

Implement Private AI
What does it mean to “implement Private AI” as one or more use cases on the VMware Cloud Foundation platform?
This second blog article in the series on Private AI use cases provides more examples of what it means to “Implement Private AI”. These examples have already proven to be valuable to the business at Broadcom, giving you more confidence that similar use cases can be achieved with your VCF installation on your own premises. We looked at two use-cases in part 1 and here in part 2 we look at two more. The set of use cases is fully expected to expand as adoption takes off in generative AI.
The use cases described in these articles for deploying VMware Private AI Foundation with NVIDIA are:
1. Build a (back-office) chatbot to help customer-facing representatives deal with sensitive company data in a contact center or back-office scenario (part 1)
2. Provide a coding assistant to software engineers to help develop their applications (part 1)
3. Use document summarization techniques to help employees in their tasks of understanding existing company-private content or for creating new content (part 2)
4. Create an internal hosting portal for foundation models from the open-source community such that data scientists can easily choose different models to find the best fit for their purpose (part 2)
As a reminder, here is a brief look at the VMware Private AI Foundation with NVIDIA architecture layout. This shows the various components from both VMware (seen in the blue layer below, as an advanced service on VCF) and from NVIDIA (the green layer, the NVIDIA AI Enterprise). The VMware Private AI Foundation with NVIDIA Advanced Service is a general available product from Broadcom as of May 2024. You can think of the advanced service as an extension to the core VCF platform that is specialized for implementing Private AI infrastructure and applications on VCF.
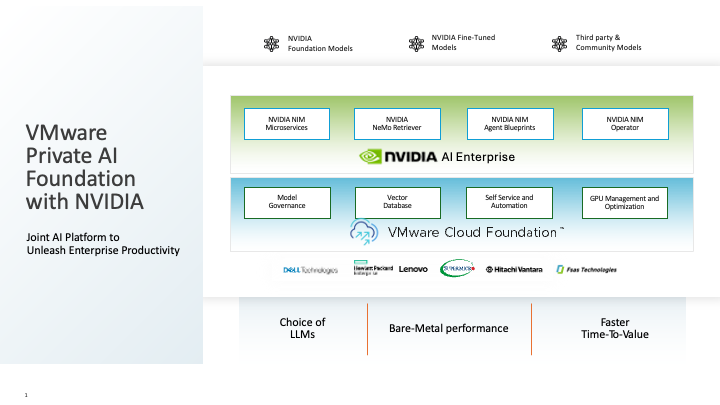
Figure 1: The VMware Private AI Foundation with NVIDIA architecture
We now look at example use cases #3 and #4 to follow on from the earlier examples given. Like the first two use cases in part 1, these use case applications are implemented internally at Broadcom today for our own employee use. They can access private data to the company and they include models that we have tested internally for our own use.
Use Case 3: A Document Summarizer Facility
How many times in your work day have you been faced with a list of various PDF, Word documents or websites that are internal and relevant to your current business question, but you cannot digest them all in a reasonable time? Public search engines and models do not have access to private data at training time and therefore cannot give you the concise answer that you need.
A document summarizer that gives you a few sentences or paragraphs that sum up the key content in an appropriate way, based on need, would be an ideal tool to have. A search tool in a browser does not quite make the grade for this purpose.
Large Language Models do a great job of these text summarization tasks. We can supply a set of PDF documents to a friendly browser-based private AI tool that takes the documents, indexes their content in chunks and ingests them into a database that readies them for querying. Underlying the internal Summarizer application there are several models including Llama 3 70B and Mixtral 8x7B. The particular model used can be chosen by the end user on each request. Here is a view of the types of choices the user can make for handling their documents.

Notice the parameters that the user can change like the chunk size in tokens, the model type for analyzing the content and the prompts that apply by default (on the right side panel). These are all configurable by the user.
Once that document data (or set of documents) is ingested into the Summarizer’s database, we can then ask any question we would like to in natural language and particularly ask for a summary of one or more documents. Once processed, the summary for your documents is persisted, so that you can go back to it later on. A summarizer application for your business data that allows documents to be uploaded to the underlying vector database can look like this one. In the case shown below, we asked for a summary of a public technical paper on the LLM topic and the summary is shown in the right hand pane alongside the original PDF document. This is just the beginning of an interaction you can now have with these summarized documents. The summary alone is very useful in saving my time to get a grasp of the core messages in this technical document.
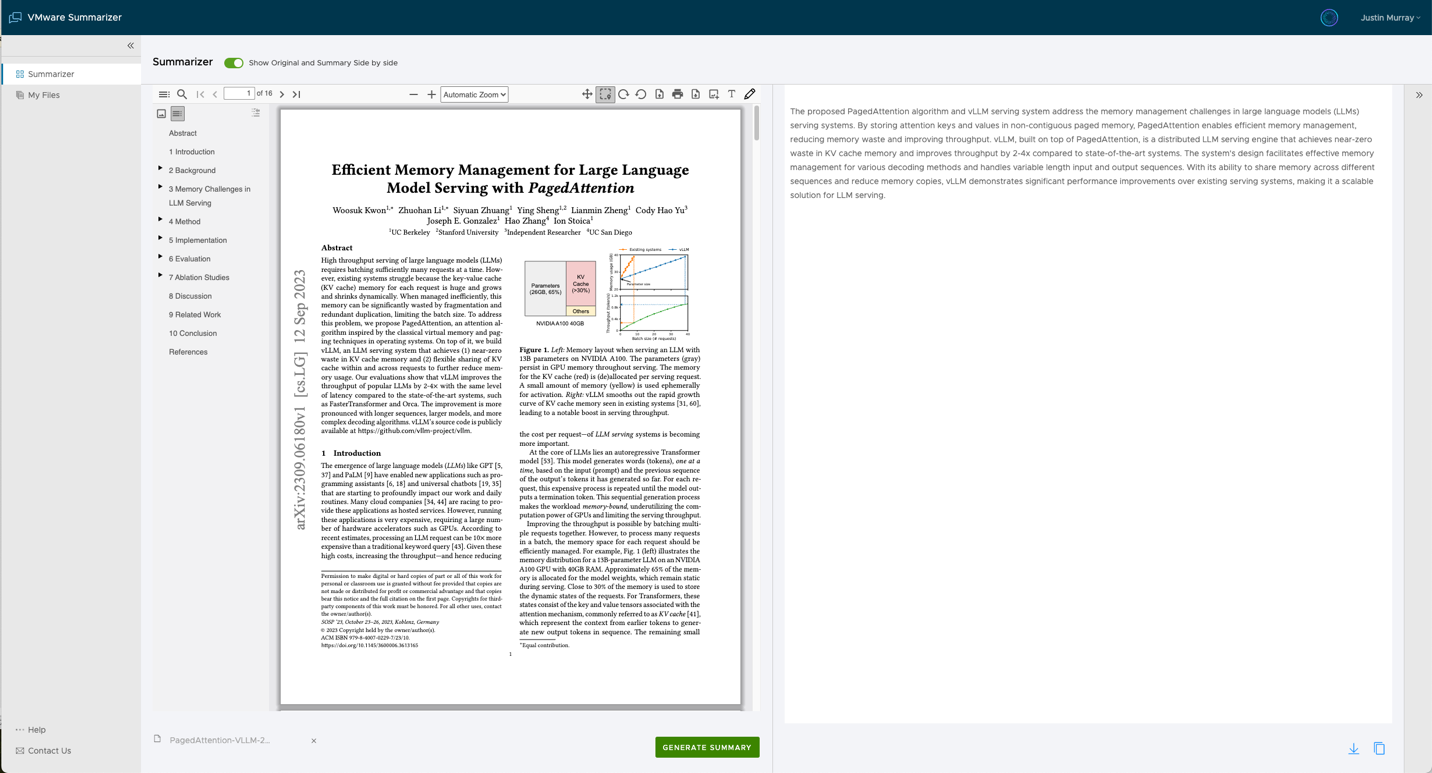
Figure 2: An example of a document summarizer in use with a technically detailed PDF document
While RAG-based systems like vAQA (the virtual advanced question and answer system – mentioned in the first use case in part 1) are designed for questions involving a large corpus of data, the summarizer here is for chatting with a single (or small set) of documents that may not be added to the full set of documents stored in the vector database supporting a system like vAQA. Think of the summarizer as a private version of RAG for a single user.
This code for the Summarizer application is open sourced by Broadcom to give you a head start on your own work in this area. You can find more information on this page.
How VMware Private AI Foundation with NVIDIA enables the creation of a document summarizer
- The first part of the document summarizer design is the creation of indexed sections or chunks of the input document that will make it easier for the LLM system to deal with it. This is done using an embeddings model. Examples of embeddings models are found in the Retriever NIM set that is part of the NVIDIA AI Enterprise product layer within the architecture shown in Figure 1. That Retriever is deployed as a container either in a Docker context within a Deep Learning VM, or as a pod in a Kubernetes cluster. The Retriever uses a model of its own, the Embedding model, and that model is hosted and run by the NIM.
- The vector database that is needed to store the indexed chunks of the incoming documents is deployed by VCF Automation in the form of Postgres with the PGvector extension.
- A re-ranking of answers provided by the vector database for any query is done by a separate component, also capable of being deployed in a NIM, called the Re-ranker. This is deployed as a micro service in an automated way through VCF Automation also.
- The completion model (LLM) takes the ranked passages from the Re-ranker as its input. Based on those ranked inputs, the LLM provides a suitable answer to the user. The completion model is hosted in its own NIM that is also auto-deployed by VCF Automation.
You can get a lot more detail on this subject at Deploying Summarize-and-Chat on VMware Private AI Foundation with NVIDIA
Use Case 4: An internal portal for collections of LLM models for application use
There will be many models in use at enterprises as AI takes off in business applications. We saw in our Use Case #3 here that models are used in “completions”, “embeddings” and “re-ranker” settings as part of just one application. When an AI application is being tested for accuracy and absence of bias, a further model, an “evaluator” is also used. Those models would all be experts trained on different datasets and would be tuned differently. Observers predict that LLMs will be as pervasive as relational databases are today for private internal use.
The data scientist community within companies is constantly assessing newly-trained models for their suitability to various uses. A library of such models appears quickly in the enterprise as Gen AI gets adopted by application developers. This demands an easy path for both evaluators of new models and for users of already-validated models – a common repository of tested/evaluated models, with access mechanisms for browsing as well as via APIs. The most commonly used API for accessing models today is the OpenAI API and that is present in the Model Portal we describe here.
Below you see one interaction with the Model Portal that shows a list of current models as seen by internal users at Broadcom. A user can now use one or more of these models to answer questions and take prompts that they want to get accurate answers to. This can be used to develop “prompt engineering” or “fine tuning” types of LLM applications. The list of models across the top center area was built from tried and tested models that were carefully chosen by Broadcom’s internal data science team. Many of these models come from the “open weights” world (such as the Huggingface reposiryt) and will be familiar to you. The difference here, however, is that these models have been tested and evaluated by an internal team for quality results when dealing with private data.
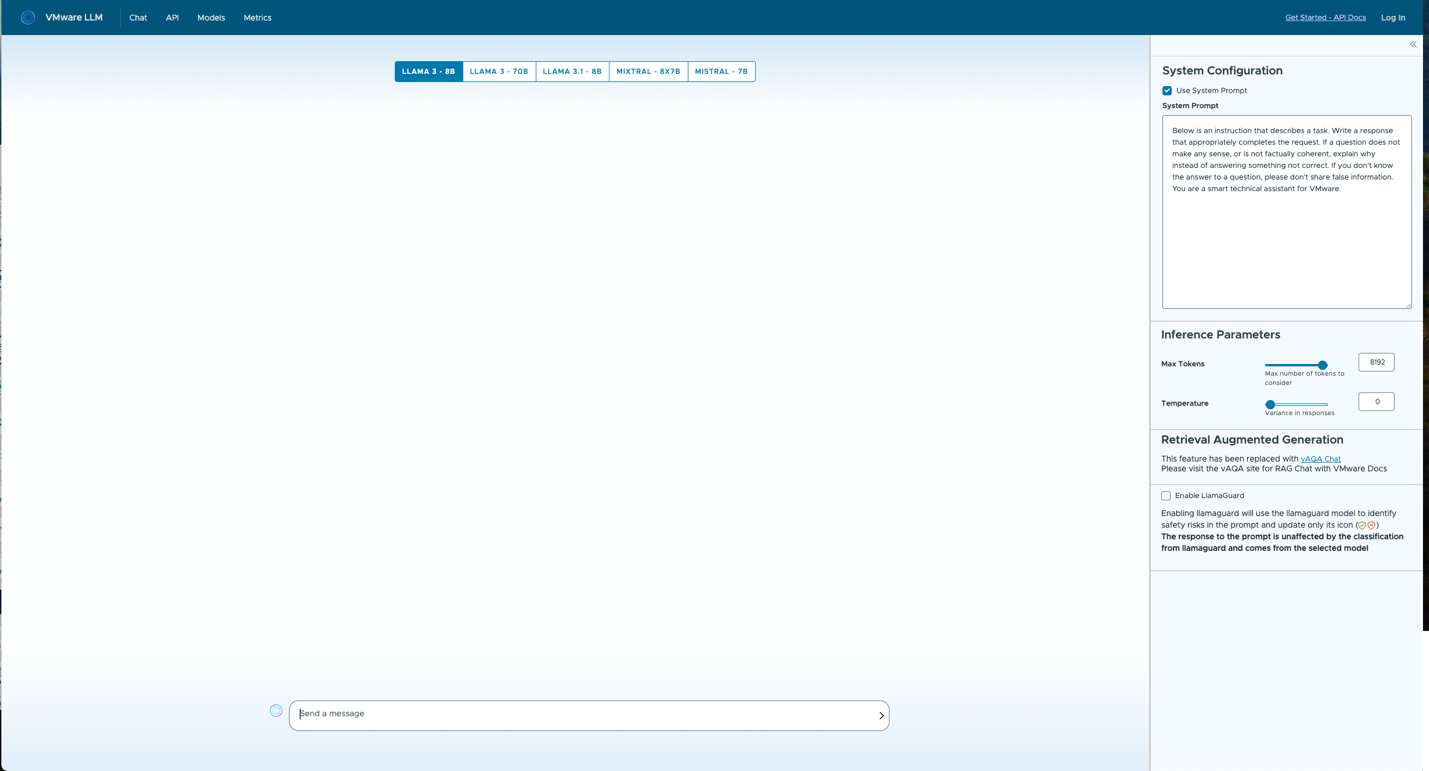
Figure 8: A portal for testing various LLMs for suitability of use in data science-driven applications
How VMware Private AI Foundation with NVIDIA Helps to Create an Internal Model Portal
To perform validation of a model, the VMware concept of a “deep learning VM” is used. This is a core part of VMware Private AI Foundation with NVIDIA. The testing of the model is done within a safe DMZ-type zone – where any unwanted effects can be discovered and mitigated. A Deep Learning VM is effectively a regular VMware virtual machine that is pre-configured correctly for virtual GPU use, along with some in-built tools like PyTorch and Conda for the data scientist. An image of such a deep learning VM can be downloaded from the Broadcom packaging site and placed into a VCF content library. From there, the VCF Automation tooling allows us to instantiate multiple “AI Workstation” instances for validating the truthfulness and resistance to bias of the model and for testing its performance and accuracy. We can make the NVIDIA components available in that deep learning VM using blueprints that are built into VCF Automation.
Once a suitable battery of tests is done in that safe zone with the deep learning VM, and the model is found to be safe and performing adequately, then that model is promoted using a VMware Private AI Service CLI command from the DLVM to a model store. That model store is supported within the VMware Private AI Foundation with NVIDIA – called the “model gallery”. Under the covers, the model gallery uses the Harbor Open Container Interface (OCI) repository technology to store, control access using RBAC, and version control the allowed models. From the model gallery, a model can be pulled and deployed by authorized users, such as those developers who want to use the model in their applications. Here is an outline of that model evaluation and model download process, using Harbor as the core model gallery.

In the portal deployment, the model can be associated with a server runtime (embodied in a NIM microservice or another model runtime, such as vLLM) that operates in VM container form. That container’s lifetime is controlled either by Docker in the deep learning VM or by its pod, in a Kubernetes cluster. The Nodes that host pods in a Kubernetes cluster are VMs in VCF. Both the runtime/NIM and the target Kubernetes cluster are all provisioned through the vSphere Kubernetes Service (VKS) that is used by VMware Private AI Foundation with NVIDIA. This Kubernetes cluster provisioning would be done by a DevOps or Platform Engineer user, who is tasked with supporting the data science team with the needed infrastructure and tooling. Each deployed model is deployed in its own container/microservice and so the multiple models mentioned earlier would each operate independently of each other. Load balancing of user traffic across replica copies of one model can also be achieved using Kubernetes mechanisms.
The model portal deployment above is in use today by many application developers inside Broadcom, using the APIs that the models expose. This “center of expertise” approach to building AI applications is a core competency, we believe, towards achieving successful AI application deployment.
For more detail on the model onboarding process using the model gallery and deep learning VMs, check out this article.
In part 1 of this series, we looked at our first two example use cases of implementing Private AI on VCF – (1) a back-office chatbot that improves customer experience in contact centers and (2) a coding assistant to help engineers be more efficient in their work. We expanded on these examples in part 2 with two more use cases that we implemented at Broadcom – a document summarizer and a model portal for AI application developers to use. This is just the base set of use cases for “Implementing Private AI” – there will be more in your enterprise, for sure.
Summary
These are examples from Broadcom’s own experiences in deploying private AI. We fully expect that there will be many more different use cases that emerge as we deploy more and more customer examples. You can gain business advantage by deploying your own use cases early and safely for use within your own enterprise to start with. Once you have established confidence in your application and models in this internal usage (i.e. private AI), you can then choose to deploy some AI applications for external customer use as a second step.
For further information, see the Private AI Ready Infrastructure for VMware Cloud Foundation Validated Solution the and the VMware Private AI Foundation with NVIDIA Guide
For financial services use-cases see the Private AI: Innovation in Financial Services Combined with Security and Compliance article
More information on use cases is available at Why Private AI is becoming the preferred choice for enterprise AI deployment
VCF makes the deployment of these use cases seamless for enterprises by quickly delivering complex tasks through automation while making sure your data remains secure on-premises. You can get started with VCF and VMware Private AI Foundation with NVIDIA today.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




