

In this blog, with the release of VMware Cloud Foundation (VCF) 9.0, we explore three separate technical use-cases for VMware Private AI Foundation with NVIDIA. We show some of the high-level steps to achieve these use cases and give the rationale behind each one.
Use Case 1: Models as a Service
This use-case is for those enterprises that intend to use a platform-as-a-service (PaaS) approach for hosting large language models on-premises in VCF. Examples of models include the Llama, Mistral and other open families of models. These are used along with an enterprise’s private data to feed into those models for question answering. The “Models-as-a-service” theme captures the user experience of deploying AI in a very familiar way, such as users of public cloud AI for models may have experienced. The key difference is that both the model and the data used here is private and stored internally to the enterprise.
An important goal is that the technical infrastructure underlying the model runtime, and the data indexing/storage tooling should not be of concern for the end user. Instead, the end user focuses on services at the data science and application levels. Their concerns are mainly accessing running models of various kinds (completion models, embedding models and other models) and indexing their data for retrieval to create their AI applications with.
This approach gives the enterprise an alternate approach to using different sets of GPUs and servers to host separate instances of a model for different teams. Models can be re-used across applications. It enables the IT team to provide models as a service via a standard OpenAI compatible API. Behind the API, IT teams can horizontally scale models up and down based on load and do minor version upgrades with minimal impact to the end user.
For those users who want to be in full control of the underlying infrastructure, such as using VMs, we have a separate “GPU-as-a-Service” use case below. These two use cases may be implemented in the same VCF environment together. The two use-cases complement each other in their handling of the entire model adoption lifecycle, from the first downloading of a model from HuggingFace or other sources to its use in production. The use cases are supported by the VMware Private AI Foundation with NVIDIA, an advanced service based on VCF. The VMware Private AI Services (PAIS) within that VMware product provide the model runtime service, the data indexing and retrieval service and the agent builder service to cater for the user’s needs. The user here is not concerned with an underlying Kubernetes cluster that supports these AI services. We cover the basics of these three services here. More details on the service are given in the VMware Private AI Foundation with NVIDIA technical documentation.
An outline of the steps that a user would take in using the model runtime service to deploy model endpoints is shown below. Each of these Private AI services may be used through its GUI, its API or CLI. We show the user interface for the model store, based on Harbor, first, since that is the starting point for creating model endpoints. After a model is downloaded from HuggingFace, Meta, Mistral or other trusted sources, it is put through a series of validation tests in the AI Workstation that we discuss in the “GPU-as-a-Service” use case below.
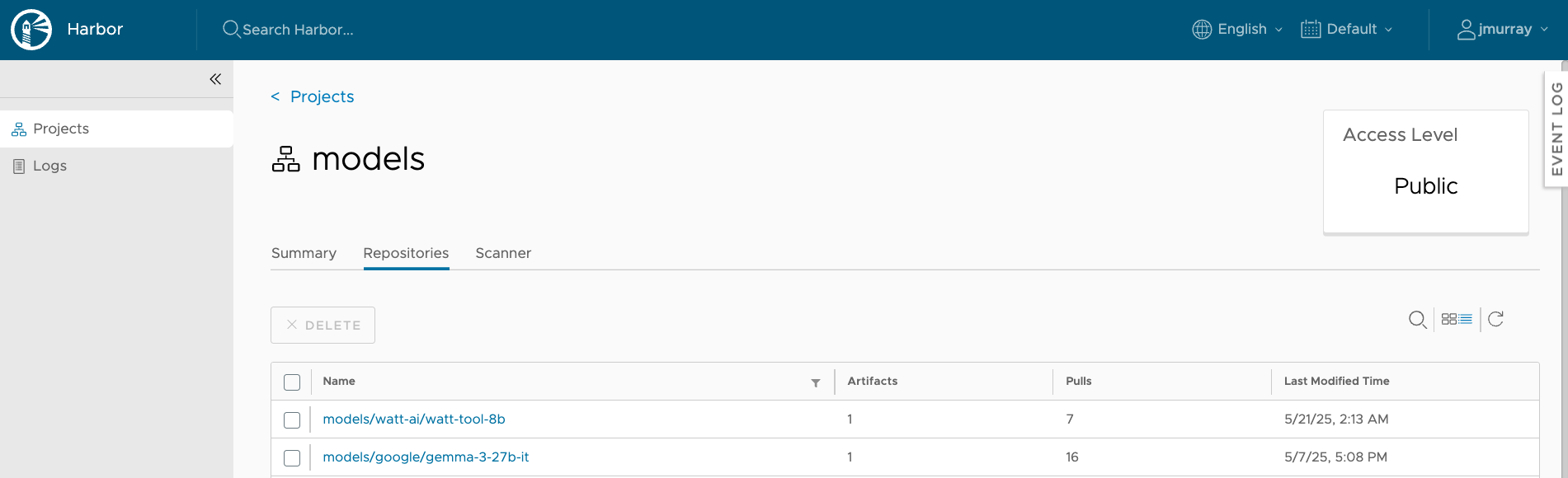
Once fully validated in that safe AI Workstation zone, the tested model is then pushed into the model store for use by other people – data scientists, LLM operations people and application developers. These users augment the model with private data sources and use it in business applications. To do that, first the model must be running – and that is done using the Model Runtime service that we see below. Users provide a reference to the stored model within Harbor, i.e. the Model URL, that we use to indicate the particular model (and version) that we want to be brought to life in this section. We are downloading from the model store and bringing the model to life so that it can be accessed using a model endpoint. A model endpoint is an access method to the running model that is used to invoke it to do some work.
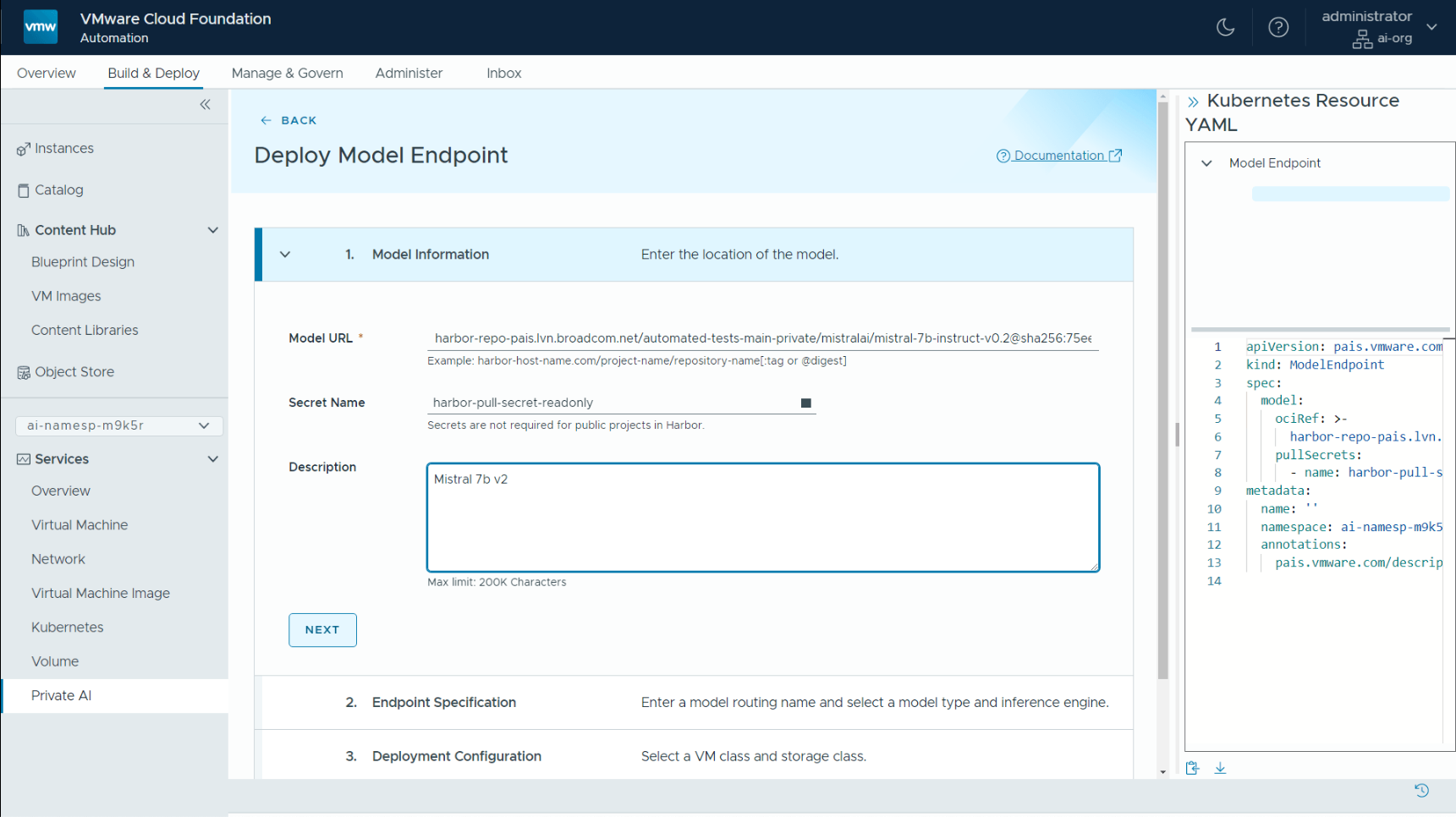
We also choose the GPU allocation (by selecting a pre-configured VM Class) that will accelerate this model endpoint in a separate step. We can choose between a GPU-enabled class and a non-GPU enabled class at this point, depending on what best suits the model.
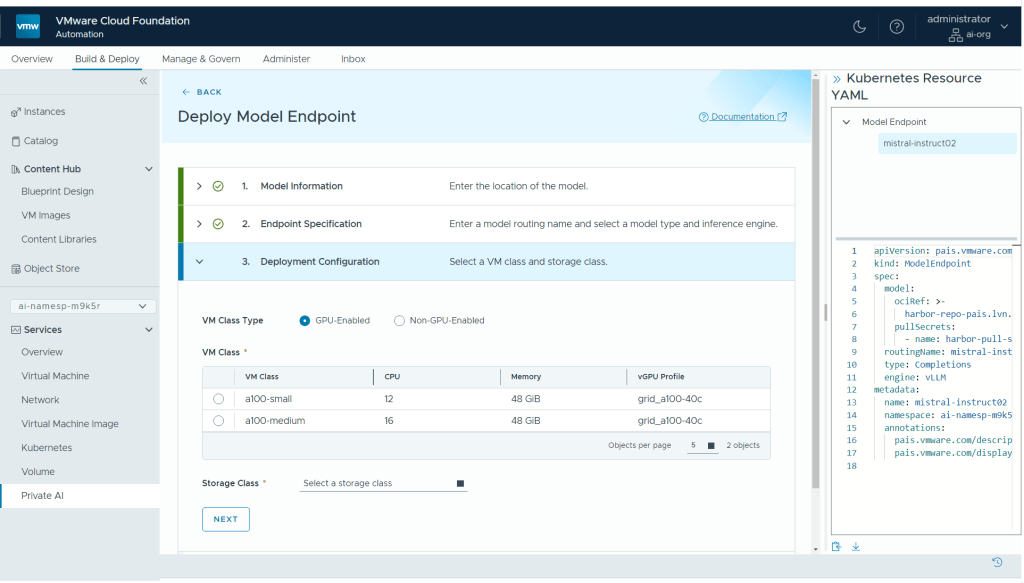
At the end of the Model Endpoint creation process, we see our existing set of endpoints, as seen below. We have created a completions model endpoint and an embeddings model endpoint. The embeddings model endpoint is used in converting our private data so that it can be loaded into the vector database. More detail on this model endpoint creation step is given in a separate article on this subject.
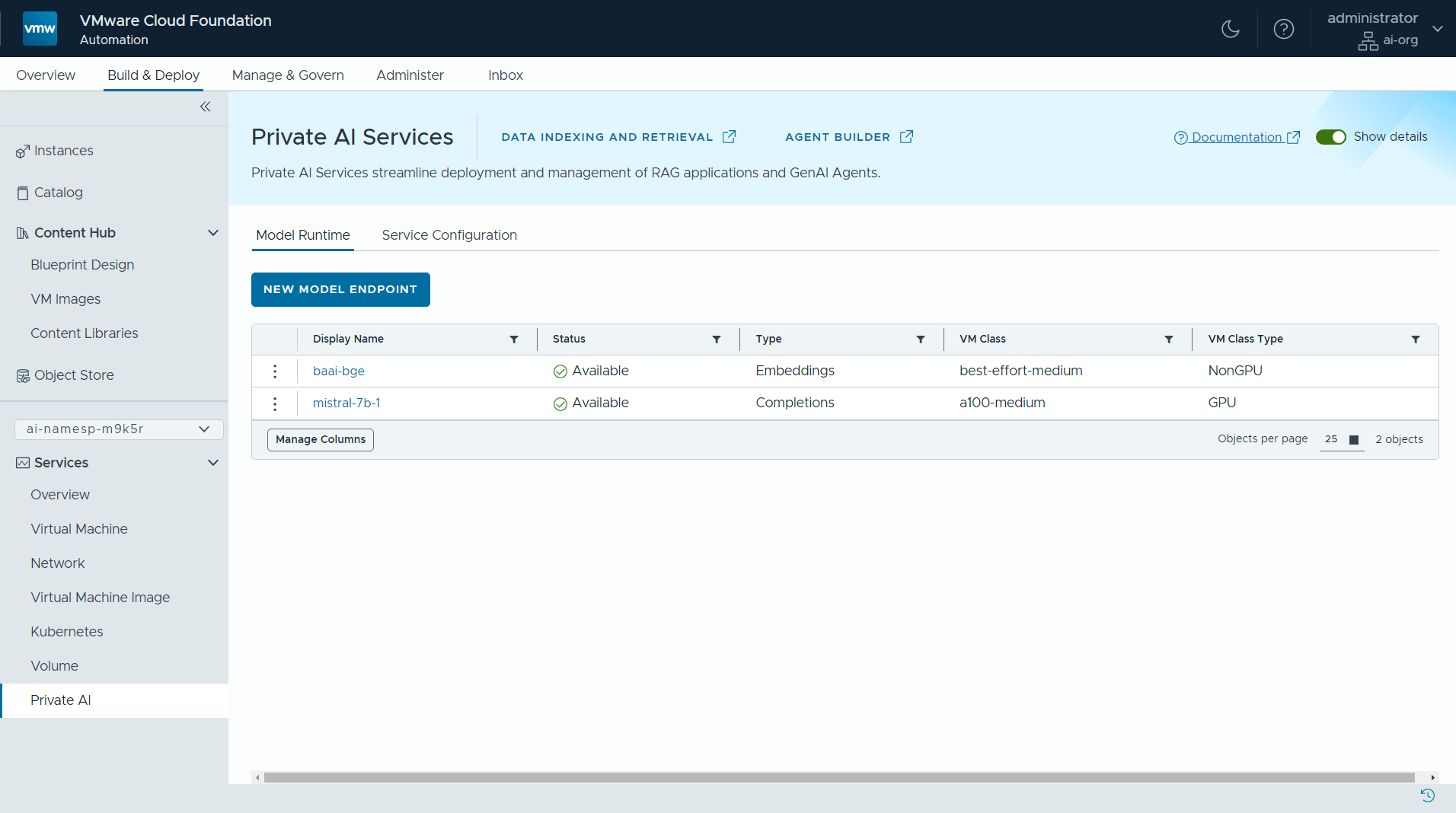
Once we have our completion, embeddings or other models running and accessible via individual endpoints, we move on to dealing with the private data that will augment the model.
Private Data Access
To use the enterprise private data along with the model, we create a “knowledge base”. This will be used for chunking, indexing, storing and retrieving our private enterprise data using an underlying vector database. A knowledge base is a collection of data source references that can be processed by an embeddings model, to translate the chunked data to embeddings. These are numeric representations of the text in our documents, with metadata, that are suitable for similarity or semantic searches. Those embeddings are indexed and stored in a local vector database when we invoke “indexing” on a knowledge base.
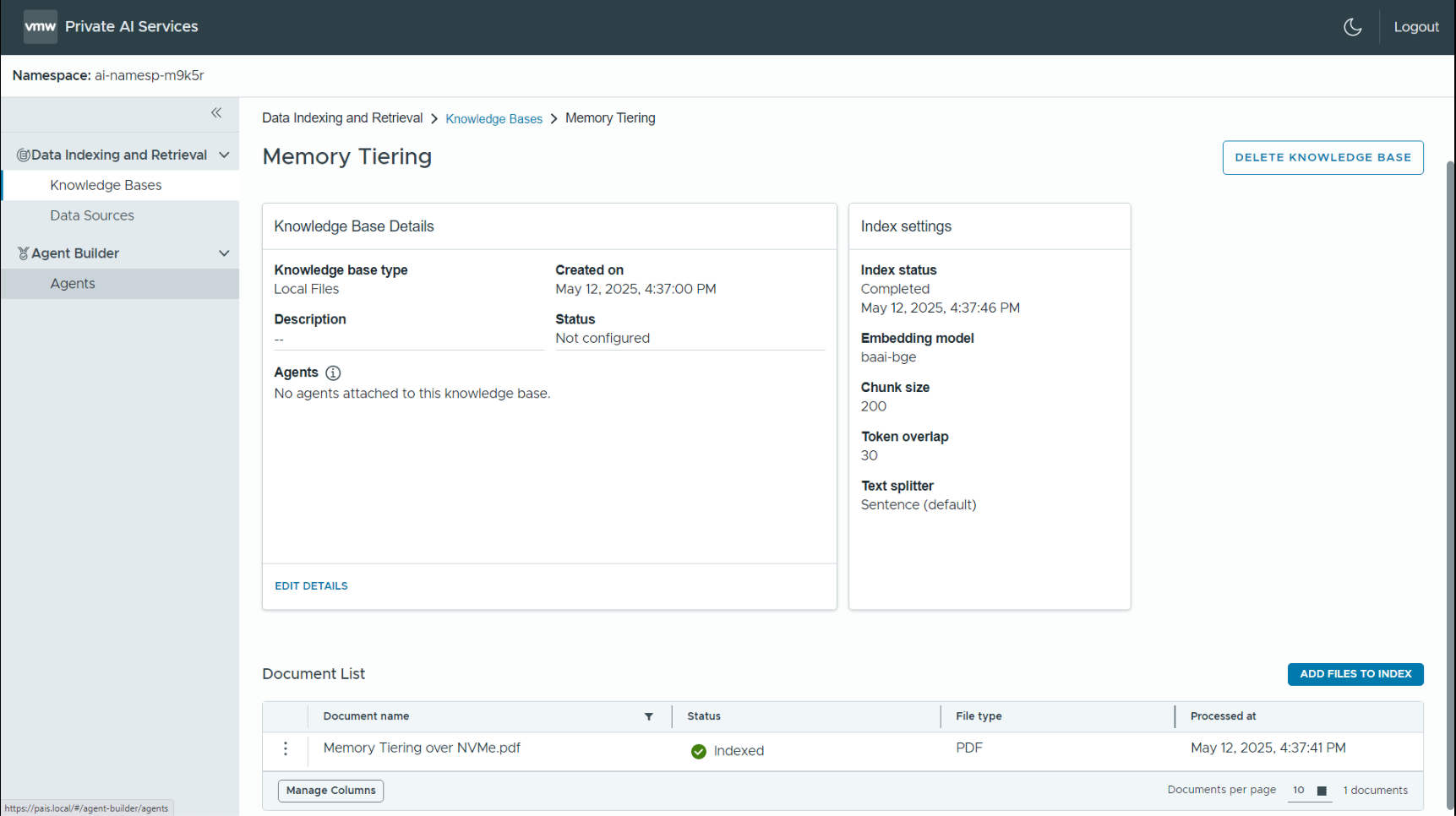
The end result of creating a knowledge base from various data sources and executing the embedding model on it is shown below. In our example, we used local files as data sources for simplicity. We use the BGE embeddings model to process that data for loading. Along with the local PDF documents we placed into this knowledge base, many other data source types are available to us, including Sharepoint directories, Google drives, S3-compatible stores, Confluence pages and others.
We can add new data sources to the knowledge base and trigger a re-indexing and database reload process at suitable intervals, to keep our private data up to date. The knowledge base is used to supply answers to queries and therefore augment the main completions model in a separate step. Hence the name “retrieval augmented generation” for this design approach. This design allows us to avoid the re-training of a model when new business data appears.
The knowledge base example created here is based on a chosen subject area called “memory tiering”. But it could be done on any topic with documents that are private and important to the business.
Agent Builder
Now that we have an indexed knowledge base and a model endpoint for our completions Mistral model, we can combine the two to create an agent, using the Agent Builder service. The resulting agent is a router of incoming queries/prompts, first to the knowledge base and then to the completions model to generate an appropriate answer to a user’s question. We should mention here that a knowledge base can be used by multiple agents to save on storage of the underlying VectorDB.
Here is a view of the Agent Builder service with a new agent that was built from a completions model endpoint, called mistral-instruct02, and an indexed knowledge base named “Memory Tiering” that we saw earlier. During the Agent Builder creation process, we can add further instructions and advanced settings to the model endpoint to guide its behavior if we need to.
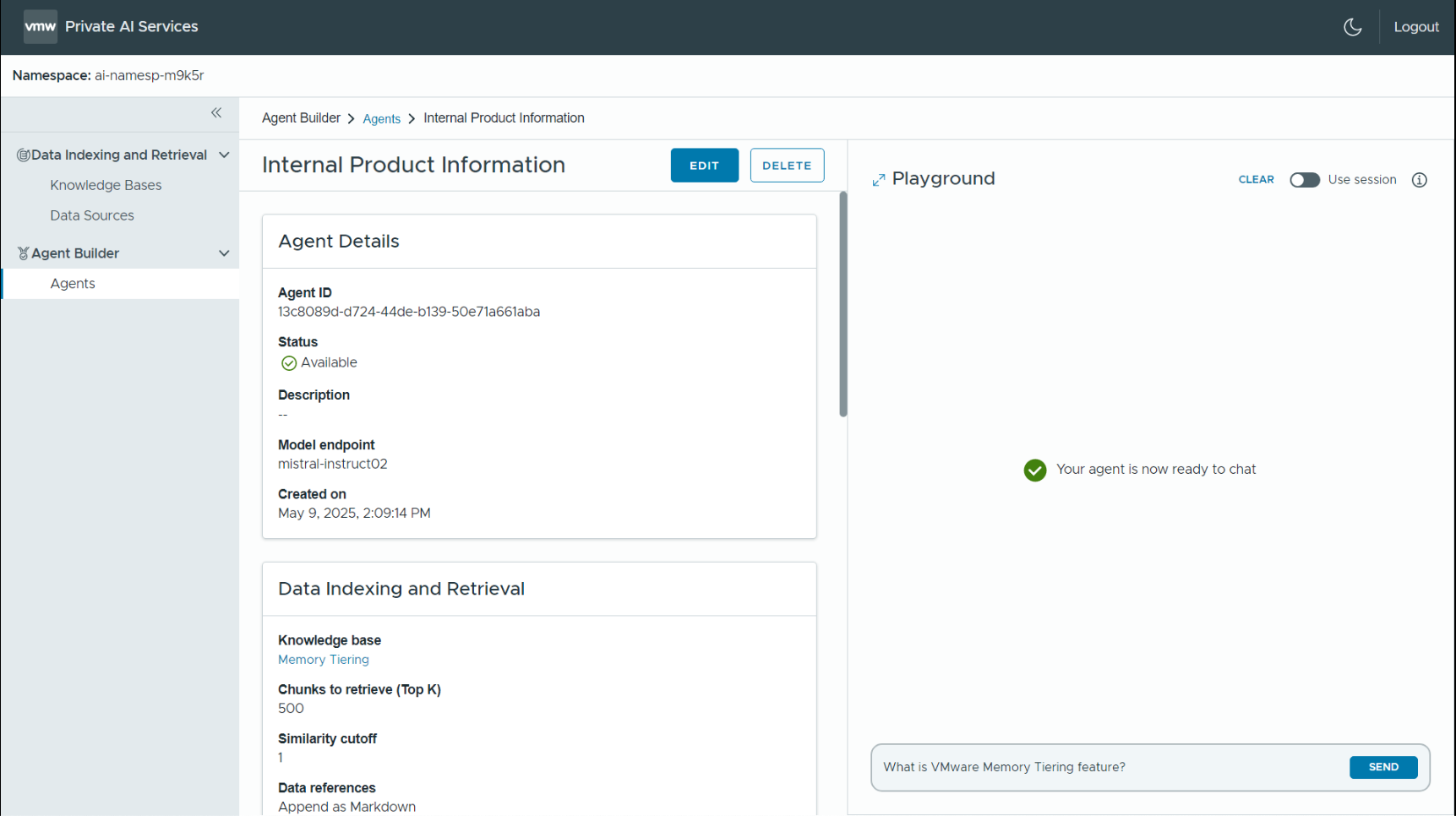
The new agent may be used through its OpenAI-compatible API by a front-end application to carry out this work. Example use-cases of an agent include invoking it from an Open WebUI front-end application. The screen above shows, on the right panel, the built-in interface to the agent to execute a RAG process to answer the user’s question about the VMware Memory Tiering feature. That subject matter represents private data to a company, that may not be public at this point in time. This is an example of an internal AI tool using private data to answer a staff member’s question.
So far, we have seen the steps using the Private AI Services within VMware Private AI Foundation with NVIDIA to use models as a service with indexed data. We now go deeper into the GPUs-as-a-Service, looking at the infrastructure layer.
Use Case 2: GPU-as-a-Service
As we deployed the VMware Private AI Foundation with NVIDIA as an advanced service on VMware Cloud Foundation, it quickly became clear that a starter AI use-case was very popular with users. This use-case involves the deployment one or more deep learning VMs or “AI Workstations” with virtual GPUs attached to them for experimental work by data science personnel. A deep learning VM is a regular VM on VMware Cloud Foundation with some extra configurations for GPU awareness. To this end, the deep learning VM image that is used in provisioning an AI Workstation is configured as follows:
-setup with the correct IOMMU parameters for handling vGPUs
-EFI booted guest operating system (Linux 22.04
-reserved main memory to match or exceed the framebuffer memory amount in the GPU
-pre-configured Conda, PyTorch, Docker runtime and Jupyter Lab for Notebooks
-the NVIDIA GPU Cloud (NGC) command line interface tool already available
-the ability to reach either an NVIDIA repository of containers on the internet, or a private repository of containers on premises
-ability to contact an NVIDIA Licensing Server, either in the cloud or an on-premises deployment, to correctly license the NVIDIA vGPU driver
AI Workstations, implemented as deep learning VMs, are deployed by the VCF Automation tool after it has been configured with a guided Private AI Quickstart setup process. The catalog items shown below are created initially by the administrator in Quickstart to identify a number of preset items for them (such as the available VM classes) and these may be edited later if needed. The catalog items shown below are then presented to the end user in the Service Broker tab in VCF Automation.
Within the Service Broker, there is a brief dialog to specify some remaining end-user needs (such as their GPU requirements, encapsulated in VM classes and what software bundle they will use, PyTorch, TensorFlow, RAG, etc.). The provisioning process then makes use of a VM image that is shipped by Broadcom as part of the VMware Private AI Foundation with NVIDIA advanced service for VMware Cloud Foundation. The VM image is stored in a content library for use in cloning new “AI Workstation” requests that you see in the user interface below. Provisioning is invoked by requesting one of a set of catalog items as shown.
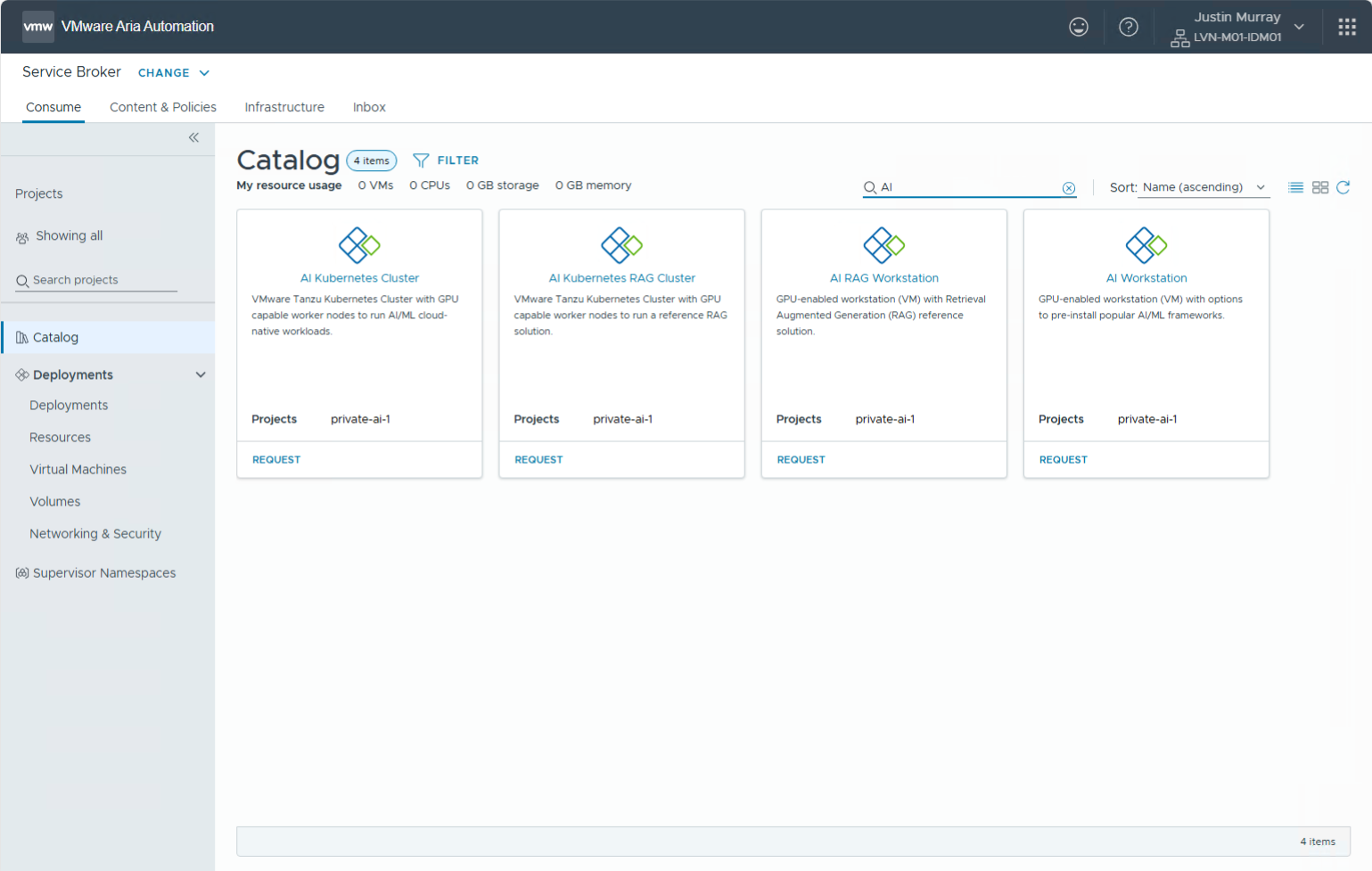
When a user chooses the “AI Workstation” or “AI RAG Workstation” requests from the above screen, a deep learning VM is created from the stored VM image with the GPU power that they need attached to it. Users express their preferences regarding GPU type and capacity via a VM Class object that is seen in the dialog below. The set of allowed VM classes is configured in advance of this request by a systems administrator at Quickstart time. This allows administrators to restrict access to certain GPU combinations and subsets. The user chooses the particular VM class they would like to use, from a given set.
Here we are chose to use the VM class named “a100-20c-gpu” that allows 20 GB of framebuffer memory to be used on an A100 GPU.
We can see that other choices of VM classes representing different GPU allocations are available, as a result of the administrator allowing those in the Quickstart process.
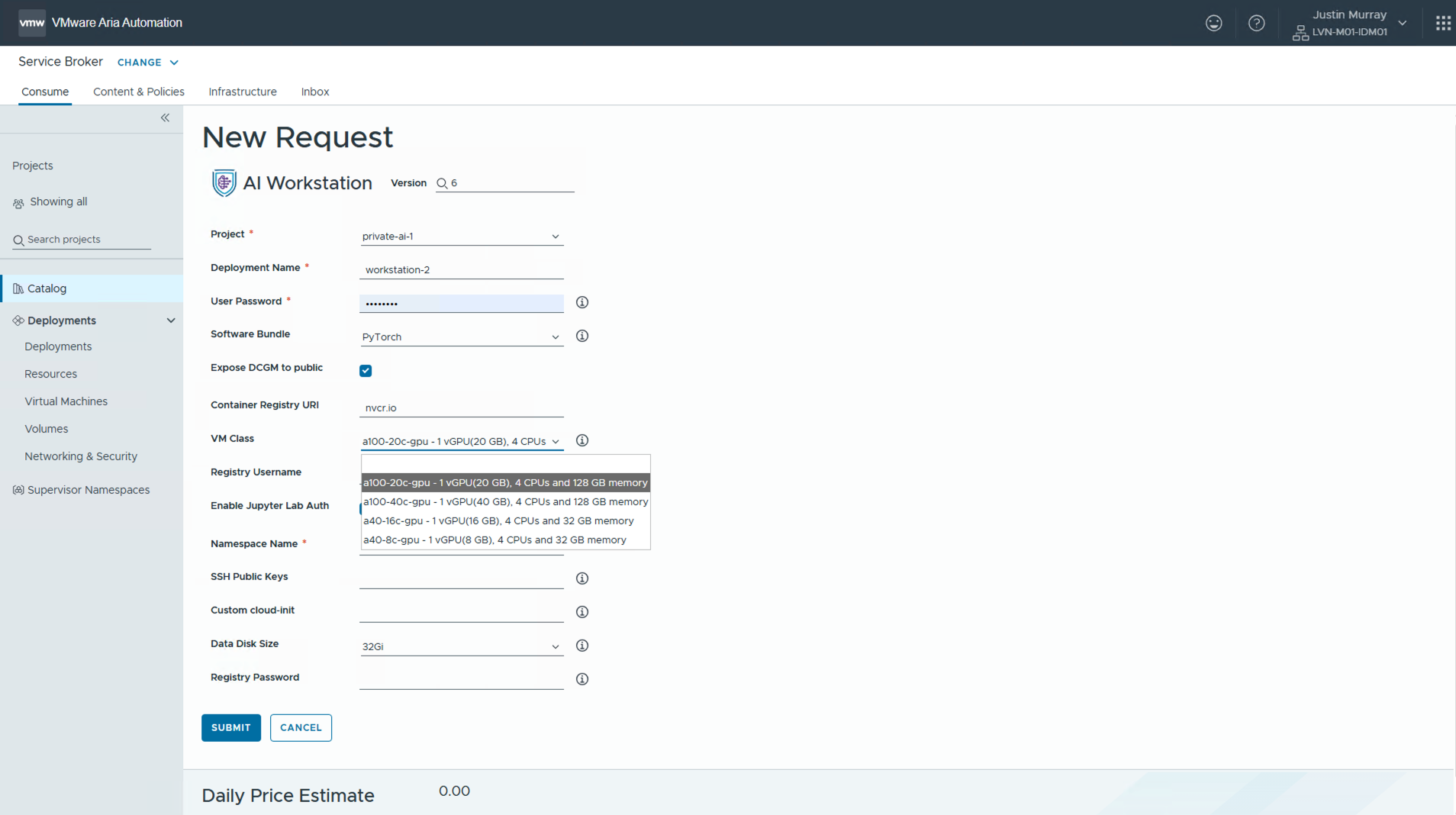
A set of VM classes is constructed by the administrator ahead of time using different vGPU profiles. The choice of vGPU profiles is fixed in advance depending on the physical GPU detected in hardware. A platform engineer may limit the allowed combinations of GPUs and the partial GPUs that a user may request, by constructing the appropriate VM class objects. For example, we can allow VM class objects to use a vGPU profile with 20 GB or 40GB of framebuffer memory from the total GPU memory hardware that is present.
A second choice that is made by the user is the bundle of software that will be loaded into the deep learning VM at startup time. In this case, we chose “PyTorch” but other bundles can apply, based on the NVIDIA microservices that will be available to the user.
Once the user chooses these options and hits “Submit” then the VCF Automation tool takes over and creates the new VM with all appropriate contents and configuration. At the end of the deployment process, the user may use their new VM by clicking on the JupyterLab URL shown under Applications below in the final page from the Automation.
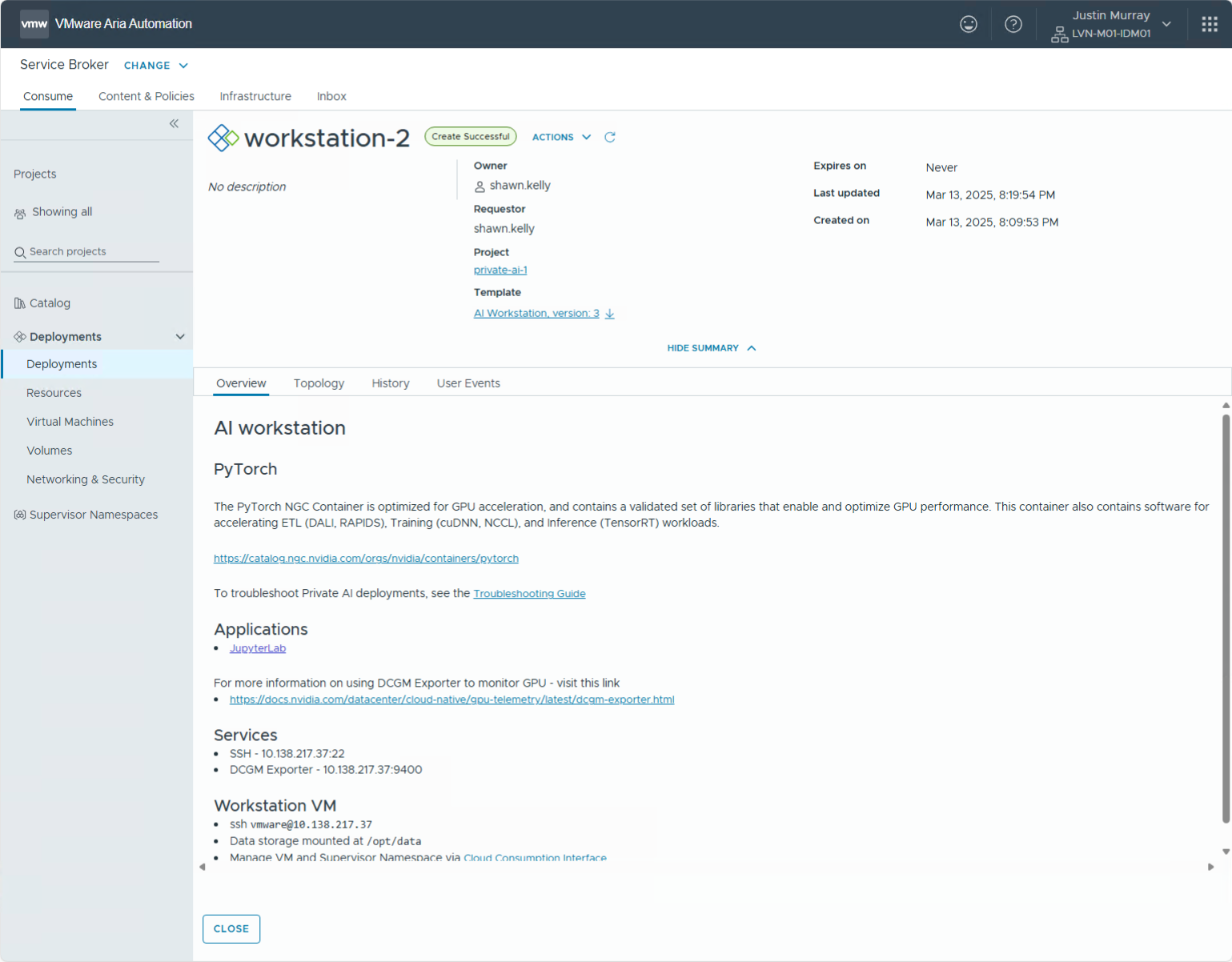
This will then take the user into their JupyterLab Notebook environment directly, as seen here.
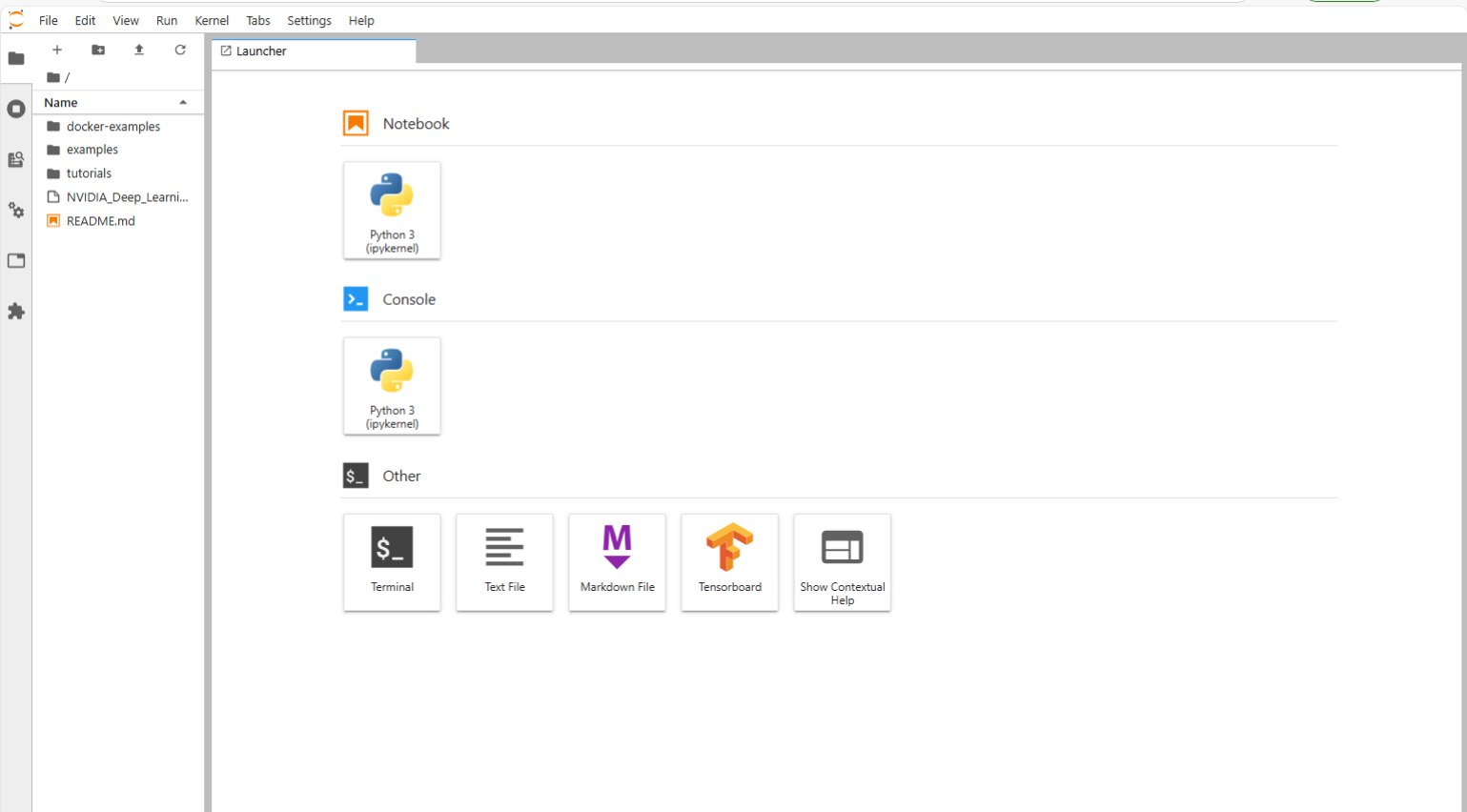
The end-user or data scientist can now proceed to work on their application development while utilizing the vGPU that has been allocated to their deep learning VM. All conditions including the NVIDIA guest driver that must be present are set up in the VCF Automation tool.
If the systems administrator were interested in seeing how much GPU capacity was being allocated to that user’s VM they could see that through the vSphere Client, by first identifying the correct VM and then looking more closely at it as shown here.
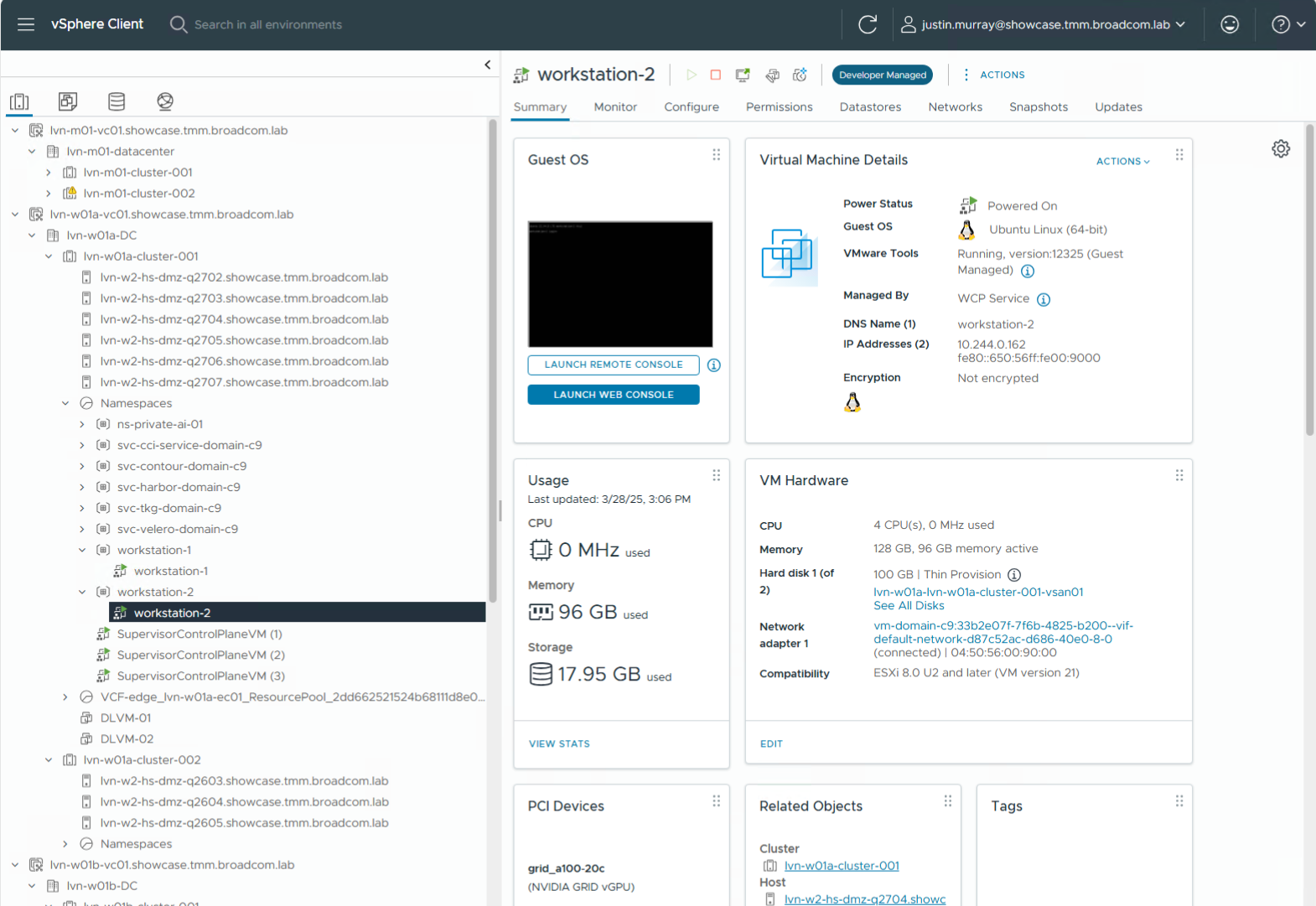
We can see in the PCI Devices pane at the bottom of the screen, the 20GB of GPU framebuffer memory from an A100 GPU has indeed been allocated to the new VM, as requested.
Users of the VM provisioned above may be unaware of the virtualization layer or that they are working within the confines of a VM with limited memory capacity from the GPU. Should that environment not be satisfactory for their needs, the platform engineer can provision a further, higher-specification AI workstation for them without consuming much extra time.
Use Case 3: Private AI as a Use Case for VMware Cloud Foundation (VCF)
When we introduce the VMware Private AI Foundation with NVIDIA to new customers, we sometimes get questions such as “Why would we use VCF for AI or GenAI types of workload” and “What advantages do I gain by doing so?” This section provides answers these questions. We show here that applications using the VMware Private AI Foundation with NVIDIA are great use-cases for VCF. In this section, we want to explore that theme in more depth.
Simplifying and automating the provisioning of data scientists/AI workers’ environments, as seen in the previous section above, is one key use case of VMware Cloud Foundation. The goal there is to remove as much of the infrastructure details and concerns from the data scientists’ world by automating as much as possible. The user fills in one simple form that describes what they want as far as GPU power and base software tooling is concerned and the automation does the rest.
Further to provisioning these environments, the AI workloads can be managed from Day 2 onwards alongside the more traditional kinds of workload in a similar way in your data center. This allows you to deploy staff that are already familiar with VCF to now manage the lifecycle of new AI applications in the same way as older, traditional applications, without having to put them through extensive re-training. The tools used to effectively manage Private AI workloads are already familiar to them, such as VCF Operations and vCenter.
The questions we explore here are
- Why is VCF suited to hosting and managing Private AI applications, in particular,
and
- What parts of VCF are used to great effect in VMware Private AI?
- Why is VCF Best Suited to Private AI Use Cases?
To understand why VCF is an ideal platform for doing Private AI work, we first want to understand what the users and developers of AI are engaged in on a day-to-day basis. For this, we looked at our own data scientists to understand their regular activities. This diagram summarizes those findings.
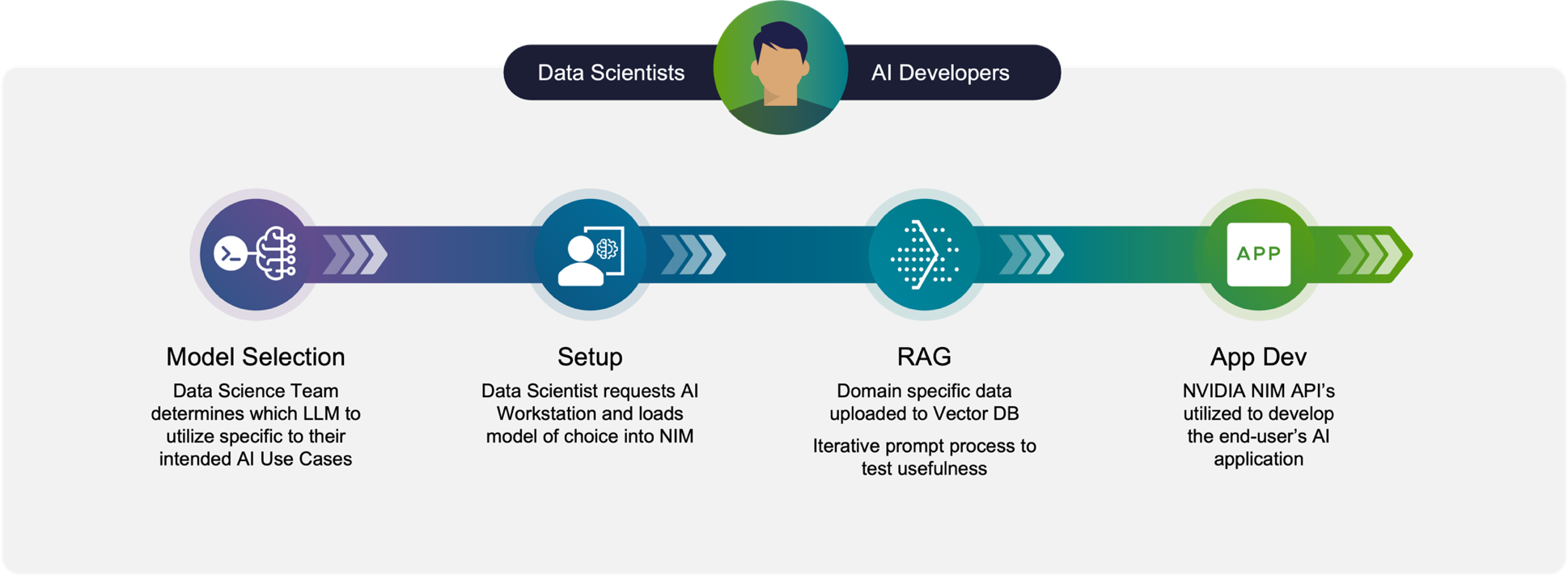
Data scientists and data engineers spend considerable time trying out and validating the new open-weights, commercially usable, models that appear on the market almost on a weekly basis. Their task here is to make a choice among the various models for suitability to their business applications. There are thousands of these models out there now on public model repositories such HuggingFace, Meta sites or the NVIDIA GPU Cloud (NGC) website. Some of these models have achieved wide acceptance among the data science community for use in an on-premises context, such as the Llama family of models from Meta. Model selection, validation and testing has already become an important process in itself. That validation process is repeated with new models, new datasets, new model hyper-parameters and new runtime environments, regularly.
This workflow calls for a repeatable, scalable and re-configurable environment in which many experiments can be done alongside each other, but not necessarily require a dedicated hardware platform of their own. That environment is essentially one composed of VMs that provide rapid provisioning, de-provisioning and repeatability of the software stack, from one experiment to the next. The flow of work along the timeline shown above is replicated many times over by one data scientist or application developer. Testing a model for its accuracy and performance requires many test iterations, for example.
The workflow is also replicated by teams of data scientists who work on different models with different datasets and environmental conditions. They may be using fewer or more GPUs than other teams, for example. So that horizontal pattern seen above is repeated many times over. Tearing down and re-configuring your bare metal hardware setup on each change is just not feasible for this highly experimental, fast-moving world. VMs hosted on VMware Cloud Foundation provide the means of separating and scaling, while also supporting repeatability of experiments with varying conditions. VCF is a great way to achieve these goals, while maintaining privacy of your business data within the enterprise.
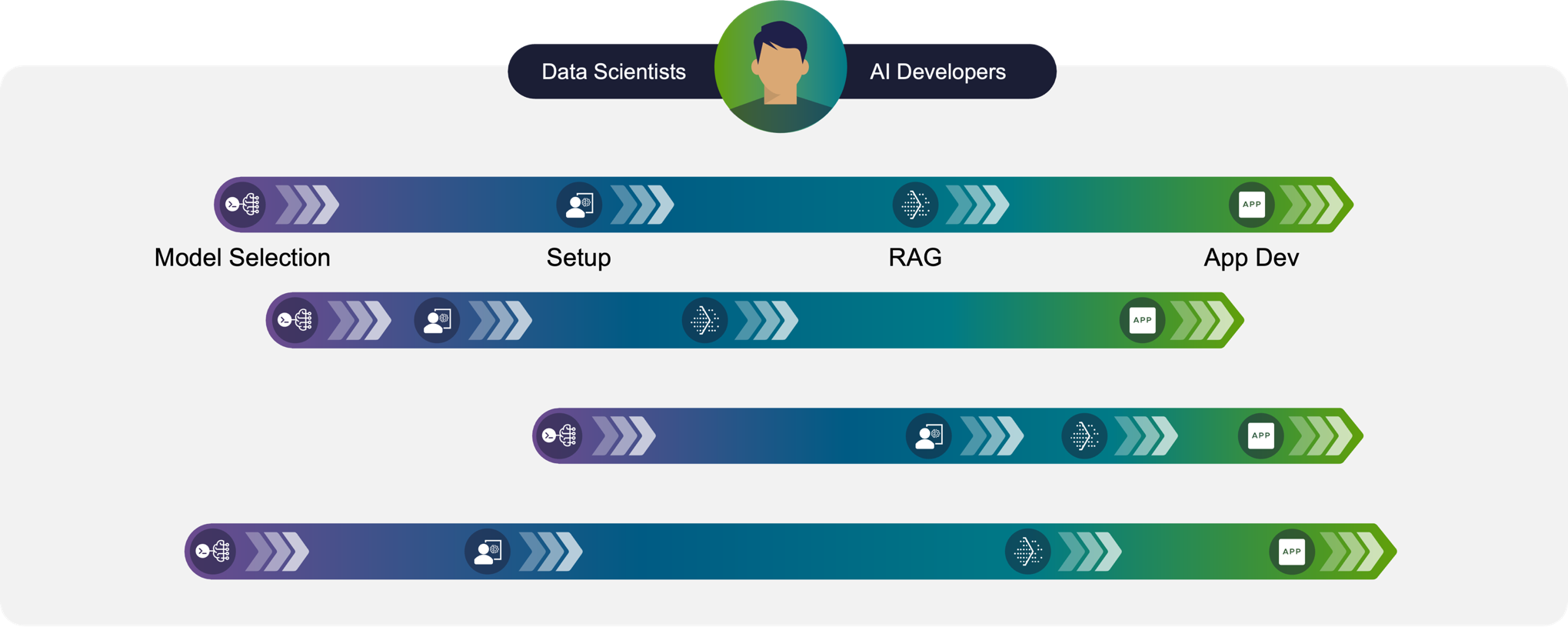
The capability to manage hundreds or even thousands of VMs from one place is what VMware Cloud Foundation brings to the data scientist’s world, along with the security and repeatability that is built into the platform to protect your private data. As one important example of the use of VMware Private AI Foundation with NVIDIA, the Retrieval Augmented Generation (RAG) design allows you to keep your data within your enterprise for safety reasons, while making use of a quality-tested LLM to process that data into a digestible form for users. In a RAG design, the private company data is protected by virtue of it being held in a controlled internal vector database environment. The authorized data that is retrieved on a query from the vector database is fed to the LLM for processing during the processing of a question. Deploying this combined database and LLM working together through VMware Private AI Foundation with NVIDIA is a prime use case among enterprises using VCF.
With VCF based on-premises, the IT team has full control over the performance and SLAs of the system, in a much more detailed way than they would on a public cloud. From visibility of the GPU consumption, to the storage, networking and security aspects, there is more tooling in the hands of the systems administrator – so that they can adjust the setup to provide a better SLA for their end-users. You can move live AI workloads around in your data center, should you need to for maintenance reasons, or for load balancing, for example. This is next to impossible to achieve without virtualization as the underlying operating model.
A full collection of AI-specific innovations is incorporated into the VCF tooling to exercise this Deploy Private AI use case. We will describe these next.
What Parts of VCF Support Private AI Use Cases?
Automating the Creation of Data Science Environments (day 1)
VMware Cloud Foundation eases the provisioning of any VM-based environment through the VCF Automation tool. This tool has been enhanced with blueprints that specify exactly what needs to be done for an “AI Workstation” or an “AI Kubernetes Cluster” with several variants of those items, including RAG-focused versions of each AI Workstation and AI Kubernetes Cluster. The full bring-up of such an environment involves many infrastructure steps (creating the VMs, assigning networking and storage, arranging persistence and placing under the management of a DRS cluster) as well as the loading of a chosen LLM into a runtime and all the components to exercise it from the NVIDIA GPU Cloud and from elsewhere.
In an air-gapped environment, all components are accessed from a local repository, based on Harbor, having been staged there earlier. This is coordinated by the VCF Automation blueprints, that have the logic built into them to do the right downloads and eventually invoke the appropriate microservices/containers – and manage their lifecycle. These Automation blueprints and scripts are open to being customized to your specific needs (such as a change from one model to another).
Managing the Data Science Environment in the Data Center (day 2)
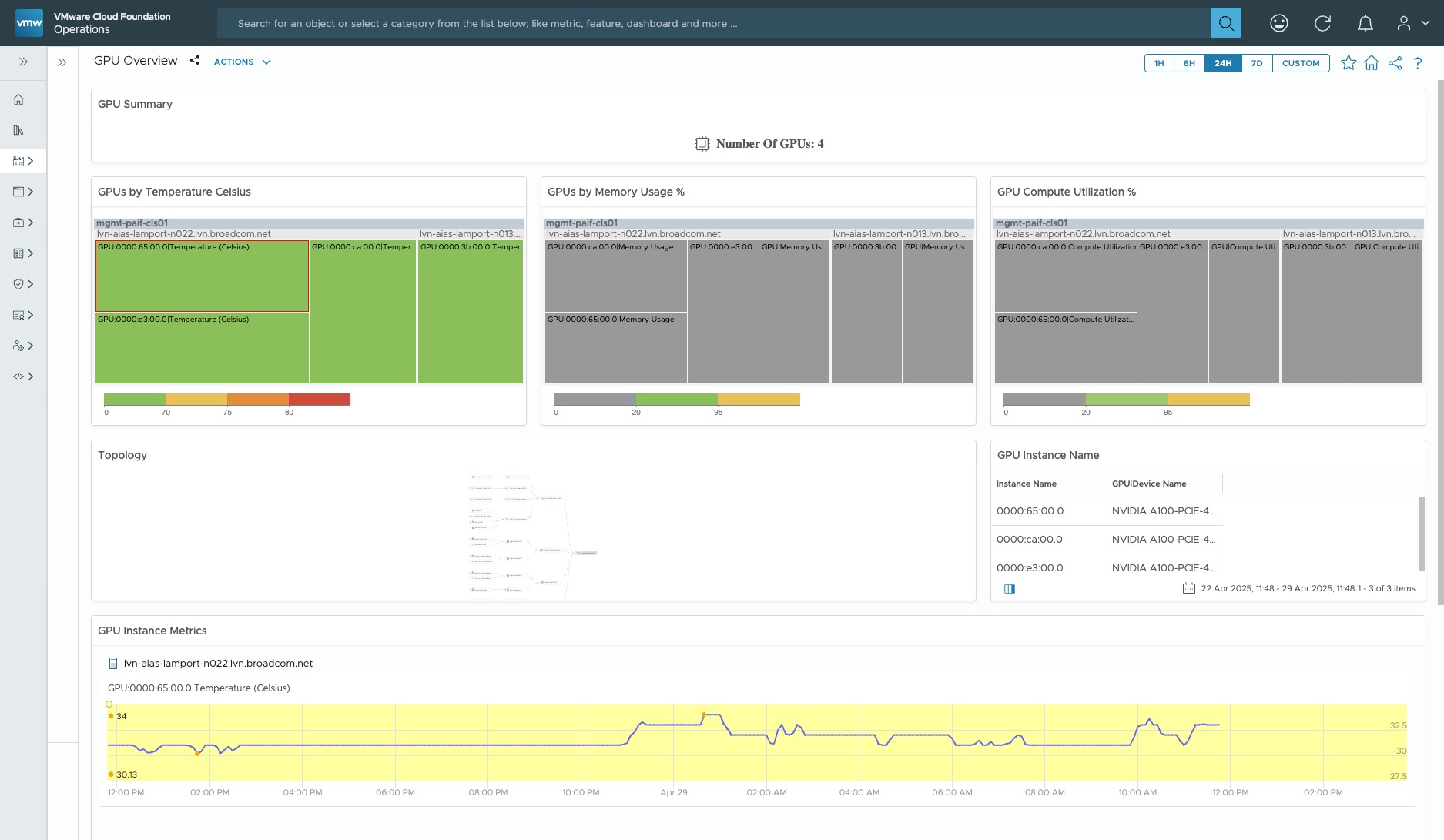
From the moment a significant AI application is deployed that uses the VMware Private AI Foundation with NVIDIA, that application needs to be carefully monitored and managed at all of the various layers in it, from the hardware all the way up to the model and its consuming application. VCF enables this through a combination of customized views in VCF Operations, the vSphere Client User Interface, telemetry data that can be retrieved and stored locally for analysis. Two examples of this monitoring and management tooling from VMware Cloud Foundation are given here. The first is an image of the physical GPU consumption shown in VC Operations dashboard. Each colored block represents a particular GPU. There are summary dashboards that show the GPU-equipped clusters and hosts, as well as a drill-down to a particular physical GPU. In VCF Operations 9.0 we can also see the vGPU metrics.
With the vSphere Client in VCF 9.0, we also get deeper insight into the levels of consumption at the vGPU level, through a new feature called “DirectPath Profiles”. You can create these DirectPath Profiles in the vSphere Client to suit your needs, including the vGPU profile that you are interested in viewing. A DirectPath Profile will also be created automatically for any currently running VM that does not have one already. The details of these DirectPath Profiles will be described in detail in a following article. For now, we show you a summary of the Utilization screen that you get in the vSphere Client at VCF 9.0 to help you understand what is consumed, available and not usable for any vGPU profile.
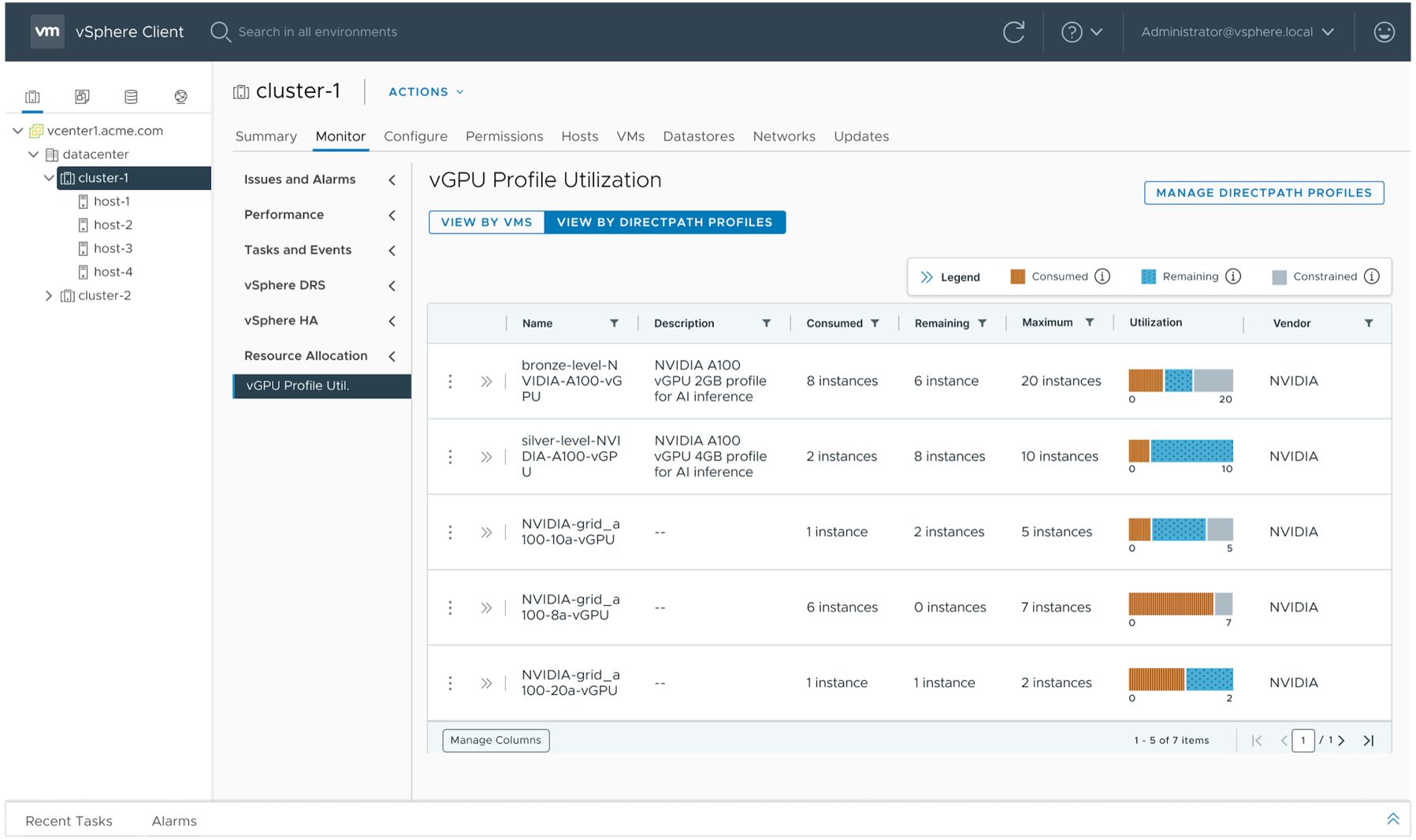
This is a powerful tool for assessing consumption and for capacity planning based on the unused capacity of your vGPU profiles.
Summary
In this article we explore the use cases for VMware Private AI Foundation with NVIDIA. We take three examples here
(1) Models-as-a-Service that uses the model store, model runtime, data indexing and retrieval and agent builder services that are new in VCF 9.0
(2) GPUS-as-a-Service, achieved through deployment of a deep learning VM that has one or more vGPU profiles assigned to it
(3) Private AI as a use-case for VCF itself and how the VCF tooling supports the creation, management and scaling of a data science environment for its end-users.
The key message in this article is that VMware Cloud Foundation 9.0 along with the VMware Private AI Foundation with NVIDIA advanced service together give you a powerful platform for building and running your AI applications in production in your data center, alongside other virtualized applications. The tools that your administrators are used to using in the data center have been extended to now also be used to monitor and manage the new AI generation of applications. The goal is to get you going quickly on making AI work for your business.
***
Ready to get hands-on with VMware Cloud Foundation 9.0? Dive into the newest features in a live environment with Hands-on Labs that cover platform fundamentals, automation workflows, operational best practices, and the latest vSphere functionality for VCF 9.0.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





