

In a recent panel discussion titled “Top 5 Criteria to Choose the Right Platform for Your Modern Workloads,” members from the VMware Cloud Foundation (VCF) team and Forrester analyst Brent Ellis explored how enterprises evaluate infrastructure platforms for modern, hybrid workloads. The conversation focused on five priorities: security and resilience, scalability, operational simplicity, developer enablement, and innovation.
Forrester’s Ellis emphasized that organizations are seeking standardization in platform engineering, with platforms treating VMs and Kubernetes workloads equally. This is a core design principle of VMware Cloud Foundation 9.0.
This discussion laid the groundwork for why platform choices matter, especially for private clouds. Let’s now dive deeper into five key principles for successfully designing and operating modern applications, using best practices from NIST, CNCF, Google SRE, and ITIL.
Framework for Building, Running, and Managing Apps for the Next Decade
Modern applications are no longer confined to virtual machines, containers, or cloud accounts. They span runtimes, data centers, enterprise edges, and multiple clouds, each with their own operational requirements, all stitched together with an API and some level of automation. The challenge isn’t simply where those applications run, but how organizations can ensure they are secure, resilient, observable, and scalable.
Over the past decade, the industry has converged on a set of architectural and operational standards that define what it means to be modern. These standards go beyond product features. They are engineering principles rooted in open standards, SRE practices, and the hands-on experience of practitioners who have deployed applications at scale.
1. Cloud Native, Composable, API-First Architecture
We expect modern applications to be elastic, resilient, and heavily lifecycled. Industry definitions of “cloud native” all converge on the same basic ideas: applications built to take advantage of cloud infrastructure through loosely coupled services, APIs, and managed services.
The core architectural principle behind cloud native apps is composability, which involves splitting capabilities into independently deployable services with well-defined APIs (or events). At its core, composability means individual capabilities are treated as units you can wire together while not necessarily knowing the internals. In enterprise apps, each capability is aligned with a business function.
At the app layer, those capabilities can be something like Customer Profile, Payment Processing, Inventory, Recommendation Engine, Chatbot, etc. with each of these capabilities:
- Exposed via an API and accompanied by a declarative spec.
- Independently deployable (separate/unique lifecycle).
- Versioned and governed as a product (each have their own SLAs, docs, owner).
At the platform layer, capabilities look like:
- “Give me a Kubernetes cluster with this topology in this region.”
- “Provision a VM from a gold image, in this zone, using this storage policy.”
- “Provision a MS SQL database with persistent storage.”
- “Attach a load balancer and VIP in front of this app.”
Composability lets you lifecycle one capability or service without redeploying the entire app and all its dependencies. You can scale components independently, isolate failures, and use varying code and/or runtimes where it makes sense. Composability turns the platform into a programmable catalog.
API-First Architecture
API-first design is what makes this composability reliable. Following this discipline, dev teams define the API spec (or Kubernetes CRD) and functional details for their respective services up front. This is referred to as the contract. Services are subsequently integrated via those contracts – and not by directly reaching into an adjacent service’s database or internal implementations.
From a platform perspective, VMware Cloud Foundation (VCF) 9.0 aligns with this model by making it strongly API-first. VCF exposes its native services via API-based interfaces and invokes them to integrate the many moving parts that come together to deliver the whole. That means the same CI/CD or GitOps tooling used for application code can programmatically provision workload domains, clusters, networks, storage, and blueprints.
2. Declarative, GitOps-Driven Delivery and Operations
Over the last 3-4 years, the industry has largely settled on declarative configuration with continuous reconciliation as the baseline for provisioning and lifecycling modern applications. That baseline is what spawned GitOps. CNCF’s OpenGitOps initiative calls out four core principles:
- Declarative – describe the entire system declaratively
- Versioned and Immutable – store desired state in Git
- Pulled Automatically – use software agents to reconcile
- Continuously Reconciled – observe and reapply desired state on drift
In GitOps, Git is the source of truth for infrastructure and application desired state, with agents continuously reconciling live systems to that state.
Adopting a GitOps methodology provides measurable benefits – reproducible “rubber stamped” environments, simpler rollbacks, full change audit history, and a natural integration point for policy-as-code, just to name a few. A bonus outcome for regulated environments is auditability, especially when combined with DevSecOps practices.
The risks of ignoring this are also clear – rogue environments, manual hotfixes, fragile pipelines, and security blind spots around “who changed what, where, and when”.
A CNCF statistic published in 2022 shows mature cloud-native organizations were roughly 4x more likely to follow GitOps practices than less mature peers.
A classic example is a banking app running on Kubernetes in multiple regions. All Kubernetes objects, network policies, and even some cloud-side resources are declared and stored in the Git repo of choice. New code promotions flow from dev → staging → prod via pull requests. A GitOps controller (e.g. Argo CD) continuously applies changes and reports any configuration drift.
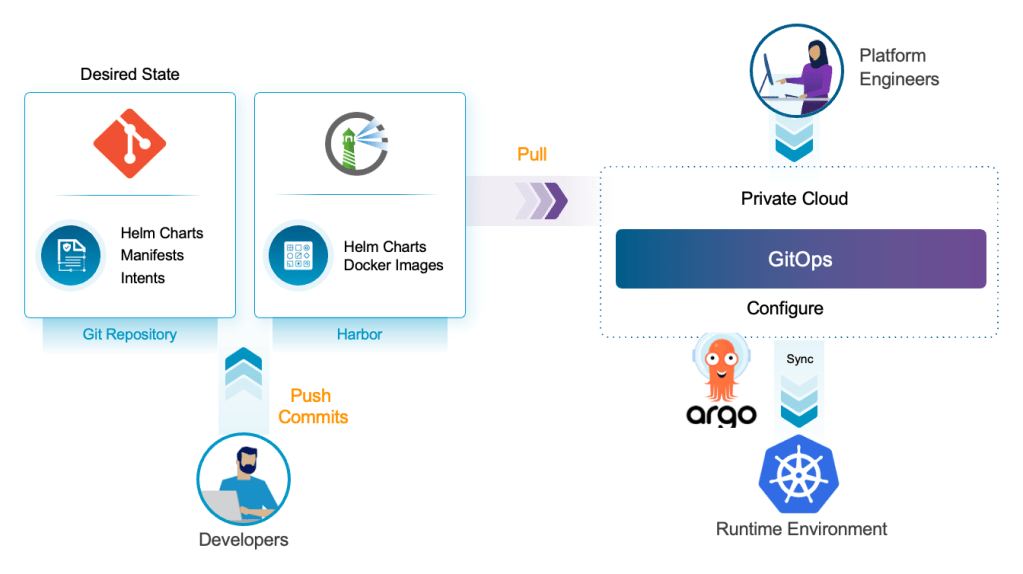
With this setup, audit teams can inspect Git history rather than chasing code knowledge, and rollbacks are one commit away rather than a pandora’s box of emergency runbooks and shell scripts. A key metric to measure success comes in the form of change failure rate and mean time to restore (MTTR). The lower the MTTR the better.
VCF 9.0 is essentially a GitOps playground for private cloud. The unified consumption interface means developers and platform engineers can hit a single endpoint using IaC (e.g. YAML, Terraform) or REST to stand up everything from target workload domains to database stacks and Private AI services. Follow that up with a VCF Automation blueprint that provisions Namespaces, VMs, VKS clusters, and load balancers declaratively.
From there Argo CD treats VKS clusters as any other conformant Kubernetes target, pulling application manifests from Git and reconciling namespaces, deployments, services, and policies. This is where VCF 9.0 really shines as a modern app platform – it lets you run your private cloud with the same declarative, Git-centric operating model that the CNCF ecosystem has proven out in public cloud.
3. Observability and Closed-Loop Automation
Apps and their respective infrastructure services will continuously generate a vast amount of diverse telemetry data – metrics, logs, traces, events – all of which have to be collected, correlated and translated into usable information.
Telemetry data should be used in a systematic way to drive decisions rather than just debugging outages. Service Level Objectives (SLOs) are how you translate all that telemetry into information the business actually cares about. Instead of “CPU is high” or “we’re seeing latency”, SLOs define user-centric objectives like “99.9% of account inquiries consistently complete under 500ms”. Or not. SLOs also determine an allowable tolerance for failure while still meeting expectations.
SLOs give you a way to decide when to push nice-to-have features versus investing in reliability (e.g. bug fixes) and the user experience. These can be wired into policies that automate decisions – scaling an app tier, pausing rollouts, triggering a rollback, changing backlog priorities, etc.
Tooling and Instrumentation
Ensuring a consistent rollout of telemetry collectors is also critical. Fortunately, this can be streamlined using the same GitOps processes adopted for rolling out code. Metrics pipelines, dashboards, alert rules, SLO definitions, and runbooks can all live in Git the same way your manifests and blueprints do.
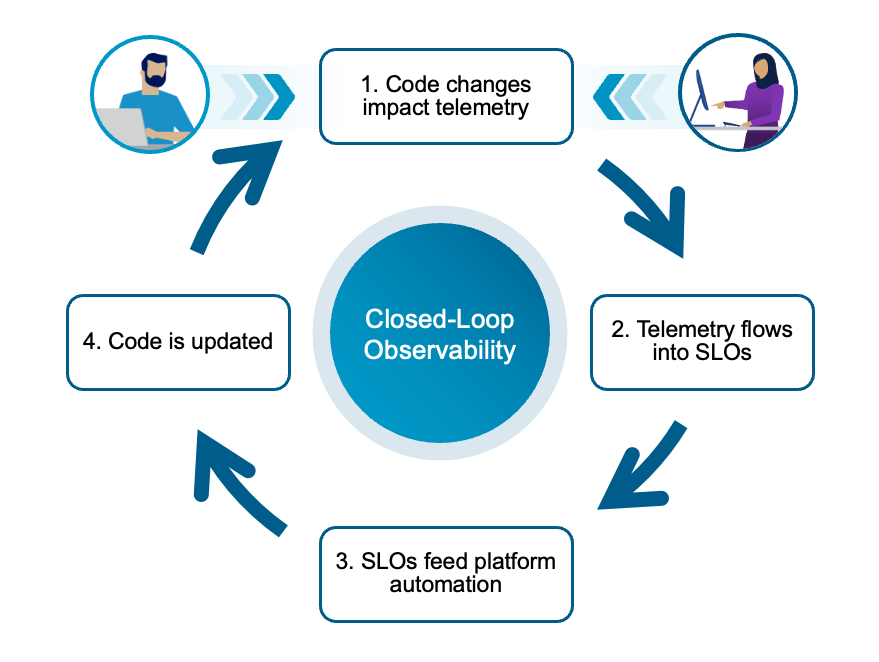
GitOps controllers and CI/CD pipelines configure telemetry collectors (e.g. Prometheus, OpenTelemetry agents), wire them to your cluster and VM workloads, and push alert configs into your observability platform. This enables a versioned, declarative, and testable telemetry strategy that can be updated and rolled out just like any code. When combined with the observability data, you get the closed loop.
VCF 9.0 provides a feedback loop between observability and automation. Diagnostic findings, health scores, and drift events from VCF Operations can be exposed as data sources for VCF Automation workflows. For example, a repeatedly violated SLO on a particular service tier might kick off a capacity planning workflow or open a change request to scale out a VKS worker pool or update the backing vSAN policy.
Because all of this is exposed through VCF’s APIs, you can build “observability-driven GitOps” where telemetry and SLO state influence automation tasks. This can include code promotion, scaling, infra changes, etc. For GitOps and platform engineers, this is truly the endgame for observability – a closed loop where data drives action across the entire VCF stack. Not just pretty graphs.
4. Zero-Trust Security, Compliance, and Resilience by Design
Zero-trust in the modern app context starts from a blatant assumption – nothing is trusted just because of where it exists in the stack or how it got there. Not the code, pod, node, network, volume, or user. Every request must be explicitly authenticated, authorized, and inspected, and lateral movement must be tightly constrained.
CNCF’s security whitepaper and recent Kubernetes security guidance both stress that in microservice architectures the real perimeter is the workload itself, and that zero trust is implemented through layers of identity, policy, and continuous verification, not a single magical firewall. In practice, that means workload identity, strong auth at every hop, granular network segmentation, and aggressive least-privilege for pods, service accounts, and Git access.
For GitOps, zero-trust only works if it’s declarative and automated. Identity, network policies, pod security restrictions, and admission policies all need to live in Git alongside application manifests and platform configs while adjacent services ensure only signed, policy-compliant workloads are reconciled into Kubernetes clusters.
VCF and Zero-Trust
While there certainly is a lot to consider, it doesn’t have to be difficult. VCF 9.0 provides a comprehensive security stack to implement Zero-Trust. At the network layer, VCF Networking (NSX) provides micro-segmentation and distributed firewalling down to per-VM/per-vNIC granularity, and with the addition of vDefend advanced service, it adds IDS/IPS and malware prevention to enforce zero-trust policies across east–west traffic. The new Virtual Private Cloud (VPC) constructs let you carve out isolated, multi-tenant network environments with custom routing and security policies, which is essentially an implementation of zero trust at the domain (or VPC) boundary. And at the application runtime layer, VKS can enforce Kubernetes network and cluster-level policies to keep pod-to-pod communication tightly controlled, aligning with CNCF’s guidance that network policy is one of the core zero-trust controls in Kubernetes.
5. Platform Engineering as a Foundation
Of all the principles outlined in this article, Platform Engineering stands out as the most transformative for an organization building and managing modern applications. Platform engineering is the discipline of designing and building toolchains and workflows that enable self-service capabilities for developers. In some sense, Platform Engineering is the evolution (or result) of traditional DevOps, moving from abstract methodologies to a more concrete deliverable, such as laying the groundwork for the Internal Developer Platform (IDP).
The goal of Platform Engineering is not to create infrastructure barriers or return to the days of rigid IT operations. Instead, it is designed to reduce the developer’s cognitive load – and associated burnout – commonly brought on by DevOps adoption. Rather than expecting every developer to understand the unique intricacies of a particular modern app platform – runtime, data services, networking, security, enterprise-mandated specifics – in order the build/run their apps, the Platform Engineering team builds an IDP that provides agreed-upon “Golden Paths” (aka “Paved Roads”) for consumption. A Golden Path is an opinionated, governed, and automated workflow for building and deploying an application in a given environment. These are standardized routes to production abstract complexity while still providing the desired developer autonomy.
VCF 9.0 provides all the building blocks to actually implement these golden paths with familiar tools and services:
- VCF Automation was reimagined to be the “platform as a product” engine. Blueprints let PE’s define complex application and service topologies in a UI or declaratively.
- Those blueprints can then be published into a self-service catalog so project users can request complex environments with a single action or API call.
- vSphere Kubernetes Service (VKS) plugs into this as the Kubernetes runtime, giving platform teams a conformant, lifecycle-managed cluster that can be consumed directly from VCF Automation or programmatically.
- VMware Data Services Manager (DSM) and VCF’s built-in networking and ingress services provide the parts to offer “abc cluster”, “xyz database”, and “123 app stack” as distinct catalog items to developers.
- VCF’s broad support for GitOps and extensive open source tooling ensures developers are able to accomplish their tasks using familiar tools and services.
Summary
The provisioning, running, and management of modern applications requires a radical departure from the manual, ticket-driven processes of the past. The five critical principles highlighted here – Composable architecture, Declarative GitOps, Observability and Closed-Loop Automation, Zero-Trust Security, and Platform Engineering – form an interlocking framework that allows enterprises to survive and thrive in a software-defined world.
VCF 9.0 serves as a technological manifestation of these principles, delivering a unified private cloud platform that enables the “Platform as a Product” model. By leveraging VCF 9.0 to build robust Internal Developer Platforms, organizations can achieve the elusive balance of developer velocity and enterprise governance.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.


