

The Terraform VMware Cloud Director Provider v3.11.0 now supports installing and managing Container Service Extension (CSE) 4.1, with a new set of improvements, the new vcd_rde_behavior_invocation data source and updated guides for VMware Cloud
Director users to deploy the required components.
In this blog post, we will be installing CSE 4.1 in an existing VCD and creating and managing a TKGm cluster.
Preparing the installation
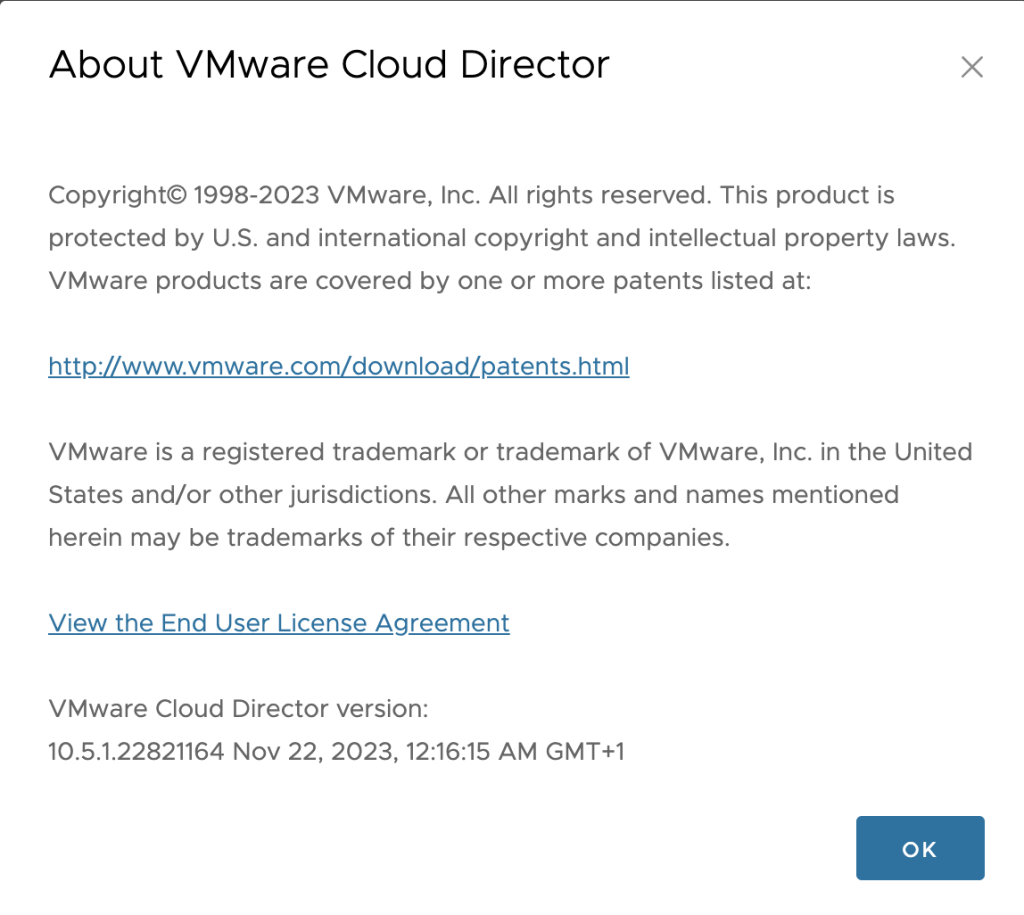
First of all, we must make sure that all the prerequisites listed in the Terraform VCD Provider documentation are met. CSE 4.1 requires at least VCD 10.4.2, we can check our VCD version in the popup that shows up by clicking the About option inside the help “(?)” button next to our username in the top right corner:
Check that you also have ALB controllers available to be consumed from VMware Cloud Director, as the created clusters require them for load-balancing purposes.
Step 1: Installing the prerequisites
The first step of the installation mimics the UI wizard step in which prerequisites are created:

We will do this exact step programmatically with Terraform. To do that, let’s clone the terraform-provider-vcd repository so we can download the required schemas, entities, and examples:
|
1 2 3 4 |
git clone https://github.com/vmware/terraform-provider-vcd.git cd terraform-provider-vcd git checkout v3.11.0 cd examples/container-service-extension/v4.1/install/step1 |
If we open 3.11-cse-install-2-cse-server-prerequisites.tf we can see that these configuration files create all the RDE framework components that CSE uses to work, consuming the schemas that are hosted in the GitHub repository, plus all the rights and roles that are needed. We won’t customize anything inside these files, as they create the same items as the UI wizard step shown in the above screenshot, which doesn’t allow customization either.
Now we open 3.11-cse-install-3-cse-server-settings.tf, this one is equivalent to the following UI wizard step:

We can observe that the UI wizard allows us to set some configuration parameters, and if we look to terraform.tfvars.example we will observe that the requested configuration values match.
Before applying all the Terraform configuration files that are available in this folder, we will rename terraform.tfvars.example to terraform.tfvars, and we will set the variables with correct values. The defaults that we can see in variables.tf and terraform.tfvars.example match with those of the UI wizard, which should be good for CSE 4.1. In our case, our VMware Cloud Director has complete Internet access, so we are not setting any custom Docker registry or certificate here.
We should also take into account that the terraform.tfvars.example is asking for a username and password to create a user that will be used to provision API tokens for the CSE Server to run. We also leave these as they are, as we like the "cse_admin" username.
Once we review the configuration, we can safely complete this step by running:
|
1 2 |
terraform init terraform apply |
The plan should display all the elements that are going to be created. We complete the operation (by writing yes to the prompt) so the first step of the installation is finished. This can be easily checked in the UI as now the wizard doesn’t ask us to complete this step, instead, it shows the CSE Server configuration we just applied:
Step 2: Configuring VMware Cloud Director and running the CSE Server
We move to the next step, which is located at examples/container-service-extension/v4.1/install/step2 of our cloned repository.
|
1 |
cd examples/container-service-extension/v4.1/install/step2 |
This step is the most customizable one, as it depends on our specific needs. Ideally, as the CSE documentation implies, there should be two Organizations: Solutions Organization and Tenant Organization, with Internet access so all the required Docker images and packages can be downloaded (or with access to an internal Docker registry if we had chosen a custom registry in the previous step).
We can investigate the different files available and change everything that doesn’t fit with our needs. For example, if we already had the Organization VDCs created, we could change from using resources to using data sources instead.
In our case, the VMware Cloud Director appliance where we are installing CSE 4.1 is empty, so we need to create everything from scratch. This is what the files in this folder do, they create a basic and minimal set of components to make CSE 4.1 work.
Same as before, we rename terraform.tfvars.example to terraform.tfvars and inspect the file contents so we can set the correct configuration. As we mentioned, setting up the variables of this step depends on our needs and how we want to set up the networking, the NSX ALB, and which TKGm OVAs we want to provide to our tenants. We should also be aware that some constraints need to be met, like the VM Sizing Policies that are required for CSE to work being published to the VDCs, so let’s read and understand the installation guide for that purpose.
Once we review the configuration, we can complete this step by running:
|
1 2 |
terraform init terraform apply |
Now we should review that the plan is correct and matches to what we want to achieve. It should create the two required Organizations, our VDCs, and most importantly, the networking configuration should allow Internet traffic to retrieve the required packages for the TKGm clusters to be provisioned without issues (remember that in the previous step, we didn’t set any internal registry nor certificates). We complete the operation (by writing yes to the prompt) so the second step of the installation is finished.
We can also double-check that everything is correct in the UI, or do a connectivity test by deploying a VM and using the console to ping an outside-world website.

Cluster creation with Terraform
Given that we have finished the installation process and we still have the cloned repository from the previous steps, we move to examples/container-service-extension/v4.1/cluster.
cd examples/container-service-extension/v4.1/cluster
The cluster is created by the configuration file 3.11-cluster-creation.tf, by also using the RDE framework. We encourage the readers to check both the vcd_rde documentation and the cluster management guide before proceeding, as it’s important to know how this resource works in Terraform, and most importantly, how CSE 4.1 uses it.
We will open 3.11-cluster-creation.tf and inspect it, to immediately see that it uses the JSON template located at examples/container-service-extension/v4.1/entities/tkgmcluster.json.template. This is the payload that the CSE 4.1 RDE requires to initialize a TKGm cluster. We can customize this JSON to our needs, for example, we will remove the defaultStorageClassOptions block from it as we won’t use storage in our clusters.
The initial JSON template tkgmcluster.json.template looks like this now:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
{ "apiVersion": "capvcd.vmware.com/v1.1", "kind": "CAPVCDCluster", "name": "${name}", "metadata": { "name": "${name}", "orgName": "${org}", "site": "${vcd_url}", "virtualDataCenterName": "${vdc}" }, "spec": { "vcdKe": { "isVCDKECluster": true, "markForDelete": ${delete}, "forceDelete": ${force_delete}, "autoRepairOnErrors": ${auto_repair_on_errors}, "secure": { "apiToken": "${api_token}" } }, "capiYaml": ${capi_yaml} } } |
There’s nothing else that we can customize there, so we leave it like that.
The next thing that we notice is that we need a valid CAPVCD YAML, we can download it from here. We’ll deploy a v1.25.7 Tanzu cluster, so we download this one to start preparing it.
We open it with our editor and add the required snippets as stated in the documentation. We start with the kind: Cluster blocks that are required by the CSE Server to provision clusters:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: cluster.x-k8s.io/v1beta1 kind: Cluster metadata: name: ${CLUSTER_NAME} namespace: ${TARGET_NAMESPACE} labels: # We add this block cluster-role.tkg.tanzu.vmware.com/management: "" tanzuKubernetesRelease: ${TKR_VERSION} tkg.tanzu.vmware.com/cluster-name: ${CLUSTER_NAME} annotations: # We add this block TKGVERSION: ${TKGVERSION} # ... |
We added the two labels and annotations blocks, with the required placeholders TKR_VERSION, CLUSTER_NAME, and TKGVERSION. These placeholders are used to set the values via Terraform configuration.
Now we add the Machine Health Check block, which will allow to use one of the new powerful features of CSE 4.1, that remediates nodes in failed status by replacing them, enabling cluster self-healing:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
apiVersion: cluster.x-k8s.io/v1beta1 kind: MachineHealthCheck metadata: name: ${CLUSTER_NAME} namespace: ${TARGET_NAMESPACE} labels: clusterctl.cluster.x-k8s.io: "" clusterctl.cluster.x-k8s.io/move: "" spec: clusterName: ${CLUSTER_NAME} maxUnhealthy: ${MAX_UNHEALTHY_NODE_PERCENTAGE}% nodeStartupTimeout: ${NODE_STARTUP_TIMEOUT}s selector: matchLabels: cluster.x-k8s.io/cluster-name: ${CLUSTER_NAME} unhealthyConditions: - type: Ready status: Unknown timeout: ${NODE_UNKNOWN_TIMEOUT}s - type: Ready status: "False" timeout: ${NODE_NOT_READY_TIMEOUT}s --- |
Notice that the timeouts have an s as the values introduced during installation were in seconds. If we hadn’t put the value in seconds, or we put the value like 15m, we can remove the s suffix from these block options.
Let’s add the last parts, which are most relevant when specifying custom certificates during the installation process. In kind: KubeadmConfigTemplate we must add the preKubeadmCommands and useExperimentalRetryJoin blocks under the spec > users section:
|
1 2 3 4 |
preKubeadmCommands: - mv /etc/ssl/certs/custom_certificate_*.crt /usr/local/share/ca-certificates && update-ca-certificates useExperimentalRetryJoin: true |
In kind: KubeadmControlPlane we must add the preKubeadmCommands and controllerManager blocks inside the kubeadmConfigSpec section:
|
1 2 3 4 5 6 |
preKubeadmCommands: - mv /etc/ssl/certs/custom_certificate_*.crt /usr/local/share/ca-certificates && update-ca-certificates controllerManager: extraArgs: enable-hostpath-provisioner: "true" |
Once it is completed, the resulting YAML should be similar to the one already provided in the examples/cluster folder, cluster-template-v1.25.7.yaml, as it uses the same version of Tanzu and has all of these additions already introduced. This is a good exercise to check whether our YAML is correct before proceeding further.
After we review the crafted YAML, let’s create a tenant user with the Kubernetes Cluster Author role. This user will be required to provision clusters:
|
1 2 3 4 5 6 7 8 9 |
data "vcd_global_role" "k8s_cluster_author" { name = "Kubernetes Cluster Author" } resource "vcd_org_user" "cluster_author" { name = "cluster_author" password = "dummyPassword" # This one should be probably a sensible variable and a bit safer. role = data.vcd_global_role.k8s_cluster_author.name } |
Now, we can complete the customization of the configuration file 3.11-cluster-creation.tf by renaming terraform.tfvars.example to terraform.tfvars and configuring the parameters of our cluster. Let’s check ours:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
vcd_url = "https://..." cluster_author_user = "cluster_author" cluster_author_password = "dummyPassword" cluster_author_token_file = "cse_cluster_author_api_token.json" k8s_cluster_name = "example" cluster_organization = "tenant_org" cluster_vdc = "tenant_vdc" cluster_routed_network = "tenant_net_routed" control_plane_machine_count = "1" worker_machine_count = "1" control_plane_sizing_policy = "TKG small" control_plane_placement_policy = "\"\"" control_plane_storage_profile = "*" worker_sizing_policy = "TKG small" worker_placement_policy = "\"\"" worker_storage_profile = "*" disk_size = "20Gi" tkgm_catalog = "tkgm_catalog" tkgm_ova_name = "ubuntu-2004-kube-v1.25.7+vmware.2-tkg.1-8a74b9f12e488c54605b3537acb683bc" pod_cidr = "100.96.0.0/11" service_cidr = "100.64.0.0/13" tkr_version = "v1.25.7---vmware.2-tkg.1" tkg_version = "v2.2.0" auto_repair_on_errors = true |
We can notice that control_plane_placement_policy = "\"\"", this is to avoid errors when we don’t want to use a VM Placement Policy. We can check that the downloaded CAPVCD YAML forces us to place double quotes on this value when it is not used.
The tkr_version and tkg_version values were obtained from the already provided in the documentation.
Once we’re happy with the different options, we apply the configuration:
|
1 2 |
terraform init terraform apply |
Now we should review the plan as much as possible to prevent mistakes. It should create the vcd_rde resource with the elements we provided.
We complete the operation (by writing yes to the prompt) so the cluster should start getting created. We can monitor the process either in UI or with the two outputs provided as an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
locals { k8s_cluster_computed = jsondecode(vcd_rde.k8s_cluster_instance.computed_entity) being_deleted = tobool(jsondecode(vcd_rde.k8s_cluster_instance.input_entity)["spec"]["vcdKe"]["markForDelete"]) || tobool(jsondecode(vcd_rde.k8s_cluster_instance.input_entity)["spec"]["vcdKe"]["forceDelete"]) has_status = lookup(local.k8s_cluster_computed, "status", null) != null } output "computed_k8s_cluster_status" { value = local.has_status && !local.being_deleted ? local.k8s_cluster_computed["status"]["vcdKe"]["state"] : null } output "computed_k8s_cluster_events" { value = local.has_status && !local.being_deleted ? local.k8s_cluster_computed["status"]["vcdKe"]["eventSet"] : null } |
Then we can do terraform refresh as many times as we want, to monitor the events with:
|
1 2 |
terraform output computed_k8s_cluster_status terraform output computed_k8s_cluster_events |
Once computed_k8s_cluster_status states provisioned, this step will be finished and the cluster will be ready to use. Let’s retrieve the Kubeconfig, which in CSE 4.1 is done completely differently than in 4.0, as we are required to invoke a Behavior to get it. In 3.11-cluster-creation.tf we can see a commented section that has a vcd_rde_behavior_invocation data source. If we uncomment these and do another terraform apply, we should be able to get the Kubeconfig by running
|
1 |
terraform output kubeconfig |
We can save it to a file to start interacting with our cluster and kubectl.
Cluster update
Example use case: we realized that our cluster is too small, so we need to scale it up. We’ll set up 3 worker nodes.
To update it, we need to be sure that it’s in provisioned status. For that, we can use the same mechanism that we used when the cluster creation started:
|
1 |
terraform output computed_k8s_cluster_status |
This should display provisioned. If that is the case, we can proceed with the update.
As with the cluster creation, we first need to understand how the vcd_rde resource works to avoid mistakes, so it is encouraged to check both the vcd_rde documentation and the cluster management guide before proceeding. The important idea is that we must update the input_entity argument with the information that CSE saves in the computed_entity attribute, otherwise, we could break the cluster.
To do that, we can use the following output that will return the computed_entity attribute:
|
1 2 3 |
output "computed_k8s_cluster" { value = vcd_rde.k8s_cluster_instance.computed_entity # References the created cluster } |
Then we run this command to save it to a file for a better reading:
|
1 |
terraform output -json computed_k8s_cluster > computed.json |
Let’s open computed.json for inspection. We can easily see that it looks pretty much the same as tkgmcluster.json.template but with the addition of a big "status" object that contains vital information about the cluster. This must be sent back on updates, so we copy the whole "status" object as it is and we place it in the original tkgmcluster.json.template.
After that, we can change worker_machine_count = 1 to worker_machine_count = 3 in the existing terraform.tfvars, to complete the update process with:
|
1 |
terraform apply |
Now it is crucial to verify and be sure that the output plan shows that the "status" is being added to the input_entity payload. If that is not the case, we should stop the operation immediately and check what went wrong. If "status" is visible in the plan as being added, you can complete the update operation by writing yes to the prompt.
Cluster deletion
The main idea of deleting a TKGm cluster is that we should not use terraform destroy for that, even if that is the first idea we have in mind. The reason is that the CSE Server creates a lot of elements (VMs, Virtual Services, etc) that would be in an “orphan” state if we just delete the cluster RDE. We need to let the CSE Server do the cleanup for us.
For that matter, the vcd_rde present in 3.11-cluster-creation.tf contains two special arguments, that mimic the deletion option from UI:
|
1 2 |
delete = false # Make this true to delete the cluster force_delete = false # Make this true to forcefully delete the cluster |
To trigger an asynchronous deletion process we should change them to true and execute terraform apply to perform an update. We must also introduce the most recent "status" object to the tkgmcluster.json.template when applying, pretty much like in the update scenario described in the previous section.
Final thoughts
We hope you enjoyed the process of installing CSE 4.1 in your VMware Cloud Director appliance. For a better understanding of the process, please read the existing installation and cluster management guides.

