
NVIDIA Run:ai accelerates AI operations through dynamic resource orchestration, maximizing GPU utilization, comprehensive AI-lifecycle support, and strategic resource management. By pooling resources across environments and utilizing advanced orchestration, NVIDIA Run:ai significantly enhances GPU efficiency and workload capacity.
We recently announced that enterprises can now deploy NVIDIA Run:ai with the built-in VMware vSphere Kubernetes Services (VKS), a standard capability in VMware Cloud Foundation (VCF). This will help enterprises achieve optimum GPU utilization with NVIDIA Run:ai, streamlining Kubernetes deployment, and supporting both container and VM deployments on VCF. This allows for the deployment of AI and traditional workloads on a single platform
This blog explores how Broadcom customers can now deploy NVIDIA Run:ai on VCF leveraging VMware Private AI Foundation with NVIDIA to deploy AI Kubernetes clusters to maximize GPU utilization, streamline operations, and unlock GenAI on their private data.
NVIDIA Run:ai on VCF
While many organizations default to running Kubernetes on bare-metal servers, this “do-it-yourself” approach often results in siloed islands of infrastructure. It forces IT teams to manually build and manage the very services that VCF provides by design, lacking the deep integration, automated lifecycle management, and resilient abstractions for compute, storage, and networking that are critical for production AI. This is where the VMware Cloud Foundation platform provides a decisive advantage.
vSphere Kubernetes Service is the Best Way to Deploy Run:ai on VCF
The most effective and integrated way to deploy NVIDIA Run:ai on VCF is by using VKS, which provides enterprise-ready, Cloud Native Computing Foundation (CNCF) certified Kubernetes clusters that are fully managed and automated. NVIDIA Run:ai is then deployed onto these VKS clusters, creating a unified, secure, and resilient platform from the hardware up to the AI application.
The value is not just in running Kubernetes, but in running it on a platform that solves foundational enterprise challenges:
- Lower TCO through VCF: Reduce infrastructure silos, leverage existing tools and skill set without retraining and changing processes, and provide unified lifecycle management across infrastructure components.
- Consistent Operations: Built on familiar tools, skills, and workflows with automated clusters & GPU operator provisioning, upgrades, and lifecycle management at scale.
- Run and Manage Kubernetes at Scale: Deploy and manage Kubernetes clusters at scale with a built-in, CNCF certified Kubernetes runtime and fully automated lifecycle management.
- 24-months Support: With support for each of the vSphere Kubernetes releases (VKr) minor version reduces upgrade pressure, stabilizes environments, and frees up teams to focus on delivering value instead of constantly planning upgrades.
- Better Privacy, Security & Compliance by Design: Confidently run sensitive and regulated AI/ML workloads with built-in privacy, governance, compliance, and the ability to deploy isolated Kubernetes environments with flexible security postures at the cluster level.
- Container Networking with VCF – Bare-metal Kubernetes networks are often flat, complex to configure, and manually intensive. In a large, centralized Kubernetes cluster, providing reliable connectivity across applications with varying requirements is challenging. VCF Networking addresses this by delivering container networking with Antrea, an enterprise-grade Container Network Interface (CNI) based on the CNCF sandbox project Antrea. It is deployed as the default CNI when VKS is enabled, offering in-cluster networking, Kubernetes network policy enforcement, centralized policy management, and traceflow operations from the NSX management plane. While Antrea is the default CNI of choice, users can also select Calico as an alternative.
- Advanced Security with vDefend – Different applications in a shared cluster often demand distinct security postures and access controls, which are difficult to enforce consistently at scale. The VMware vDefend add-on for VCF extends advanced security capabilities by enabling Antrea cluster network policies and east-west micro-segmentation down to the container level. This allows IT to programmatically isolate AI workloads, data pipelines, and tenant namespaces with software-defined, zero-trust policies. These capabilities are essential for compliance and for preventing lateral movement in the event of a breach, a level of granularity that is extremely complex to replicate on physical switches.
- Superior Resilience & Automation with VMware vSphere This is more than just convenience; it’s about infrastructure robustness. A bare-metal server failure running a critical, multi-day training job can mean a considerable loss of time. VCF, powered by vSphere HA, automatically restarts those workloads on another host.
- In addition to HA, vMotion allows for non-disruptive hardware maintenance without stopping the AI workload, and Dynamic Resource Scheduler (DRS) dynamically balances resources to prevent hotspots. This automated resilience is simply absent in a static, bare-metal environment.
- Flexible, Policy-Driven Storage with vSAN AI workloads have diverse storage needs, from high-IOPS scratch space for training to resilient object storage for datasets. vSAN allows you to define these requirements (e.g., performance, fault tolerance) on a per-workload basis using storage policies. This avoids creating more infrastructure silos and managing multiple, disparate storage arrays, which is a common outcome in bare-metal deployments.
- NVIDIA Run:ai Advantage:
- Maximize GPU Utilization On top of this solid foundation, NVIDIA Run:ai enables dynamic GPU allocation, fractional GPU sharing, and workload prioritization across teams, ensuring that the powerful, resilient infrastructure is also being used in the most efficient way possible.
- Scalable AI Services: It supports the deployment of large language models (inference) and other complex AI services (distributed training, fine-tuning) with the ability to scale efficiently across resources as user demand fluctuates.
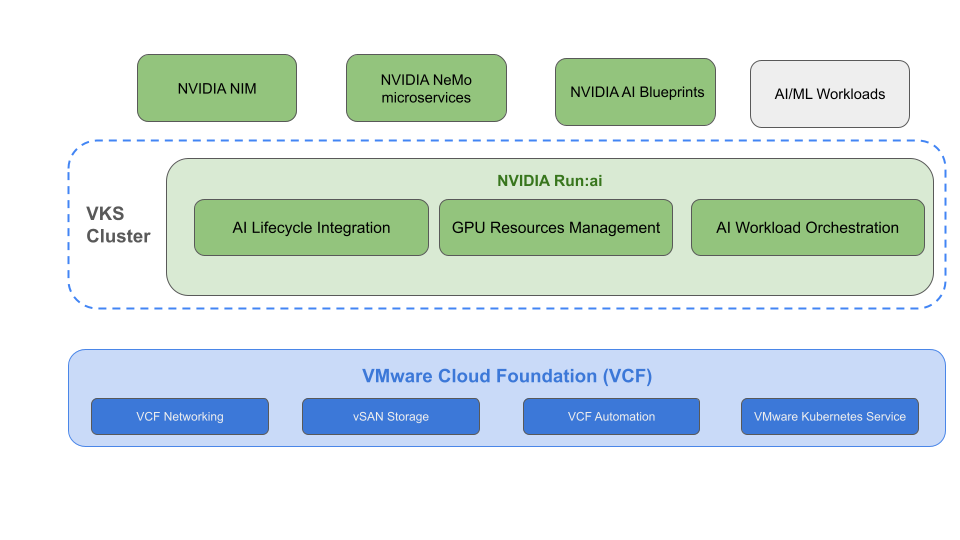
Architecture Overview
Here’s a high-level view of the solution architecture:
- VCF: Provides the base infrastructure with vSphere, VCF Networking (includes VMware NSX and VMware Antrea), VMware vSAN, and VCF Operations fleet management.
- AI-Enabled Kubernetes Cluster: The VCF-managed Kubernetes(VKS) that provides the runtime for AI workloads, complete with GPU access.
- NVIDIA Run:ai Control Plane: Available as-a-Service or can be deployed within the Kubernetes cluster to manage AI workloads, schedule jobs, and provide visibility.
- NVIDIA Run:ai Cluster: Deployed within the Kubernetes cluster to handle GPU orchestration and workload execution
- Data Science Workloads: The containerized applications and models that consume the GPU resources.
This architecture provides a fully integrated, software-defined stack. Instead of IT teams spending months integrating disparate servers, switches, and storage arrays, VCF presents them as a single, elastic, and automated cloud-operating model, ready to consume.
Architecture Diagram
There are two installation options for deployment of the NVIDIA Run:ai control plane.
SaaS: In this setup, NVIDIA Run:ai control plane is hosted in the cloud (see https://run-ai-docs.nvidia.com/saas). The NVIDIA Run:ai cluster, running on-premises, establishes an outbound connection to the hosted control plane to run AI workloads. This configuration necessitates an outbound network connection from the cluster to the Run:ai SaaS control plane.
Self-hosted: NVIDIA Run:ai’s control plane is installed on premises (see https://run-ai-docs.nvidia.com/self-hosted) on a VKS cluster that can be shared with compute workloads or dedicated for only the NVIDIA Run:ai control plane role. This option also offers a disconnected installation.
Here’s a visual representation of the infrastructure stack:
Deployment Scenarios
Scenario 1: Installing NVIDIA Run:ai on a vSphere Kubernetes Service enabled VCF instance
Prerequisites:
- VCF environment with GPU-enabled ESXi hosts
- VKS AI cluster deployed by VCF Automation
- GPUs configured as DirectPath I/O, vGPU time-sliced or NVIDIA multi-instance GPU (MIG) enabled
- If vGPU is used, NVIDIA GPU Operator is automatically installed as part of the VCFA blueprint deployment.
NVIDIA Run:ai Control plane High-level Steps:
- Prepare your VKS cluster designated as the NVIDIA Run:ai control plane role with the required pre-requisites.
- Create a secret with the token received from NVIDIA Run:ai to access the NVIDIA Run:ai container registry.
- If VMware Data Services Manager is in place, set up your Postgres Database for NVIDIA Run:ai’s control plane, if not, NVIDIA Run:ai will use an embedded Postgres Database.
- Add the helm repository and install the control plane via helm
Cluster high-level steps:
- Prepare your VKS cluster designated as the Cluster role with the required pre-requisites and run the NVIDIA Run:ai cluster preinstall diagnostics tool.
- Install the required extra components such as NVIDIA’s network operator, Knative and other frameworks based on your use cases.
- Log into the NVIDIA Run:ai web console and navigate to Resources and click “+New Cluster”
- Follow the installation instructions and run the commands provided on your Kubernetes cluster
Benefits:
- Full control over infrastructure
- Seamless integration with the VCF ecosystem
- Robustness through automated vSphere HA, which offers a level of protection for long-running AI training jobs and high-availability inference servers from underlying physical hardware failures—a critical risk in bare-metal environments.
Scenario 2: Integrating vSphere Kubernetes Service with existing NVIDIA Run:ai Deployments
Why vSphere Kubernetes Service?
- VMware-managed Kubernetes simplifies cluster operations
- Tight integration with the VCF Stack, including VCF Networking and VCF Storage
- Dedicate a single VKS cluster to one application or purpose (development, testing, production)
Steps:
- Connect VKS cluster(s) to existing NVIDIA Run:ai control plane by installing the NVIDIA Run:ai cluster and the required components.
- Configure GPU quotas and workload policies from the NVIDIA Run:ai user interface.
- Leverage NVIDIA Run:ai’s features such as auto-scaling, gpu partitioning with full integration with the VCF stack.
Benefits:
- Operational simplicity
- Enhanced visibility and control
- Easier lifecycle management
Operational Insights: The “Day 2” VCF Advantage
Observability. On bare metal, observability is often a federated set of tools (Prometheus, Grafana, node exporters, etc.) that still leaves blind spots in the physical hardware and network. VCF, integrating with VCF Operations (part of VCF Fleet Management), provides a single pane of glass to monitor and correlate performance from the physical layer, through the vSphere hypervisor, and up into the Kubernetes cluster. This now includes dedicated VCF Operations GPU dashboards, providing crucial data to guide your understanding of how GPUs and vGPUs are consumed by existing applications. This deep, AI-specific insight makes it dramatically faster to pinpoint and resolve bottlenecks.
Backup & Disaster Recovery. Velero, when integrated with vSphere Kubernetes Service via the vSphere Supervisor, serves as a robust backup and disaster recovery tool for VKS clusters and vSphere Pods. It leverages the Velero Plugin for vSphere to enable volume snapshots and metadata backups directly from the Supervisor’s vSphere storage infrastructure.
This is a robust backup strategy that can be integrated with disaster recovery plans for your entire AI platform (including the stateful Run:ai control plane and data), not just the stateless worker nodes.
Summary: Bare-Metal vs. VCF for Enterprise AI
| Aspect | Bare-Metal Kubernetes (DIY Approach) | VMware Cloud Foundation (VCF) Platform |
| Networking | Flat, higher complexity, manually configured networks. | Software-defined networking with VCF Networking. |
| Security | Difficult to secure; manual policy enforcement. | Granular micro-segmentation down to the container when vDefend is used; programmatic, zero-trust policies. |
| Compute Resilience | High risk; server failure can cause considerable downtimes for critical workloads such as model inference and training. | Automated resilience with vSphere HA (workload restart), vMotion (non-disruptive maintenance), and DRS (load balancing). |
| Storage | Leads to “siloed islands” and multiple disparate storage arrays. | Unified, policy-driven storage with VCF Storage; avoids silos and simplifies management. |
| Backup & DR | Often an afterthought; exceptionally complex and manually intensive to achieve. | Native CSI snapshots + Supervisor-wide automated backup with Velero |
| Observability | A set of disparate tools with blind spots in hardware/network. | A single pane of glass (VCF Operations) for correlated, end-to-end monitoring from hardware to application. |
| Lifecycle Management | Manual, high-effort lifecycle management for all components. | Automated, full-stack lifecycle management via VCF Operations.. |
| Overall Model | Forces IT to manually build and integrate a diverse collection of industry tools. | A single, elastic, and automated cloud-operating model with enterprise services “built-in.” |
NVIDIA Run:ai on VCF accelerates Enterprise AI
Deploying NVIDIA Run:ai on VCF empowers enterprises to build scalable, secure, and efficient AI platforms. Whether starting fresh or enhancing existing deployments with VKS, customers gain flexibility, performance, and the enterprise-grade features they depend on.
VCF allows your enterprise to focus on accelerating AI development and ROI, not on the low-level, high-risk business of building and managing infrastructure. It provides the automated, resilient, and secure foundation that production AI workloads demand, letting NVIDIA Run:ai do what it does best – maximize GPU utilization.
Ready to get started? Explore the NVIDIA Run:ai documentation and VMware Private AI resources to begin your journey.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




