
Cyber and Disaster Recovery Are Not the Same
A recent post pointed out that many organizations today operate under the misconception that a traditional disaster recovery solution and a cyber recovery solution are one and the same. In practice, they are not.
While these two distinct use case scenarios may seem to have similar outcomes—restoring operational capabilities after a disaster—IT teams end up having to manually integrate additional layers to enable cyber recovery and overcome the unique challenges it presents. This piecemeal approach to cyber and disaster recovery ultimately hinders their ability to operate smoothly and confidently protect their most valuable asset—data.
VMware Live Recovery (VLR) removes the need for organizations to deploy, integrate and manage separate components across infrastructure, replication, backup storage, validation tools, automation and orchestration. This enables customers to simplify the way they operate, gain full visibility and control into their VCF environment recovery health, and recover from file-based and fileless strains of malware as well as any traditional DR scenario.
To better understand some of the differences between cyber and disaster recovery, check out this article. Let’s review the basics of building a solid foundation for traditional disaster recovery for your VMware Cloud Foundation (VCF) private cloud virtualized workloads. VMware Live Recovery (VLR) is an Advanced Service of VCF, engineered to enable cyber and disaster recovery in a single solution.
VLR Disaster Recovery Architecture
Disaster recovery solutions almost always involve at least two locations—the primary site and the recovery site. In this blog, we will review the basics of moving from existing VMware configurations to a VCF based disaster recovery solution so that you can enable a solid recovery capability for your business applications. Throughout this blog, we will provide pointers to some of the other online resources available to better understand getting your organization to this new setup.
For most virtualized environments, there are a collection of VMs running production business applications at a given site. Let’s call this “SITE 1” for the sake of this discussion. Those VMs are running on vSphere (ESX) hosts under the management of a vCenter. With larger collections of VMs, they might also be organized into separate hardware resource clusters and managed in different vCenter management inventories. The primary production site might look initially like this:
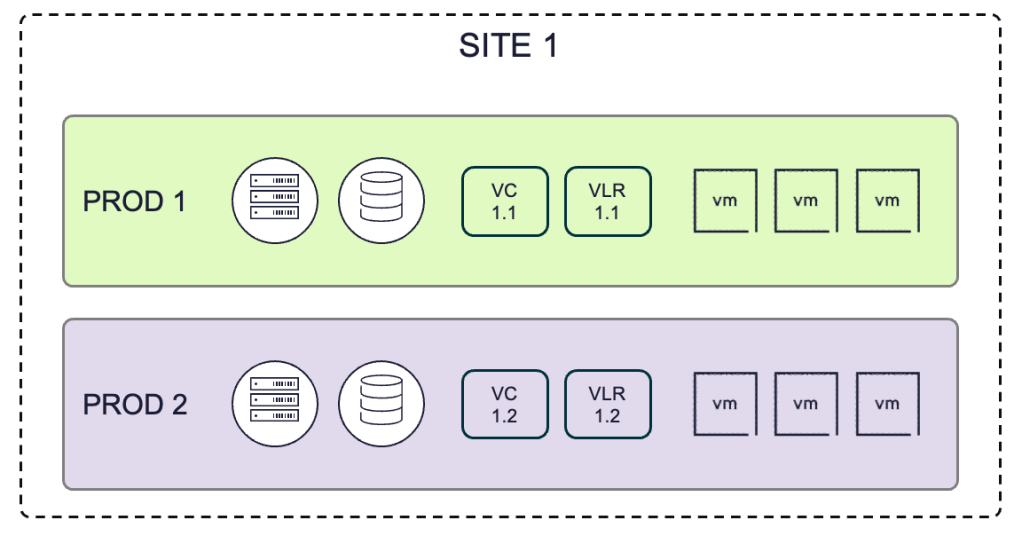
The key things to note from the diagram above are:
- The vCenter is colocated with the compute and storage physical components for the clusters it manages
- The VLR Appliance is colocated with the vCenter appliance
- The VMs that make up a logical production environment are in a single vCenter inventory
- The notion of a “site” is a loosely defined location and represented with a dashed boundary line
For a traditional disaster recovery scenario, these production site workloads are replicated to a secondary site (as shown by the arrows in the diagram below) to resume production operations as protection against primary site disaster risks. Let’s call this recovery site “SITE 2”. The resulting multisite disaster recovery architecture might look something like this:
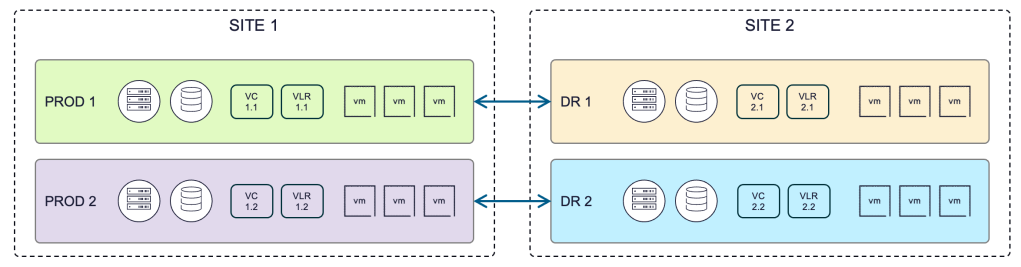
The key things to note from the diagram above are:
- The production and recovery sites are symmetrical in nature but do not need to be exactly the same from a physical resource perspective as long as the workloads that need to run at each site have sufficient resources to operate
- The vCenter, VLR Appliance, and applications VMs, are organized logically the same at each site
- The notion of a “site” is a loosely defined location and represented with a dashed boundary line
With VCF configurations, the basic traditional disaster recovery setup will be very similar to what many organizations have been doing for years. However, there are some additional formalisms built into the new VCF private cloud architectures that we will introduce in this article, but an in-depth review of deployment options and best practices is outside the scope of this overview. For more details on VCF design considerations, please refer to the following online documentation:
- Design Blueprints for VMware Cloud Foundation
- Terminology – VCF Taxonomy
- Validated Solution – Site Protection and Disaster Recovery for VMware Cloud Foundation
One of the key considerations when moving from your current VMware environments to VCF configurations will be the organization of the workload domains and placement of the key management components of the solution.
With VCF, the concept of a “site” becomes one of the formalisms of the private cloud configuration along with a separate Management Domain to hold the key components that manage the VCF site. The links provided above provide more insight into the details of what constitutes a VCF instance.
For this article, we will take a very simple design approach and locate the relevant vCenter and VMware Live Recovery appliances into the Management Domain.
With this adjustment in the location of resources and services, the resulting disaster recovery solution might look something like this:
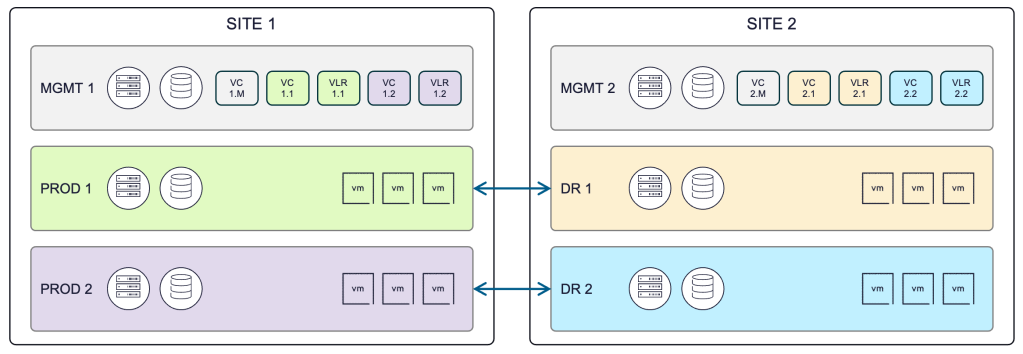
The key things to note from the diagram above are:
- The production and recovery sites are symmetrical in nature but do not need to be exactly the same from a physical resource perspective as long as the workloads have sufficient resources to operate.
- Each site now has a Management Domain (MGMT) to provide control and resources for the overall VCF site management functionality.
- The vCenter and VLR Appliance are now provisioned into the Management Domain.
- The notion of an instance of VCF, or “site”, is now more formally defined within the VCF architecture and represented with a solid boundary line.
In either case, either before or after deploying the desired VCF design, the basic disaster recovery solution is still mainly between the vCenter inventories of VMs at the source production site and the target recovery site.
Recent Innovations in Disaster Recovery for VCF
There are a couple of key enhancements in the deployment and setup of the traditional disaster recovery solution for VCF.
First is the convergence of multiple recovery related services from separately managed appliances into a single converged appliance. This was discussed briefly in this blog and in more detail in the product documentation. In our example here, the combined VLR appliance has been deployed into the Management Domain along with the corresponding vCenter for the appropriate Workload Domain. Each Workload Domain and vCenter will have its own VLR Appliance.
Another change in the VCF setup worth noting is around the site-to-site network connectivity when using the built-in vSphere Replication method for moving VM replicas from one site to the other. With the latest vSphere Replication, the transport for the snapshot data is now performed between the ESX hosts in the cluster(s) that connect to the datastore(s) that hold the VMs being protected for disaster recovery. This was discussed in this article on upgrading to Enhanced vSphere Replication. This new configuration provides for better performance and scalability of the replication operations.
For some sites, it may be desirable to separate the replication network traffic from other traffic in the data center networks. By default, the vmk0 adapter on the ESX host is used. This replication path configuration can be modified and more details can be found in the documentation here on isolating the network traffic of vSphere Replication.
Once the sites have been configured with the DR (VLR) appliance(s) and the ESX hosts at each site properly connected, the site-to-site resource mappings can be configured. From here, the basic capabilities of VMware Live Recovery can be constructed and operated. This includes setting up the individual VM replications details and organizing VMs into appropriate Protection Groups. The Protection Groups can then be organized into one or more Recovery Plans where the specifics of the orchestration automation can be captured. Refer to the documentation to find out more about Using VMware Live Recovery.
With this traditional disaster recovery solution in place, it is possible to regularly and non-disruptively test the recovery capabilities and lower the risk of losing access to key operational infrastructure and quickly restore operations at an alternate recovery site from disasters like power outages, natural disasters and hardware failures.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



