

In this article, we review a set of new features that extend the vGPU support in vSphere 8 Update 3 and VCF. These cover several areas, from using vGPU profiles of different types and sizes together to making adjustments to the DRS advanced parameters that determine how a vGPU-aware VM will be judged for a vMotion, for example. All of these enhancements are geared to making life easier for systems administrators, data scientists and other kinds of users to get their workloads on the vSphere and VCF platforms. Let’s get into these topics in more detail right away.
Heterogeneous vGPU Profile Types with Different Sizes
With VMware vSphere, we can assign a vGPU profile from a set of pre-determined profiles to a VM to give it functionality of a particular kind. The set of available vGPU profiles is presented once the host-level NVIDIA vGPU manager/driver is installed into ESXi, using a vSphere Installation Bundle (VIB).
These vGPU profiles are referred to as C-type profiles in the case where the profile is built for compute-intensive work, such as machine learning model training and inference. There are several other types of vGPU profiles, Q (Quadro) for graphical workloads being among the most popularly found. The letters “c” and “q” come at the end of the vGPU profile name, hence the naming of that type.
In the earlier vSphere 8 Update 2 , we were able to assign vGPU profiles to VMs that provided different kinds of functionality support, while using the same GPU device. The restriction in that vSphere version was that they had to be vGPU profiles of the same size, such as those ending in 8q and 8c. The “8” here represents the number of Gigabytes of memory on the GPU itself – sometimes called the framebuffer memory – that is assigned to a VM using that vGPU profile. This can take different values depending on the model of GPU underlying it.
When using an A40 or an L40s GPU, we can have a C-type vGPU profile, that is designed for compute-intensive work like machine learning and a Q-type vGPU profile (designed for graphical work) assigned to separate VMs that were sharing the same physical GPU on a host.
Now with vSphere 8 Update 3, we can continue to mix those different vGPU profile types on one physical GPU, but also have different memory sized vGPU profiles sharing the same GPU as well.
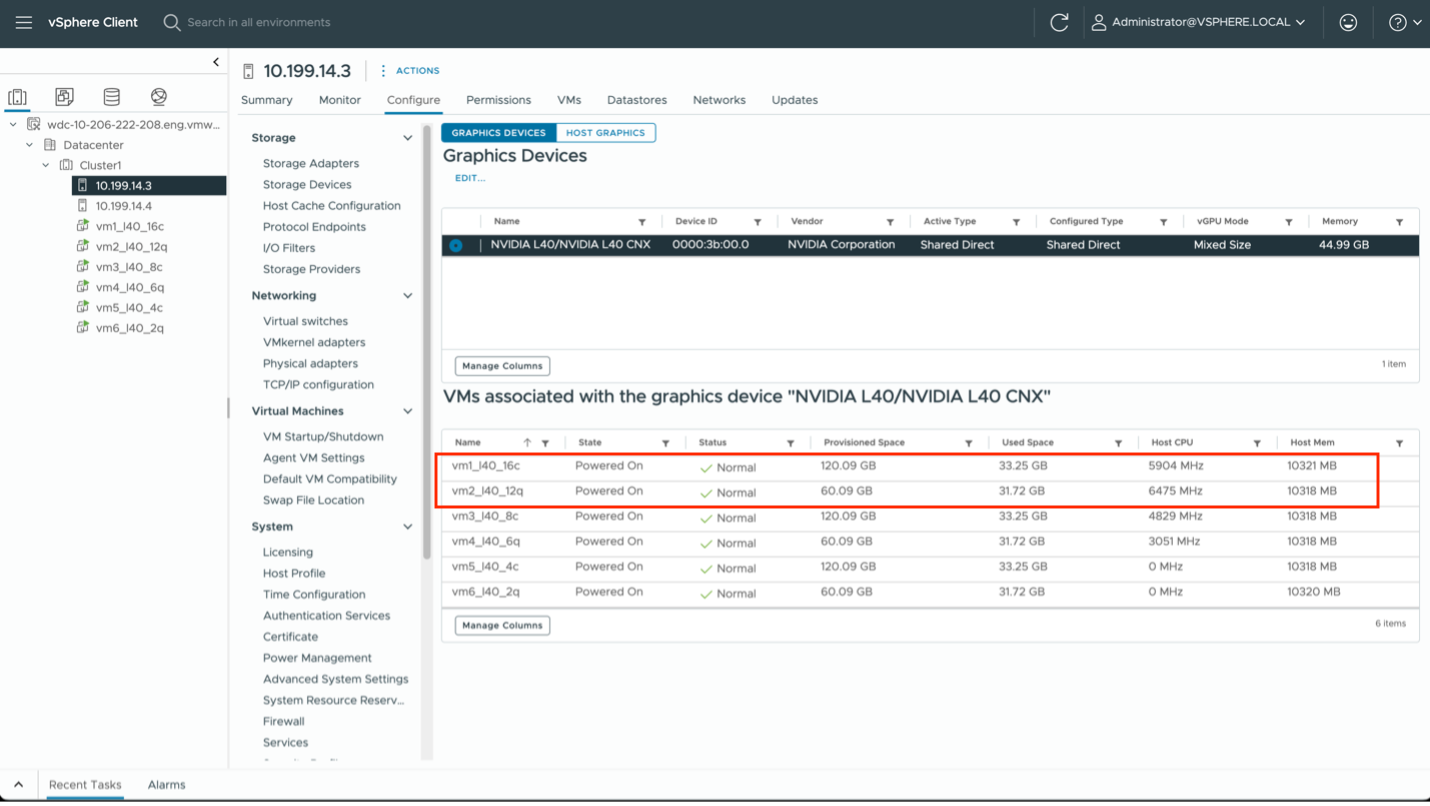
As an example of the new vSphere 8 Update 3 functionality: VM1 above with vGPU profile l40-16c (for a compute workload) and VM2 with vGPU profile l40-12q (for a quadro/graphics workload) are sharing the same L40 GPU device within a host. In fact, all of the VMs above are sharing the same L40 GPU.
This allows better consolidation of workloads on to fewer GPUs when the workloads do not consume the entire GPU by themselves. The ability to host heterogeneous types and sizes of vGPU profiles on one GPU device applies to the L40, L40s and A40 GPUs in particular, as those are dual-purpose GPUs. That is, they can handle both graphics and compute-intensive work, whereas the H100 GPU is dedicated to compute-intensive work.
Enabling DRS Cluster Settings for DRS and vGPU VM Mobility
In the vSphere Client for 8.0 U3, there are new cluster settings that give a friendlier method of adjusting the advanced parameters for a DRS cluster. You can set a VM stun time limit that is to be tolerated for vGPU profile-aware VMs that may take longer than the default time to execute a vMotion. The default stun time for vMotion is 100 seconds, but that may not be enough time for certain VMs that have larger vGPU profiles. The extended time is taken to copy the GPU memory to the destination host. You can get an estimated stun time for your particular vGPU-capable VM also in the vSphere Client. For additional stun time capabilities, please reference this article
With vSphere 8 Update 3, we have a friendlier user interface for setting the advanced parameters to a DRS cluster that relate to vMotion of VMs.
Before we look at the second highlighted item on the Edit Cluster Settings screen below, it is important to understand that vGPU as a mechanism for accessing a GPU is one of a set of techniques that are on the “Passthrough spectrum”. That is, vGPU is really another form of passthrough. You may have perceived that Passthrough and vGPU approaches are widely different from each other up till now, as they are indeed separated from each other in the vSphere Client as you choose to add a new PCIe device to a VM. However, they are closely related to each other. In fact, vGPU was once referred to as “mediated passthrough”. That spectrum of uses of Passthrough in different ways is shown here.
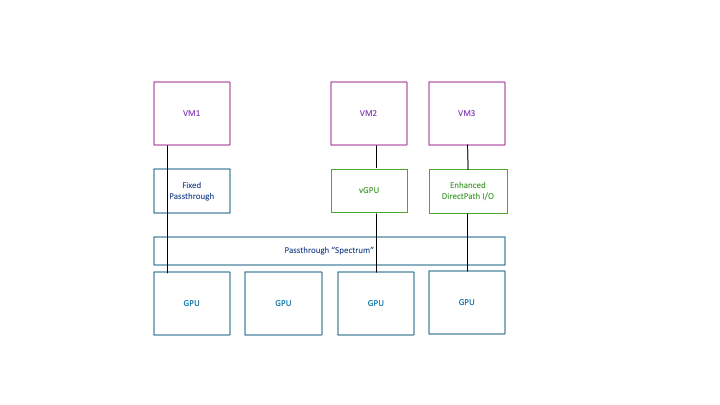
This is the reason that the vSphere Client in the highlighted section of screen below is using the terms “Passthrough VM” and “Passthrough Devices”. Those terms in fact refer to vGPU-aware VMs here – and so the discussion is about enabling DRS and vMotion for vGPU-aware VMs in this screen. vMotion is not allowed with VMs that use fixed passthrough access, as seen on the left side in the diagram above.
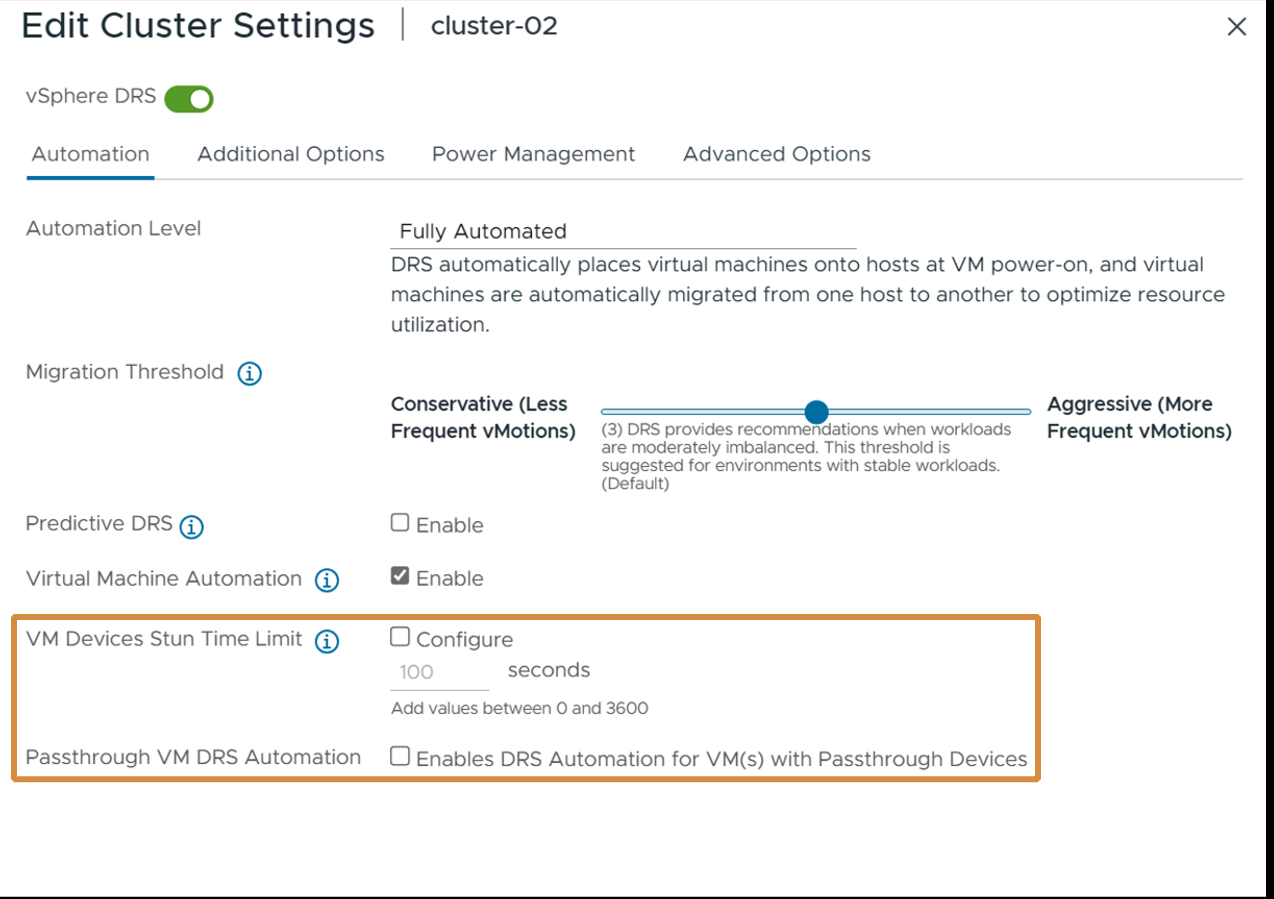
A new UI feature allows the user to enable the vSphere advanced setting named “PassthroughDrsAutomation”. With this advanced setting enabled, then provided the stun time rules are obeyed, the VMs in this cluster may be subject to a vMotion to another host, due to a DRS decision. For additional information on these advanced DRS settings, please reference this article
GPU Media Engine Access
The single media engine on a GPU can be used by a VM that hosts an application that needs to do transcoding (encoding/decoding) logic on the GPU rather than on the slower CPU, such as for video-based applications.
In vSphere 8 Update 3 we support a new vGPU profile for VMs that require access to the media engine within the GPU. Only one VM can own this singular media engine. Examples of these vGPU profiles are
a100-1-5cme (single slice) – “me” for media engine
h100-1-10cme (two slices)
This kind of vGPU profile would be used by VMs that host applications that need to do transcoding logic on the GPU itself rather than on the slower CPU for video-based applications.
Higher Speed of vMotion of VMs with Larger vGPU Profiles
New enhancements under the covers of vMotion allow us to scale up throughput on the 100Gb vMotion network of up 60 Gbit/sec for a vMotion of a VM that has a contemporary architecture GPU (H100, L40S) associated with it – yielding a shortened vMotion time. This does not apply to A100 and A30 GPUs that belong to an older architecture (GA100).
New Technical Papers and Design Guidance for GPUs with VMware Private AI Foundation with NVIDIA
Two important publications were issued by VMware authors recently. Agustin Malanco Leyva and team published the VMware Validation Solution for Private AI Ready Infrastructure here
This document takes you through detailed guidance on GPU/vGPU setup on VMware Cloud Foundation and many other factors to get your infrastructure organized for VMware Private AI deployment.
One of the key application designs that we believe enterprises will deploy first on the VMware Private AI Foundation with NVIDIA is retrieval augmented generation or RAG. Frank Denneman and Chris McCain explore the security and privacy requirements and implementation details of this in detail in a new technical white paper entitled VMware Private AI – Privacy and Security Best Practices
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





