

As part of the VMware Explore 2024 announcements regarding VMware Private AI Foundation with NVIDIA (PAIF-N), we decided to refresh the Improved RAG Starter Pack v2.0 to help our customers take advantage of the newest NVIDIA Inference Microservices (NIMs), which offer production-grade attributes (robust, scalable, and secure) for the language models utilized in Retrieval Augmented Generation (RAG) systems.
Following the spirit of the original Improved RAG Starter Pack (v1.0), we deliver a series of Jupyter notebooks that implement enhanced retrieval techniques. These enrich large language models (LLMs) with relevant and factual contexts, helping them produce more accurate and reliable responses when faced with questions about specialized knowledge that might not be part of their pre-training corpus. By doing this, we can effectively reduce LLM hallucinations and enhance the reliability of your AI-driven applications.
These are the new features of the updated Improved RAG Starter Pack:
- We use NVIDIA NIMs for LLMs, text embeddings, and text reranking, the three main language models utilized to power RAG pipelines.
- We updated LlamaIndex to v0.11.1
- We use Meta-Llama3-8b-Instruct as the generator LLM powering the RAG pipeline.
- We replaced OpenAI GPT-4 with Meta-Llama-3-70b-Instruct as the engine for DeepEval to conduct two critical tasks related to the evaluation of RAG pipelines:
- To act as the synthesizer of evaluation sets for RAG systems.
- To act as the evaluator (“judge”) of RAG pipelines by scoring the pipeline’s responses to queries extracted from the evaluation set, each response is evaluated against multiple DeepEval metrics. Please keep reading to learn more about these metrics.
The Anatomy of the Improved RAG Starter Pack
The GitHub repository’s directory hosting this starter pack provides a step-by-step approach to implementing the different elements of standard RAG systems.
In addition to NVIDIA NIMs, the RAG systems leverage popular technologies such as LlamaIndex (an LLM-based application development framework), vLLM (an LLM inference service), and PostgreSQL with PGVector (a scalable and robust vector database you can deploy using VMware Data Services Manager).
We start by implementing a standard RAG pipeline. Next, use the RAG’s knowledge base to synthesize an evaluation dataset to asses the RAG system. Next, we improve the standard RAG system by adding more sophisticated retrieval techniques, which we’ll explain further in this document. Finally, the different RAG approaches are evaluated with DeepEval and compared to identify their pros and cons.
The directory structure is organized as follows.

Now, let’s discuss the content for each section.
NIM and vLLM Services Setup (00)
This section provides instructions and Linux shell scripts for deploying the NVIDIA NIM and vLLM services required to implement RAG pipelines and run evaluations on them.
PGVector Instantiation (01)
This section provides a couple of alternatives to deploy PostgreSQL with PGVector. PGVector is the vector store that LlamaIndex will use to store the knowledge base (text, embeddings, and metadata), which will augment the LLM knowledge and produce more accurate responses to users’ queries.
KB Documents Download (02)
Every RAG demo and intro utilizes a knowledge base to augment the generation capabilities of LLMs when asked about knowledge domain(s) that might not be part of their pre-training data. For this starter pack, we decided to use ten documents from NASA’s history e-books collection, which offers a variant of the typical type of documents seen in tutorials about RAG.
Document Ingestion (03)
This section contains the initial Jupyter notebook where LlamaIndex is used to parse the e-books (PDF format), split them into chunks (LlamaIndex nodes), encode each node as a long vector (embedding) and store those vectors in PostgreSQL with PGVector, which acts as our vector index and query engine. The following picture illustrates how the document ingestion process flows:
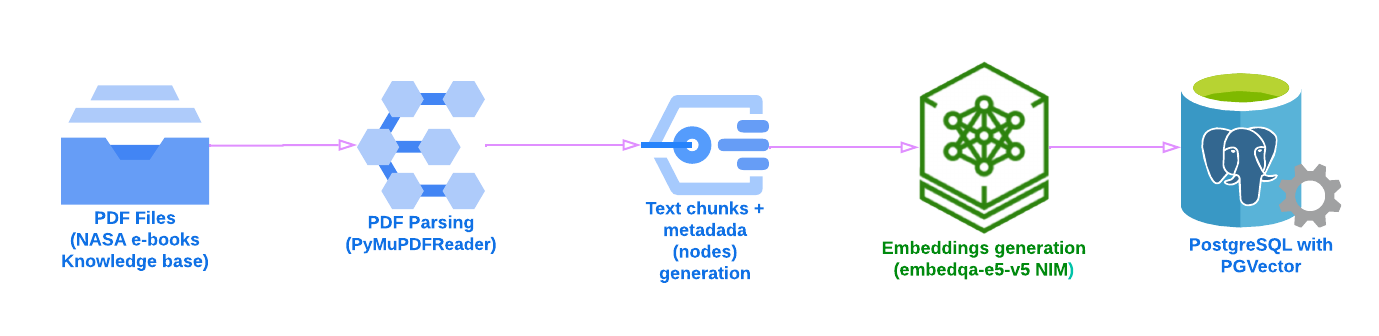
Once PGVector has ingested the nodes containing metadata, text chunks, and their corresponding embeddings, it can provide a knowledge base for an LLM to generate responses about a knowledge base (NASA history books, in our case).
Evaluation Dataset Generation (04)
The Jupyter Notebook in this folder exemplifies the use of DeepEval’s Synthesizer to generate a question/answer dataset that later will be used by DeepEval’s metrics to evaluate the quality of RAG pipelines and determine how changes in critical components of the RAG pipeline, such as LLMs, embedding models, re-ranking models, vector stores, and retrieval algorithms, affect the quality of the generation process. We use the Meta-Llama-3-70b-Instruct model to generate the evaluation set synthetically.
RAG Variants Implementation (05)
In this directory, we include three subdirectories, each with one Jupyter Notebook that explores one of the following RAG pipeline implementation variants powered by LlamaIndex and language models served by NVIDIA NIMs :
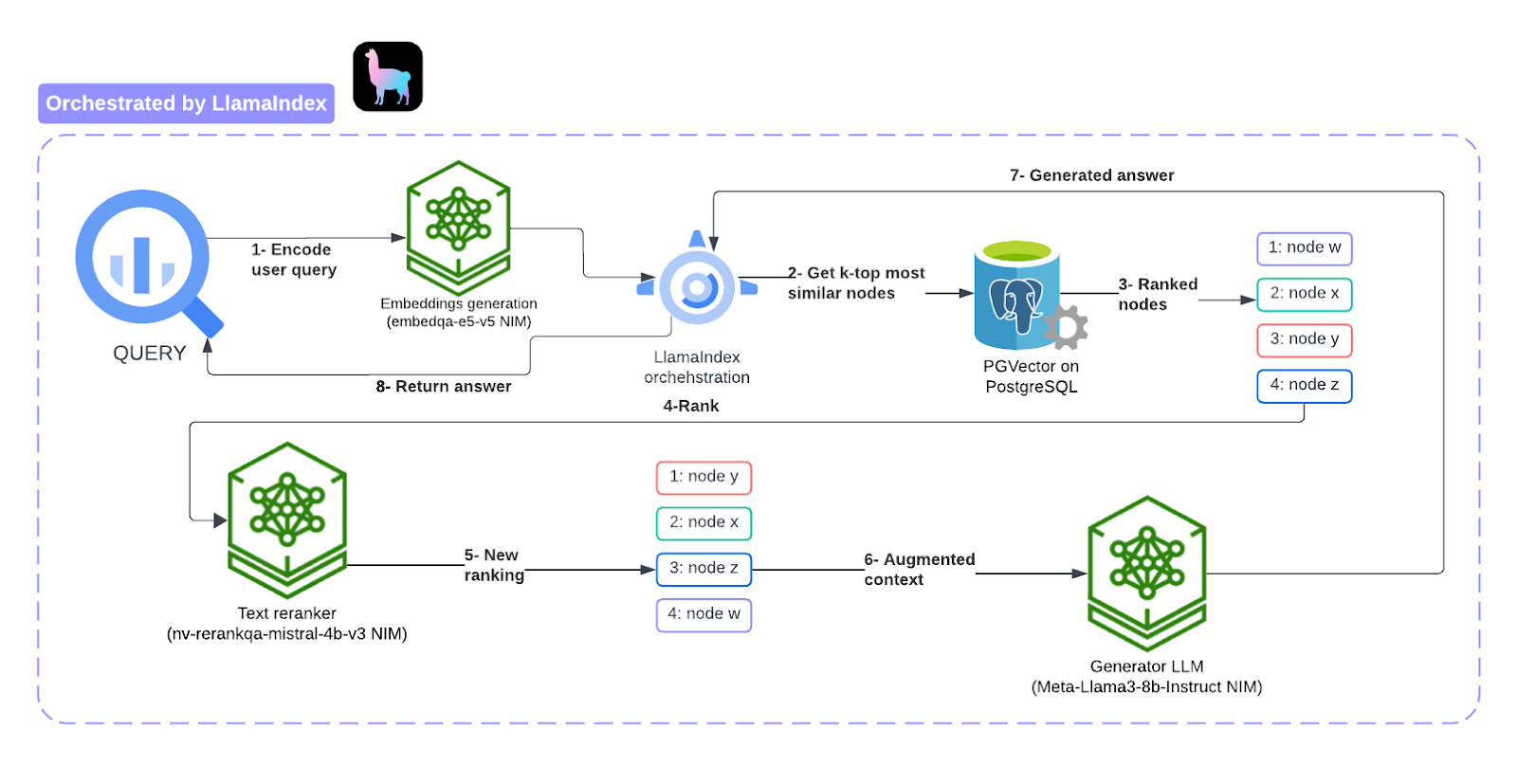
- Standard RAG Pipeline + re-ranker: This notebook implements a standard RAG pipeline using LlamaIndex, incorporating a final re-ranking step powered by a re-ranking language model. Unlike the embedding model, a re-ranker uses questions and documents as input and directly outputs similarity instead of embedding. You can get a relevance score by inputting the query and passage to the re-ranker. We use the following NVIDIA NIMs to power the RAG system:
- RAG generator LLM: Meta-Llama-3-8b-Instruct
- RAG embedding model: nvidia/nv-embedqa-e5-v5
- RAG re-ranker: nvidia/nv-rerankqa-mistral-4b-v3
The following picture illustrates how this RAG system works.
- Sentence Windows retrieval: The Sentence Window Retrieval (SWR) method improves the accuracy and relevance of information extraction in RAG pipelines by focusing on a specific window of sentences surrounding a target sentence. This focused approach increases precision by filtering out irrelevant information and enhances efficiency by reducing the volume of text processed during retrieval. Developers can adjust the size of this window to better tailor their searches according to the needs of their specific use cases.
However, the method has potential drawbacks; concentrating on a narrow window risks missing critical information in adjacent text, making the selection of an appropriate context window size crucial to optimize both the precision and completeness of the retrieval process. The Jupyter Notebook in this directory uses LlamaIndex’s implementation of SWR via the Sentence Window Node Parsing module that splits a document into nodes, each being a sentence. Each node contains a window from the surrounding sentences in the nodes’ metadata. This list of nodes gets re-ranked before being passed to the LLM to generate the query response based on the data from the nodes.
- Auto Merging Retrieval: Auto-merging retrieval is a RAG method designed to address the issue of context fragmentation in language models, mainly when traditional retrieval processes produce disjointed text snippets. This method introduces a hierarchical structure where smaller text chunks are linked to larger parent chunks. During retrieval, if a certain threshold of smaller chunks from the same parent chunk is met, these are automatically merged. This hierarchical and merging approach ensures that the system gathers larger, coherent parent chunks instead of retrieving fragmented snippets. The notebook in this directory uses LlamaIndex’s AutoMergingRetriever to implement this RAG variant.
RAG Pipeline Evaluation (06)
This folder contains the Jupyter Notebook that uses DeepEval to evaluate the previously implemented RAG pipelines. For this purpose, DeepEval uses the evaluation dataset generated in the previous step. Here is a brief description of the DeepEval metrics used to compare the different RAG pipeline implementations. Notice that Deepeval metric algorithms can explain why (reason) the LLM gave each score to the metric. In our case, we enabled that feature so you can see it working.
- Contextual Precision measures your RAG pipeline’s retriever by evaluating whether nodes in your retrieval context relevant to the given input are ranked higher than irrelevant ones.
- Faithfulness measures the quality of your RAG pipeline’s generator by evaluating whether the actual output factually aligns with the contents of your retrieval context.
- Contextual Recall measures the quality of your RAG pipeline’s retriever by evaluating the extent to which the retrieval context aligns with the expected output.
- Answer Relevancy measures how relevant the actual output of your RAG pipeline looks compared to the provided input.
- Hallucination. This metric determines whether your LLM generates factually correct information by comparing the actual output to the provided context. This is a fundamental metric, as one of the main goals of RAG pipelines is to help LLMs generate accurate, up-to-date, and factual responses to user queries.
The DeepEval evaluations were executed using the following setup:
- Judge LLM scoring DeepEval’s metrics: Meta-Llama-3-70b-Instruct running on vLLM in guided-JSON mode.
The following table shows the evaluation results from one of our experiments, which involved over 40 question/answer pairs.
| RAG Implementation | Contextual Precision Score | Contextual Recall Score | Answer Relevancy Score | Faithfulness Score | HallucinationScore (less is better) |
| Standard RAG + Re-ranker | 0.80 | 0.83 | 0.84 | 0.94 | 0.43 |
| Sentence Window Retrieval | 0.89 | 0.79 | 0.80 | 0.96 | 0.31 |
| Auto MergingRetrieval | 0.83 | 0.84 | 0.82 | 0.96 | 0.40 |
The following chart provides another view of the previous results.

As the table demonstrates, a particular RAG implementation may perform better on specific metrics, indicating their applicability to different use cases. Additionally, the evaluation metrics help identify what components of your RAG pipelines need adjustments to elevate the performance of the whole pipeline.
Conclusion
The improved RAG Starter Pack provides a valuable toolkit for those implementing RAG systems, featuring a series of well-documented Python notebooks designed to enhance LLMs by deepening contextual understanding. This pack includes advanced retrieval techniques and tools like DeepEval for system evaluation, which help reduce issues such as LLM hallucinations and improve the reliability of AI responses. The GitHub repository is well-structured, offering users clear step-by-step guidance that is easy to follow, even for non-data scientists. We hope our PAIF-N customers and partners find it helpful to get started with running GenAI applications on top of VMware VMware Cloud Foundation infrastructures. Stay tuned for upcoming articles to discuss critical aspects of production RAG pipelines related to safety and security.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





