space and Time
Two hours may not sound like a lot of time until you think about managing more than a few of these vPods. Part of the reason for the long duration is that these vPods contain a lot of data. In our case, that means around 4 days just to export the catalog! Another contributor is the time needed for compression: OVF employs a compressed sparse format for VMDK files, and compressing that much data is both I/O and computationally intensive. The benefit, of course, is that there is less data to transmit over the network. Since virtual disks in this compressed format cannot be used by VMs directly, you take another hit during the import process as the VMDKs are reconstituted. Note that this is the case with other compression utilities as well: I used both WinZIP and WinRAR tools to compress 100 GB of files and both tools took at least a couple of hours, even in their fastest, lowest-compression modes. Without the compression, you would need to transfer more data over the network, which would require more time during that phase. There are no free lunches, and since I need to move the data across the network multiple times, it makes a lot of sense to take the hit up front.
For those who are curious, during my early tests, I compressed the OVF-compressed VMDKs using both WinZIP and WinRAR. Each of those processes required several additional hours and produced negligible additional compression – generally 1-3%. To me, that means the compression that OVF uses is pretty good.
Process
The process followed when vCD goes to export a vApp Template is explained very well by Chris Colotti on his blog.
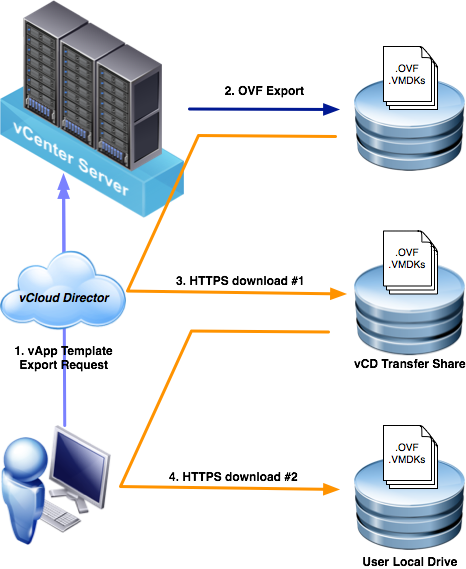 I have paraphrased and summarized the process here and have provided a diagram that I believe helps understand the multiple “hops” the data must make between the source and destination:
I have paraphrased and summarized the process here and have provided a diagram that I believe helps understand the multiple “hops” the data must make between the source and destination:
- vCloud Director invokes an OVF export on the backing vCenter Server.
- vCenter Server returns a lease, authorization, and a collection of https URLs that vCD uses to download the OVF and VMDK files from the ESXi host(s).
- vCloud Director downloads the files from the ESXi host to its transfer directory, and associates a transfer lease with these files. (The transfer directory is located on the vCD cell(s) at /opt/vmware/vcloud-director/data/transfer.)
- vCloud Director exposes a collection of https URLs that the user can use to download the OVF and VMDK files.
- When the transfer lease expires, vCloud Director deletes the files from the transfer directory.
In the diagram, you can see that the exported files make a minimum of two network transits during the export process. Actually, these files make additional network transits, some of which may not be as obvious:
- The OVF export process must write to disk during (2). Odds are that this is occurring to shared storage. Whether it is an FC or IP SAN, or NFS share, that adds another “network” transit.
- The vCD transfer share may be local storage if your vCD is implemented as a single cell. Otherwise, the vCD transfer share is an NFS share accessible by each member. Add another two network transits: one for the write during (3) and another for the read during (4).
- If you choose to write the final download to a network device like a UNC path or iSCSI mounted block device, you can add yet another network transit to the equation.
All told, you may actually fling these bits across various networks 5 or 6 times during a single export. When you are looking at a few MB, or even GB, that may not be a big deal, but for tens or hundreds of GBs, the time required can be significant. Keep in mind that your overall duration is not calculated based on the fastest or slowest links, but the sum of times required to transit each link. Also remember that the import process follows the same path in reverse!
Optimization? Automation!
After analyzing this process flow fairly extensively, I determined that there was not much I could easily do to influence the vCD export process itself. From a hardware perspective, the best I could do would be to ensure 10Gb connectivity for each of the network hops and build each storage target with the fastest possible storage. The storage part, at least, could get really expensive. Think about temporarily storing terabytes of mostly static data multiple times on premium storage. That is just not an effective use of resources. So, I focused on making the process for managing the export process as efficient as possible for our use case.
Automation is key here. Rather than firing up my web browser, navigating to the vPod I need, launching the Java export process, and waiting for the export to finish, and moving on to the next vPod, I decided to use PowerCLI. My solution saves us time setting up and babysitting the exports. Yes, the export processes still require a lot of time, but we can configure them to occur one after another in batches without the need for human intervention. When everything goes well, they export while I sleep.
To my knowledge, there is not a PowerCLI cmdlet that does what I need. When I was originally looking to solve this problem, I was going to have to write it myself. Fortunately, Clinton Kitson of EMC had written a function that got me 99% there. You can find his work at vElemental.com. I tweaked Clint’s Export-CIOvf function to perform the lossless export that I needed.
Lossless export is an option added in vCD 5.1 that preserves many characteristics of the component VMs within a vApp template. This option sacrifices some of the “openness” of OVF because it assumes the same platform for both the source and the target clouds. Since vCD is running each of my clouds, this is not an issue. Each of our vPods is deployed on an isolated vApp network in vCD, so we maintain all of the IPs, MACs, UUIDs, and other settings within the vPods: each deployment of a given vPod is identical to every other deployment of that vPod. For your lab experience to be consistent, lossless is what we need.
Code
What follows is the Export-CIOvfLossless function that I use. As mentioned previously, this function contains some fairly minor tweaks to Clint’s original.
Function Export-CIOvfLossless { <# .DESCRIPTION Export VAppTemplate while maintaining identity .EXAMPLE PS C:\> Get-CIVAppTemplate VPOD01 | Export-CIOvfLossless #> PARAM( $targetDir, [Parameter(Mandatory=$True, Position=1, ValueFromPipeline=$true)] [PSObject[]]$InputObject ) PROCESS { $InputObject | %{ if(!($_ | Get-CIView | %{ $_.Link } | where {$_.Rel -eq "download:identity"})) { try { Write-Host "Enabling download..." $_ | Get-CIView | %{ $_.EnableDownload() } } catch { Write-Error $error[0] } } $href = $_ | Get-CIView | %{ $_.Link } | where {$_.Rel -eq "download:identity"} | %{ $_.Href } if(!$targetDir) { $targetDir = $_.name } if($href) { $serverName = ($href.Split("/"))[2] $cloudServer = $global:DefaultCIServers | where {$_.Name -eq $serverName } $sessionId = $cloudServer.sessionid $webClient = New-Object system.net.webclient $webClient.Headers.Add('x-vcloud-authorization',$sessionId) if(!(Test-Path $targetDir)) { New-Item -type Directory $targetDir | out-null } $targetDir = (Get-Item $targetDir).FullName $baseHref = $href -replace "descriptor-with-id.ovf","" $webClient.DownloadFile("$href","$($targetDir)\descriptor-with-id.ovf") [xml]$xmlDescriptor = Get-Content "$($targetDir)\descriptor-with-id.ovf" $xmlDescriptor.Envelope.References.File | %{ $_.href } | %{ try { Write-Host "Downloading $($targetDir)\$($_)" $webClient.DownloadFile("$($baseHref+$_)","$($targetDir)\$($_)") } catch { Write-Host -fore red "Error downloading OVF disk named $($_)" } } } else { Write-Host -fore red "OVF Download Link Not Found" } Write-Host "Disabling download" $_ | Get-CIView | %{ $_.DisableDownload() } } } } #Export-CIOvfLossless
I wrap Export-CIOvfLossless in another function, Export-VPod, that performs a few other tasks for me:
- Write current time to the console prior to calling the export (Start Time)
- Check to see if an exported vPod with the same name already exists on disk in the specified path and, if found, ceases processing that vPod. There is no point in wasting time if someone has already done the work.
- Create a new directory to contain the exported files and change its name to match the name of the vPod it contains. This just makes sense to me, especially when trying to manage many vPods and versions.
- Write current time to the console once the call returns (End Time)
- Rename the default “descriptor-with-id.ovf” file to match the name of the vPod, keeping the “.ovf” extension.
Function Export-VPod { <# Exports a vApp Template (vPod) while preserving its identity Files are downloaded to <LibPath>\<VPodName> OVF file is named <VPodName>.ovf NOTE: vCD is case sensitive whereas PS is not. It is entirely possible to get multiple returns to a Get-CIVappTemplate XXX query (e.g. if there is "APP01" and "App01") #> PARAM( $VPods=$(throw "need -VPods"), $LibPath=$(throw "need -LibPath") ) PROCESS { Foreach ($vPod in $VPods) { $vAppPath = Join-Path $LibPath $($vPod.Name) if( Test-Path $vAppPath ) { Write "$vAppPath already exists!" Write-Host -Fore Red "Cowardly opting to exit and prevent unintentional clobbering of data!" Return } Else { mkdir $vAppPath | Out-Null } Write-Host "==>Beginning export to $vAppPath" Write-Host -Fore Green "Exporting $vPod @ $(Get-Date)" try { Export-CIOvfLossless $vPod -targetDir $vAppPath -ErrorAction Stop Move $(Join-Path $vAppPath "descriptor-with-id.ovf") $(Join-Path $vAppPath $($vPod.name + ".ovf")) Write-Host "==>Export complete $(Get-Date)" } catch { Write-Host -Fore Red "==>Failed to export" } } } } #Export-VPod
If I wanted to export all of the Hybrid Cloud vPods from my catalog to the local E:\HOL-Library directory, I would call this function as follows:
$myvpods = Get-CIVAppTemplate "HOL-HBD-13*" -Catalog HOL-Masters
Export-VPod -VPods $myvpod -LibPath E:\HOL-Library\
This would walk through the list of vPods matching the pattern and export them one at a time. If it encountered one that had already been complete, it would write a message to the console and go to the next one in the list. The Start Time and End Time are useful for reporting purposes so that I can track how long each vPod required to perform the export. This helps get a better picture of overall processing time and allows us to provide more accurate estimates for exports of future versions of this vPod.
On My Wishlist
For what it is worth, I think it would be nice if I could ask vCD for a “metadata-only” export that would give me everything I need except the VMDKs. In many cases, I think this would be helpful to those of us who would be happy to figure out how to get the VMDKs replicated via another means. Ideally, this would skip the multiple network transits for the VMDK data. An added benefit would be that the import process could also be streamlined by simply asking for paths to the “metadata-only” descriptor and replicated VMDKs rather than performing a “multi-hop” import.
What About vCloud Connector?
Depending on your needs, there may be other ways to handle synchronizing catalogs across clouds. For example, you may want look at implementing the Content Sync feature of our vCloud Connector (vCC) product. It has a nice GUI that is integrated with the vSphere Client and is specially designed handle replicating catalogs of vCD vApp templates. For our use case, however, we need a bit more control over the process than vCC offers, and we need lossless exporting. As far as other ways we manage our process, we manually determine what constitutes a valid change and when to replicate, we sometimes need to consider relative priority of templates, and we perform replication over some fairly low-bandwidth links.
There are some unique features of vCC that I think are worth mentioning, especially since not everyone has the same needs and requirements that we do:
- As of version 2.6, vCC has all features enabled in a single version and it is FREE
- vCC will preserve vApp metadata between clouds. A “normal” vCD export, including those performed via the vCD GUI and the PowerShell function in this post, will strip metadata from the vApp.
- vCC’s Offline Data Transfer feature can be used to export and data to be hosted in vCloud Hybrid Service (vCHS)
- vCC’s path-optimized replication process performs the export, transfer, and import in parallel to reduce the storage footprint and time required to transfer the template. In my experience, this generally requires fairly high bandwidth connectivity between the clouds.
- The catalog synchronization process is part of the product and is automatic. If you do not need tight control over which templates replicate and when, just let vCC handle it.
Up Next
At any rate, now that I have my export files and they are as compressed as they are going to get, they need to be replicated to the other clouds. That, my friends, is the subject of my next post…







