
1. Introduction
VMware Private AI Foundation with NVIDIA is a joint GenAI platform by Broadcom and NVIDIA that helps enterprises unlock GenAI and unleash productivity. With this platform, enterprises can deploy AI workloads faster, fine-tune and customize LLM models, deploy retrieval augmented generation (RAG) workflows, and run inference workloads in their data centers, addressing privacy, choice, cost, performance, and compliance concerns. Now Generally Available, the platform comprises NVIDIA AI Enterprise, which includes NVIDIA NIM microservices, NVIDIA LLMs, and access to other community models (such as Hugging face models) running on VMware Cloud Foundation™. This platform is an add-on SKU on top of VMware Cloud Foundation. NVIDIA AI Enterprise licenses will need to be purchased separately.
Summarize-and-Chat is an open-source project for VMware Private AI Foundation with NVIDIA that offers a unified framework for document summarization and chat interactions using large language models (LLMs.) The project provides two main advantages:
- Concise summaries of diverse content (articles, feedback, issues, meetings)
- Engaging and contextually aware conversations using LLMs, enhancing user experience
This solution helps teams quickly implement GenAI capabilities while maintaining control over their private data by leveraging VMware Private AI Foundation with NVIDIA.
Deploying Summarize and Chat on PAIF-N
In this blog post, we will walk you through deploying the components of Summarize and Chat on VMware Private AI Foundation with NVIDIA.
- Deep Learning VM (DLVM) – Runs LLM inference engine on vLLM (embedding model service, re-ranker model service, QA model service, and summarization model service).
- AI GPU-enabled Tanzu Kubernetes Cluster will host the summarize and chat service components.
- Summarizer-server – FastAPI gateway server to manage core application functions, including access control. It uses the inference services provided by a DLVM.
- Summarizer-client – Angular/Clarity web application powered by summarizer-server APIs.
- PostgreSQL database with pgvector – The database is used to store embeddings and chat histories. We encourage users to deploy it with VMware Data Services Manager (DSM.)
- vSAN File Services – Provides persistent data storage volumes for the Kubernetes pods running on the Tanzu Kubernetes Cluster.
We will start by deploying a deep-learning VM (DLVM) from VCF Automation’s Service Catalog based on the following considerations:
- Since we are building a customized set of software components, we will not select any software bundle, so only the NVIDIA vGPU Driver is needed.
- When describing the requirements for each NIM, we provide the amount of GPU memory that will be required. In summary, you will require the following to run the embedder, re-ranker, and LLM NIMs:
- One GPU (or partition) with 2989MiB of GPU Memory to run the embedder NIM.
- The re-ranker NIM requires one GPU (or partition) with 11487MiB of memory.
- The LLM NIM requires four GPUs (or partitions), each with 35105MiB of memory.
- The NIM services can run on the same or different VMs.
- The size disk should have at least 600GB to store the required models and data and change the software bundle selection to none.
- Fill out the rest of the form as the image shows and submit it.
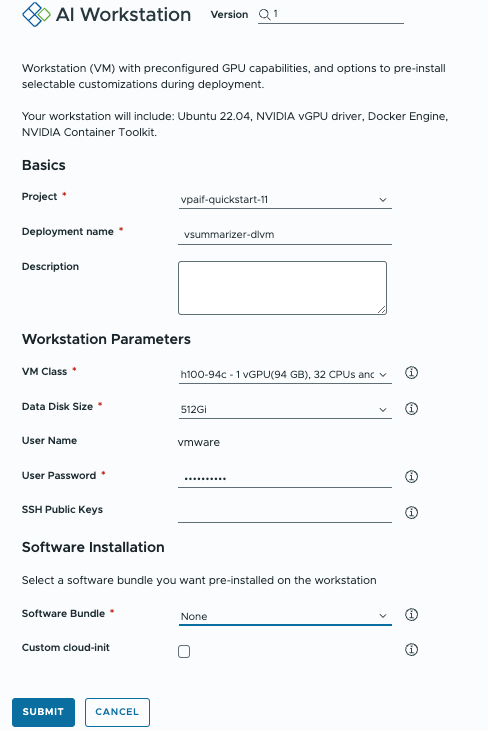
This will deploy a Deep Learning VM with the correct vGPU Guest Driver based on the underlying infrastructure and will be ready for us to start downloading and setting up the right components.
Log into your Deep Learning VM via SSH and confirm that the vGPU Driver was installed and licensed using the nvidia-smi command. You can optionally verify that the license status for each vGPU device is active with the nvidia-smi -q command.
Output of the nvidia-smi command:
nvidia-smi
# Wed Oct 9 13:27:52 2024
# —————————————————————————————–+
# NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
# —————————————–+————————+———————-+
# GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
# Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
# | | MIG M. |
# =========================================+========================+======================|
# 0 NVIDIA H100XM-40C On | 00000000:03:00.0 Off | 0 |
# N/A N/A P0 N/A / N/A | 0MiB / 40960MiB | 0% Default |
# | | Disabled
# —————————————–+————————+———————-+
# 1 NVIDIA H100XM-40C On | 00000000:03:01.0 Off | 0 |
# N/A N/A P0 N/A / N/A | 2990MiB / 40960MiB | 0% Default |
# | | Disabled |
# —————————————–+————————+———————-+
# 2 NVIDIA H100XM-40C On | 00000000:03:02.0 Off | 0 |
# N/A N/A P0 N/A / N/A | 11502MiB / 40960MiB | 0% Default |
# | | Disabled |
# —————————————–+————————+———————-+
# 3 NVIDIA H100XM-40C On | 00000000:03:03.0 Off | 0 |
# N/A N/A P0 N/A / N/A | 1705MiB / 40960MiB | 0% Default |
# | | Disabled |
# —————————————–+————————+———————-+
# 4 NVIDIA H100XM-40C On | 00000000:03:04.0 Off | 0 |
# N/A N/A P0 N/A / N/A | 35213MiB / 40960MiB | 0% Default |
# | | Disabled |
# —————————————–+————————+———————-+
# 5 NVIDIA H100XM-40C On | 00000000:03:05.0 Off | 0 |
# N/A N/A P0 N/A / N/A | 35115MiB / 40960MiB | 0% Default |
# | | Disabled |
# —————————————————————————————–+
# Processes: |
# GPU GI CI PID Type Process name GPU Memory |
# ID ID Usage |
# =========================================================================================|
# 0 N/A N/A 51411 C tritonserver 2989MiB |
# 1 N/A N/A 128418 C tritonserver 11487MiB |
# 2 N/A N/A 4798 C /opt/nim/llm/.venv/bin/python3 35203MiB |
# 3 N/A N/A 33056 C /opt/nim/llm/.venv/bin/python3 35105MiB |
# 4 N/A N/A 33062 C /opt/nim/llm/.venv/bin/python3 35105MiB |
# 5 N/A N/A 33063 C /opt/nim/llm/.venv/bin/python3 35105MiB |
# —————————————————————————————–+
2. Launching NVIDIA NIM Services in a Deep Learning VM
In this section, you’ll find the shell scripts used to launch the NVIDIA NIM services required to power the summarization service. The services are:
- Embedding of text strings (sentences, paragraphs, etc.)
- Re-ranking text passages according to their semantic similarity or relevance to a query.
- Text generation by large language models (LLMs).
You’ll need multiple GPU resources to run the different NIMs as indicated below. Our tests used a DLVM with six H100XM-40C GPU partitions, each with 40GB of GPU RAM. As indicated in each NIM’s support matrix, you can use other NVIDIA GPUs, Private AI Foundation with NVIDIA supports such as A100, and L40S.
In the following paragraphs, we provide pointers for the Getting Started documentation for each NIM. Make sure you follow those documents to understand how to authenticate at NVIDIA’s NGC services so you can pull the NIM containers. Once you have authenticated and generated your NGC_API_KEY, please plug it into the second line of each of the scripts launching NIMs.
Setting up NVIDIA NIMs for the summarization service.
- NVIDIA NIM for Text Embedding. This NIM’s documentation includes a Getting Started section that provides all the steps required to get access to the NIM container and how to launch it. We are reproducing the launch script next, but you need to consider the following:
- Adjust the port number assigned to the embedding service. By default, this script makes the service available at port 8000, but you may change it to your liking.
- The summarization service uses the NV-EmbedQA-E5-v5 model, which requires one of the GPUs indicated in the NV-EmbedQA-E5-v5’s supported hardware document. This model will consume around 2989 MiB of GPU RAM.
- The script runs the container on the 1st GPU device (–gpus ‘”device=0″‘), but you can select another device number.
- Notice the NV-EmbedQA-E5-v5 model supports a maximum token count of 512.
You must login to nvcr.io using Docker before running any of the NIM launch scripts.
# Docker login to nvcr.io
docker login nvcr.io -u \$oauthtoken -p ${NGC_API_KEY}
Where the environment variable NGC_API_KEY must be properly set to your NGC key.
Embeddings NIM launcher script
# Choose a container name for book-keeping
export NGC_API_KEY="YOUR KEY"
export NIM_MODEL_NAME=nvidia/nv-embedqa-e5-v5
export CONTAINER_NAME=$(basename $NIM_MODEL_NAME)
# Choose a NIM Image from NGC
export IMG_NAME="nvcr.io/nim/$NIM_MODEL_NAME:1.0.0"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the NIM embedder on port 8000 and on the 2nd GPU
docker run -it –rm –name=$CONTAINER_NAME \
–runtime=nvidia \
–gpus '"device=0"' \
–shm-size=16GB \
-e NGC_API_KEY \
–detach \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8000:8000 \
$IMG_NAME
You can verify the embedder service is working correctly using the following script.
Embeddings NIM service verification script
curl -X "POST" \
"http://localhost:8000/v1/embeddings" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"input": ["Hello world"],
"model": "nvidia/nv-embedqa-e5-v5",
"input_type": "query"
}'
You should get a response like this:
{"object":"list","data":[{"index":0,"embedding":[-0.0003058910369873047, …, -0.00812530517578125],"object":"embedding"}],
"model":"nvidia/nv-embedqa-e5-v5","usage":{"prompt_tokens":6,"total_tokens":6}
- NVIDIA Text Reranking NIM. This NIM’s documentation includes a Getting Started section with all the steps required to pull and launch the NIM containers. There are a few things to consider before launching the service:
- The script makes the service available at port 8010, but you can change it to suit your needs.
- We use the nv-rerankqa-mistral-4b-v3 model, which requires one of the GPUs indicated in the supported hardware section of its documentation. The model will consume around 11487 MiB of GPU RAM.
- The script runs the container on the 2nd GPU device by default (–gpus ‘”device=1″‘), but you can select another number.
- Notice the nv-rerankqa-mistral-4b-v3 model supports a maximum token count of 512.
Reranker NIM launcher script
# Choose a container name for bookkeeping
export NGC_API_KEY="YOUR KEY"
export NIM_MODEL_NAME=nvidia/nv-rerankqa-mistral-4b-v3
export CONTAINER_NAME=$(basename $NIM_MODEL_NAME)
# Choose a NIM Image from NGC
export IMG_NAME="nvcr.io/nim/$NIM_MODEL_NAME:1.0.0"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the NIM Re-ranker service on port 8010 and on the 3rd GPU
docker run -it –rm –name=$CONTAINER_NAME \
–runtime=nvidia \
–gpus '"device=1"' \
–shm-size=16GB \
–detach \
-e NGC_API_KEY \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8010:8000 \
$IMG_NAME
You can verify the reranking service is working properly using the following script.
Reranker NIM service verification script
curl -X "POST" \
"http://localhost:8010/v1/ranking" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "nvidia/nv-rerankqa-mistral-4b-v3",
"query": {"text": "which way should i go?"},
"passages": [
{"text": "two roads diverged in a yellow wood, and sorry i could not travel both and be one traveler, long i stood and looked down one as far as i could to where it bent in the undergrowth;"},
{"text": "then took the other, as just as fair, and having perhaps the better claim because it was grassy and wanted wear, though as for that the passing there had worn them really about the same,"},
{"text": "and both that morning equally lay in leaves no step had trodden black. oh, i marked the first for another day! yet knowing how way leads on to way i doubted if i should ever come back."},
{"text": "i shall be telling this with a sigh somewhere ages and ages hense: two roads diverged in a wood, and i, i took the one less traveled by, and that has made all the difference."}
],
"truncate": "END"
}'
You should get the following response:
{"rankings":[{"index":0,"logit":0.7646484375},{"index":3,"logit":-1.1044921875},
{"index":2,"logit":-2.71875},{"index":1,"logit":-5.09765625}]}
- NVIDIA NIM for Large Language Models. This NIM’s documentation includes a Getting Started section with all the steps required to pull and launch the LLM NIM containers. There are a few things to consider:
- The following script launches the Mixtral-8x7b-instruct-v01 LLM service as an OpenAI-like API service available at port 8020, which you can modify.
- This model must run on multiple GPUs, as the supported hardware section indicates.
- The script runs the container on four H100XM-40C partitions (‘”device=2,3,4,5″‘) with 40GB of GPU RAM each (approximately 35105 MiB will be consumed per partition).
LLM NIM service launch script
# Choose a container name for bookkeeping
export NGC_API_KEY="YOUR KEY"
export CONTAINER_NAME="Mixtral-8x7b-instruct-v01"
# The container name from the previous ngc registgry image list command
Repository="nim/mistralai/mixtral-8x7b-instruct-v01"
Latest_Tag="1.2.1"
# Choose a LLM NIM Image from NGC
export IMG_NAME="nvcr.io/${Repository}:${Latest_Tag}"
# Choose a path on your system to cache the downloaded models
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
# Start the LLM NIM on port 8020 and the 5th GPU
docker run -it –rm –name=$CONTAINER_NAME \
–runtime=nvidia \
–gpus '"device=2,3,4,5"' \
–shm-size=16GB \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_MODEL_PROFILE="vllm-bf16-tp4" \
-v "$LOCAL_NIM_CACHE:/opt/nim/.cache" \
-u $(id -u) \
-p 8020:8000 \
$IMG_NAME
You can verify the LLM generation service is working properly using the following script.
LLM NIM service verification script
curl -X 'POST' \
'http://0.0.0.0:8020/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "mistralai/mixtral-8x7b-instruct-v0.1",
"messages": [
{
"role":"user",
"content":"Hello! How are you?"
},
{
"role":"assistant",
"content":"Hi! I am quite well, how can I help you today?"
},
{
"role":"user",
"content":"Can you write me a song?"
}
],
"top_p": 1,
"n": 1,
"max_tokens": 15,
"stream": false,
"frequency_penalty": 1.0,
"stop": ["hello"]
}'
You should see the following generated sequence:
{"id":"chat-15d58c669078442fa3e33bbf06bf826b","object":"chat.completion","created":1728425555,
"model":"mistralai/mixtral-8x7b-instruct-v0.1",
"choices": [{"index":0,"message":{"role":"assistant","content":" Of course! Here's a little song I came up with:\n"},
"logprobs":null,"finish_reason":"length","stop_reason":null}],
"usage":{"prompt_tokens":45,"total_tokens":60,"completion_tokens":15}}
3. Deploying an AI GPU-enabled Tanzu Kubernetes Cluster from Catalog with VCF Automation.
It is time to request an AI Kubernetes cluster from VMware Private AI Foundation with NVIDIA’s automation catalog. This AI Kubernetes cluster will run the two services part of Summarize-and-Chat, Summarizer-client and the Summarizer-server. Log to your VMware Automation Service Broker and request the AI Kubernetes Cluster from the catalog:

Fill out your deployment name and the required topology (number of Control Plane and Worker Nodes). Then, enter your NGC API Key, which has access to NVIDIA AI Enterprise, and click “Submit.”
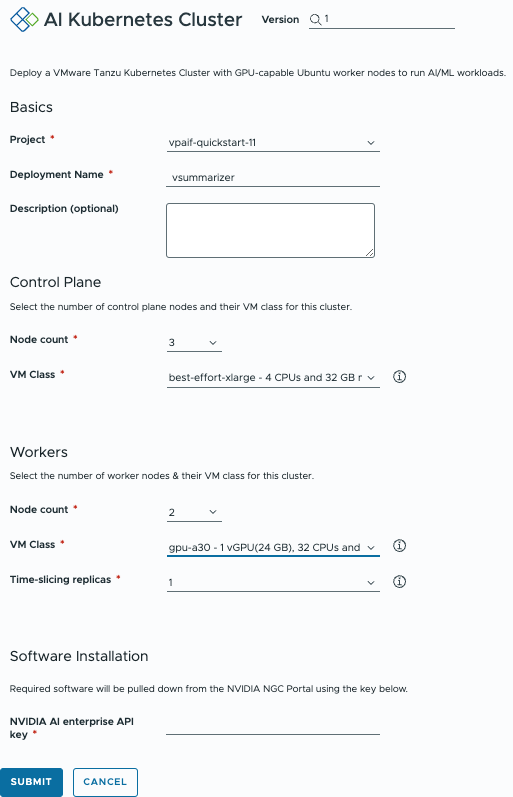
Once deployed, you will receive details about your newly created GPU-enabled AI Kubernetes cluster so you can connect to it and start deploying workloads.
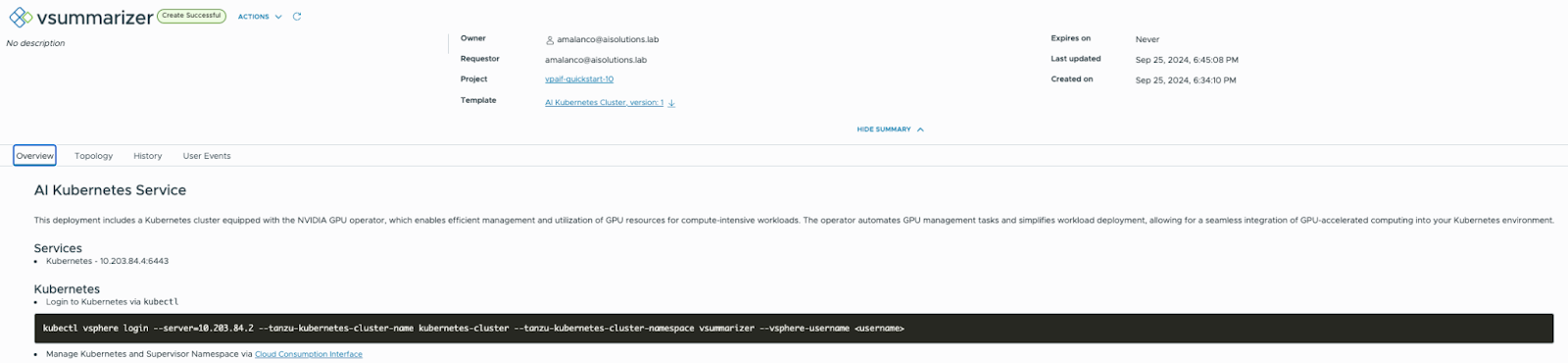
You can confirm the Tanzu Kubernetes Cluster is GPU enabled and ready to start accepting GPU-enabled workloads by login into the cluster with the Kubectl with the login command and credentials listed as part of your successful deployment. Once logged in, execute the kubectl get pods -n gpu-operator command:
kubectl get pods -n gpu-operator
# You should see something similar to the following:
# NAME READY STATUS RESTARTS AGE
# gpu-feature-discovery-kzr86 1/1 Running 0 14d
# gpu-feature-discovery-vg79p 1/1 Running 0 14d
# gpu-operator-5b949499d-sdczl 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-gc-6cb4486d8f-prjrs 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-master-5bcf8948d8-tptht 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-worker-8hqxs 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-worker-dr5bk 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-worker-f26d6 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-worker-prszz 1/1 Running 0 14d
# gpu-operator-app-node-feature-discovery-worker-x7nkw 1/1 Running 0 14d
# nvidia-container-toolkit-daemonset-7n8pm 1/1 Running 0 14d
# nvdia-container-toolkit-daemonset-cj7jw 1/1 Running 0 14d
# nvidia-cuda-validator-pxhx5 0/1 Completed 0 14d
# nvidia-cuda-validator-thjlz 0/1 Completed 0 14d
# nvidia-dcgm-exporter-gv4pj 1/1 Running 0 14d
# nvidia-dcgm-exporter-hfkcd 1/1 Running 0 14d
# nvidia-device-plugin-daemonset-dg2dd 1/1 Running 0 14d
# nvidia-device-plugin-daemonset-zsjhw 1/1 Running 0 14d
# nvidia-driver-daemonset-7z2qq 1/1 Running 0 14d
# nvidia-driver-daemonset-hz8sx 1/1 Running 0 14d
# nvidia-driver-job-f2dnj 0/1 Completed 0 14d
# nvidia-operator-validator-5t6t6 1/1 Running 0 14d
# nvidia-operator-validator-xdsd2 1/1 Running 0 14d
We will now deploy a 3-node Postgres Database with Data Services Manager. For a detailed step-by-step process, refer to VMware Data Services Manager’s Documentation.
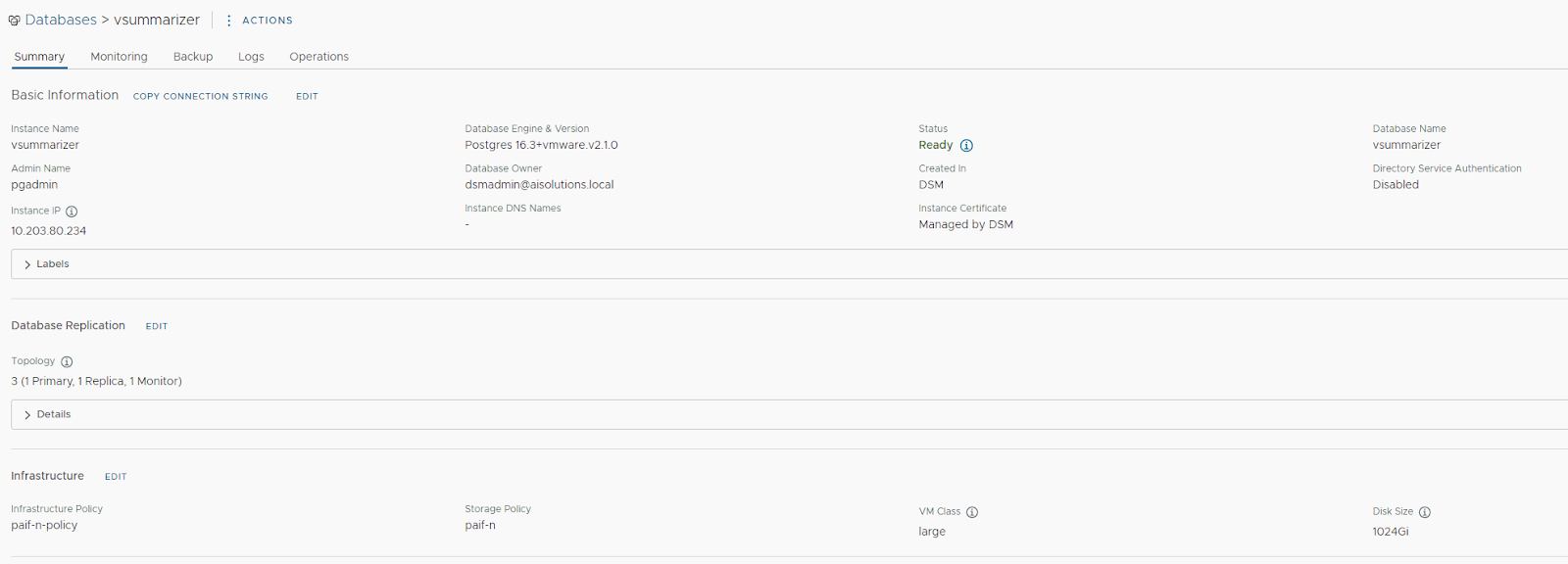
This Postgres database will store embeddings and chat histories, copy the connection string for the database, and connect to it with psql. Once connected, create the vector extension as shown below:
psql -h 10.203.80.234 -p 5432 -d vsummarizer -U pgadmin
# Password for user pgadmin:
# psql (16.4, server 16.3 (VMware Postgres 16.3.0))
# SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384,
# compression: off)
# Type "help" for help.
# vsummarizer=# CREATE EXTENSION vector;
Enabling ReadWriteMany Persistent Volumes with VMware vSAN File Services
VMware vSphere’s IaaS control plane provides support for persistent volumes in ReadWriteMany mode (RWX). This capability allows a single persistent volume to be mounted at the same time by multiple pods or applications operating within a TKG cluster. For ReadWriteMany persistent volumes, the vSphere IaaS control plane utilizes CNS file volumes that are supported by vSAN file shares for more information about vSAN File Services and how to configure it refer to vSAN documentation page.
This section assumes that vSAN File Service within your vSAN environment has been already enabled and will only cover how to enable file volume support on your Supervisor.
To to enable ReadWriteMany persistent volumes, perform the following actions:
- Log into VMware vCenter where the cluster with the IaaS Control Plane service is registered, and navigate to “Workload Management”

- Click on your Supervisor cluster and navigate to the “Configure” tab, then click on “Storage” and expand the File Volume Settings, toggle the “Activate file volume support”, which will enable you to start requesting PVCs backed by vSAN File Services:
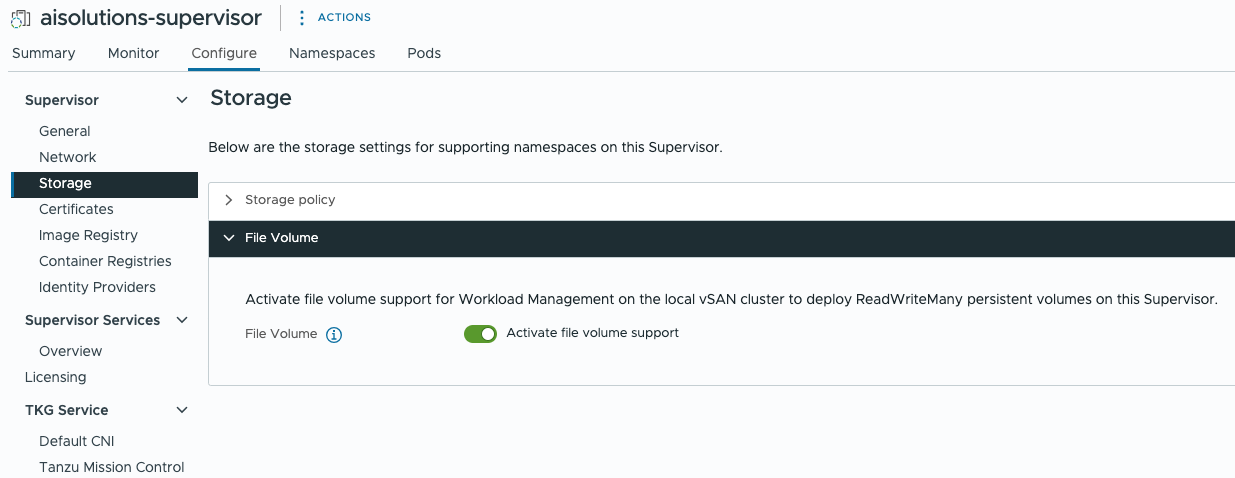
At this point we have all the required settings and configurations to start deploying the Summarize-and-Chat service components on our Tanzu Kubernetes Cluster.
Setting up Summarize-and-Chat
At this stage, we are ready to start configuring the Tanzu Kubernetes Cluster, we will start by deploying NGINX as in ingress controller on our Kubernetes cluster, NGNIX will be used by two services that will be created on a later step, you can use other ingress controllers as well.
Summarize-and-Chat requires TLS, NGINX will need to expose the Kubernetes services with a valid TLS certificate, self-signed certificates can be used for testing purposes and can be created with tools like openssl. Refer to NGINX documentation for more details on how to enable TLS with NGINX.
Start by creating a namespace for the NGNIX ingress controller:
kubectl create ns ingress-nginx
Now it is time to install NGINX on the newly created namespace, helm is used for this example:
helm install nginx ingress-nginx/ingress-nginx \
–namespace nginx \
–set controller.service.type=LoadBalancer \
–set controller.ingressClassResource.name=nginx \
–set controller.ingressClassResource.controllerValue="k8s.io/nginx"
A successful of the helm chart would produce a similar output to the following:
|
1 2 3 4 5 6 7 |
NAME: nginx LAST DEPLOYED: Wed Oct 9 17:02:38 2024 NAMESPACE: nginx STATUS: deployed REVISION: 1 TEST SUITE: None NOTES: |
The nginx-ingress controller has been installed. It may take a few minutes for the load balancer IP to be available.
You can watch the service status by running
kubectl get service \
–namespace ingress-test nginx-ingress-test-ingress-nginx-controller \
–output wide \
–watch
Now let’s verify that the pod for NGINX is up and running
kubectl get pods -n nginx
# You should see something like the following:
# NAME READY STATUS RESTARTS AGE
# nginx-ingress-nginx-controller-6dbd85479-dw2zk 1/1 Running 0 17h
As a last step we can confirm that the ingress controller class is available to be consumed by our deployments with the following command:
kubectl get ingressclass -n nginx
# You should see something like the following:
# NAME CONTROLLER PARAMETERS AGE
# nginx k8s.io/nginx <none> 17h
Now it is time to create a PersistentVolumeClaim that will be used by the pods that are part of the Summarize-and-Chat deployment. As mentioned, we will use vSAN File Services to provide the ReadWriteMany volumes. The following .yaml structure allows you to set the parameters required by PersistentVolumeClaim:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: vsummarizerpvc
namespace: vsummarizer
labels:
app: rwx
spec:
accessModes:
– ReadWriteMany
resources:
requests:
storage: 1024Gi
storageClassName: paif-n
volumeMode: Filesystem
Make the required modifications, such as storageClassName, namespace, etc., and save the file using the .yaml extension. Our example will be vsanfspvc.yaml.
Now it is time to apply that .yaml file with kubectl and confirm that the pv and pvc are created successfully:
# Create the namespace where Summarize-and-Chat will be deployed
kubectl create ns -n vsummarizer
# Apply the .yaml manifest
kubectl apply -f vsanfspvc.yaml
# This command will list the persitentvolumes on a given namespace
kubectl get pv -n vsummarizer
# You'll see something like this:
# NAME CAPACITY ACCESS MODES
# pvc-c993076d-6a6b-484f-9c0b-1822a321a1bf 1Ti RWX
# RECLAIM POLICY STATUS CLAIM STORAGECLASS
# Delete Bound vsummarizer/vsummarizerpvc paif-n
# This command will list the persitentvolumesclaims on a given namespace
kubectl get pvc -n vsummarizer
We can also confirm the creation of a RWX volume by navigating to the vSphere cluster where vSAN File Services is enabled then Configure> vSAN> File Shares:
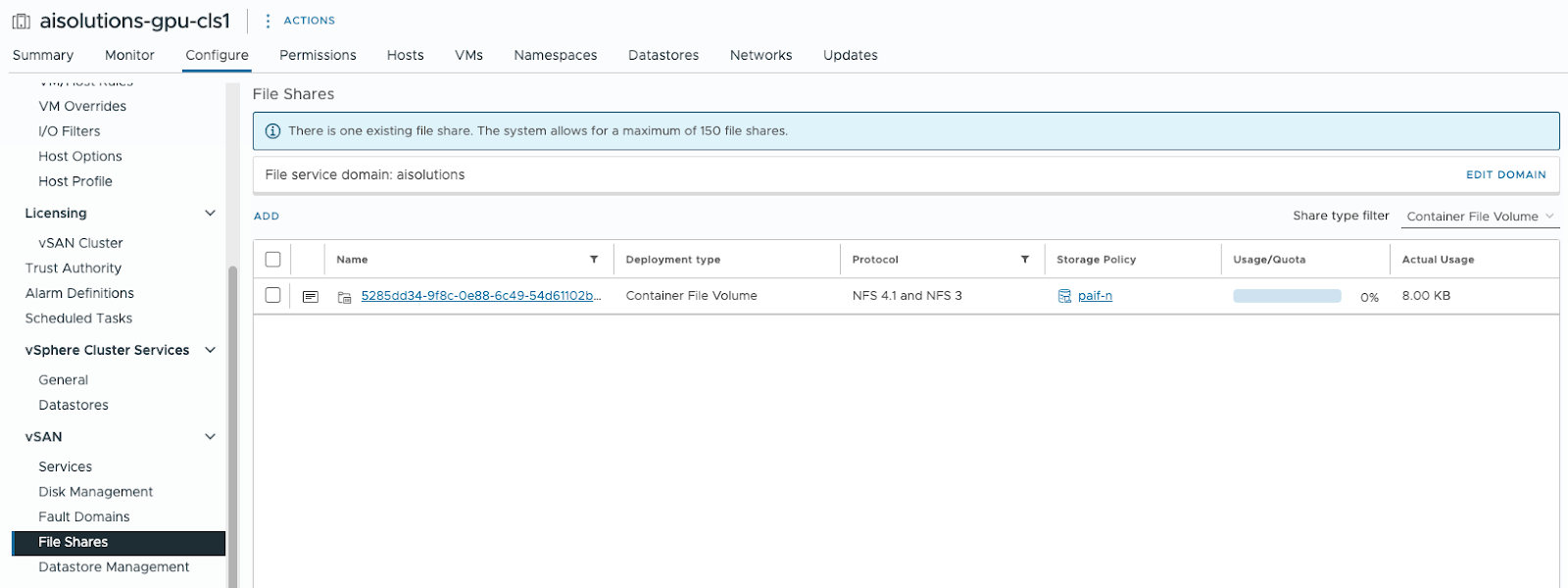
Summarize-and-Chat Kubernetes Deployment
At this point, we have already covered all the different infrastructure and Kubernetes requirements for deploying Summarize-and-Chat. The first step is to clone the GitHub repository.
git clone https://github.com/vmware/summarize-and-chat
# Cloning into 'summarize-and-chat'…
# remote: Enumerating objects: 447, done.
# remote: Counting objects: 100% (447/447), done.
# remote: Compressing objects: 100% (303/303), done.
# remote: Total 447 (delta 182), reused 399 (delta 137), pack-reused 0 (from 0)
# Receiving objects: 100% (447/447), 1.25 MiB | 3.70 MiB/s, done.
# Resolving deltas: 100% (182/182), done.
We can explore the structure and contents once the repository has been cloned locally to your client system:
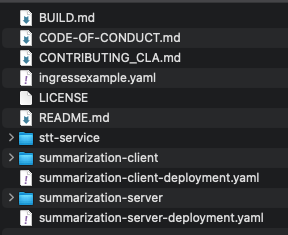
For this exercise, we will use the two .yaml files (summarization-client-deployment.yaml and summarization-server-deployment.yaml) that are located at the root of the cloned repository; these files will create the Deployments and Services associated with the Client and Server components of Summarize-and-Chat, you can also notice three folders that contain the required files including the docker-compose file to create your docker images. Before we build the images, we need to set up the necessary configuration from the summarization-server/src/config/config.yaml file. This includes setting up the Okta authentication, LLM configuration, database, etc.
As an example, we set up the embedding model using the embedding service that we have started in the DLVM at port 8000:
embedder:
API_BASE: "http://localhost:8000"
API_KEY: NONE
MODEL: "nvidia/nv-embedqa-e5-v5"
VECTOR_DIM: 1024
BATCH_SIZE: 16
For this blog post, we assume you already created your image and it is available on your registry of choice.
Let’s start with the deployment of the Server component. Modify the namespace PersistentVolumeClaim to the one you created before and optionally change the port exposed by the associated service to suit your needs. Once finished, apply the .yaml file with kubectl:
kubectl apply -f summarization-server-deployment.yaml
We will now verify that the Deployment, the pods, and the service were correctly created and working as expected. Let’s start by listing the pod(s) on the namespace. The pod(s) should be on a running status:
kubectl get pods -n vsummarizer
# NAME READY STATUS RESTARTS AGE
# summarizer-server-645dcc5d8c-d5d5m 1/1 Running 0 12d
Now, let’s confirm that the service for the Server component was created with the following command:
kubectl get services -n vsummarizer
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# summarizer-server-svc ClusterIP 10.104.16.188 <none> 5000/TCP 12d
This confirms that the service is ready. We will now need to create an ingress to provide external access to this service; you can find a template called ingressexample.yaml. Customize the ingress with your specific namespace, ingressclass, FQDN, secret, etc. Once the ingress configuration file is ready, apply it with kubectl:
kubectl apply -f ingressexample.yaml
You can confirm the ingress was created with the following command:
kubectl get ingress -n vsummarizer
# NAME CLASS
# summarizer-server-ingress nginx-second
# HOSTS ADDRESS PORTS AGE
# vsummarizerbackend.h2o-358-21704.h2o.vmware.com 10.203.84.7 80, 443 8d
As you can see, the ingress was created for the server component service, now let’s confirm that the ingress has active backends to serve requests:
kubectl describe ingress summarizer-server-ingress -n vsummarizer
# Name: summarizer-server-ingress
# Labels: <none>
# Namespace: vsummarizer
# Address: 10.203.84.7
# Ingress Class: nginx-second
# Default backend: <default>
# TLS:
# ingress-server-cert terminates
# vsummarizerbackend.h2o-358-21704.h2o.vmware.com
# Rules:
# Host Path Backends
# —- —- ——–
# vsummarizerbackend.h2o-358-21704.h2o.vmware.com
# summarizer-server-svc:5000 (192.168.147.23:5000)
# Annotations: <none>
# Events: <none>
Repeat the same process now with the summarization-client-deployment.yaml to deploy the client component of Summarize-and-Chat.
Summarizer-server configuration
We will first set up the Summarizer-server configuration in the summarization-server/src/config/config.yaml file.
Authentication configuration
Summarize-and-Chat supports Okta authentication and basic authentication. If your organization is using Okta authentication, you can create an SPA application in Okta and enable the single-sign-on for the Summarize-and-Chat application by setting the Okta config as follows:
okta:
OKTA_AUTH_URL: "Okta auth URL"
OKTA_CLIENT_ID: "Okta client ID"
OKTA_ENDPOINTS: [ 'admin' ]
Model configuration
In the NIM section, we have started several LLM services for embedding, reranking, etc. Now, let’s set them up in the config.yaml file.
Set up summarization models.
summarization_models:
MAX_COMPLETION: 1024
BATCH_SIZE: 4
MODELS: models.json
The models.json file contains the models available for summarization tasks. For example:
{
"models":
[
{
"api_base": "http://host:8030",
"api_key": "NONE",
"name": "meta-llama/Meta-Llama-3-8B-Instruct",
"display_name": "LLAMA 3 – 8B",
"max_token": 6500
},
{
"api_base": "http://host:8020",
"api_key": "NONE",
"name": "mistralai/Mixtral-8x7B-Instruct-v0.1",
"display_name": "Mixtral – 8x7B",
"max_token": 30000
}
]
}
Set up the QA model
qa_model:
API_BASE: "http://host:8020"
API_KEY: NONE
MODEL: "mistralai/mixtral-8x7b-instruct-v0.1"
MAX_TOKEN: 1024
MAX_COMPLETION: 700
SIMIL_TOP_K: 10 # Retrieve TOP_K most similar docs from the PGVector store
CHUNK_SIZE: 512
CHUNK_OVERLAP: 20
NUM_QUERIES: 3
Set up the embedding model
embedder:
API_BASE: "http://host:8000"
API_KEY: NONE
MODEL: "nvidia/nv-embedqa-e5-v5"
VECTOR_DIM: 1024
BATCH_SIZE: 16
Set up reranker model
reranker:
API_BASE: "http://host:8010"
API_KEY: NONE
MODEL: "nvidia/nv-rerankqa-mistral-4b-v3"
RERANK_TOP_N: 5 # Rerank and pick the 5 most similar docs
Database configuration
database:
PG_HOST: "Database host"
PG_PORT: 5432
PG_USER: DB_USER
PG_PASSWD: DB_PASSWORD
PG_DATABASE: "your database name"
PG_TABLE: "pgvector embedding table"
PG_VECTOR_DIM: 1024 # match embedding model dimension
Server configuration
server:
HOST: "0.0.0.0"
PORT: 5000
NUM_WORKERS: 4
PDF_READER: pypdf # default PDF parser
FILE_PATH: "../data"
RELOAD: True
auth: okta # basic – if use basic auth
Summarizer-client configuration
Now, we must set up the client configuration in the environment.ts file.
export const environment: Env = {
production: false,
Title: "Summarize-and-Chat" ,
serviceUrl: "your-summarizer-server-ingress-host",
ssoIssuer: "https://your-org.okta.com/oauth2/default",
ssoClientId: 'your-okta-client-id',
redirectUrl:'your-summarizer-client-ingress-host/login/'
};
Using Summarize-and-Chat
Please read our blog “Introducing Summarize-and-Chat service for VMware Private AI“ for the key features of the Summarize-and-Chat application and dive into the details of how you can use Summarize-and-Chat to summarize your document and chat with it end-to-end.
Next Steps
Visit the VMware Private AI Foundation with NVIDIA webpage to learn more about this platform.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



