

In VMware Cloud Foundation (VCF) 5.2 there is a new console experience that adds diagnostics capabilities into VMware Cloud Foundation Operations (VMware Aria Operations). VMware Cloud Foundation Operations is included with VCF and VMware vSphere Foundation . The new features include “Overall Findings” and “Security Advisories”. Additionally, sections such as “vCenter Servers”, “ESXi Hosts”, “Workload Provisioning”, and “vSAN Clusters” that were previously available in VMware Cloud Foundation Operations are now included for improved visibility. There is also enhanced integration into VMware Aria Operations for logs, providing more information on “vMotions” and “Snapshots”. To enable this feature, you will need to connect Operations with Operations for Logs and at least one vCenter. By adding more VMware vSphere Foundation and VCF components, additional data sets will become available. Let’s examine each section more closely.
Overall Findings
In the new VMware Cloud Foundation Operations, we have combined these diagnostic capabilities (from Skyline Health Diagnostics, Skyline Advisor, and VMware Aria Operations for Logs) into a unified experience delivered within the new console. With Skyline, security and operational recommendations based on version can be promoted. VMware Cloud Foundation Operations and VMware Aria Operations for Logs are now tethered to the same endpoints, facilitating the appearance of new diagnostic findings in the console, thereby reducing the need for supplementary software deployment (reduce Skyline Advisor collector and Skyline Health Diagnostics VM). This seamless integration mitigates the duplication efforts alluded to earlier and streamlines the deployment and management of the environment. The upshot is a systematic approach to presenting diagnostic findings to customers.
Here are some common tasks:
- view all findings
- discern the total quantity
- categorize findings based on criticality (critical, immediate, and warnings)
- classify them according to type:
- Security Advisory
- Availability
- Pre-Upgrade Checks
- Operation Diagnostics
- Performance
- refine their view by applying filters based on:
- VCF Inventory
- VCF Components
- Finding Type
- Severity
- Capability
- vMotions
- Snapshots
- Workload Provisioning
- Workload Domain Providing
- DRS
- HA
To access the Diagnostics Console, select “Diagnostics” from the left-side navigation panel. In the Home -> Overview page, find links to “Appliances Health & Management”.
Figure 1. Home Overview dashboard
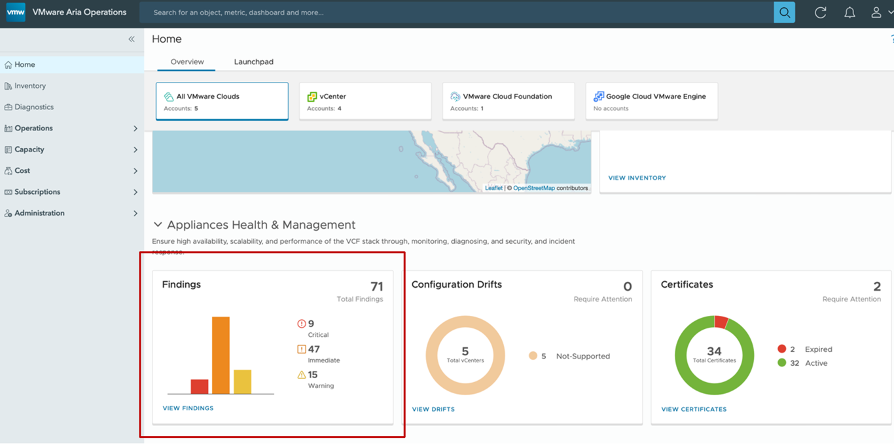
Figure 2. Diagnostics dashboard from left side menu
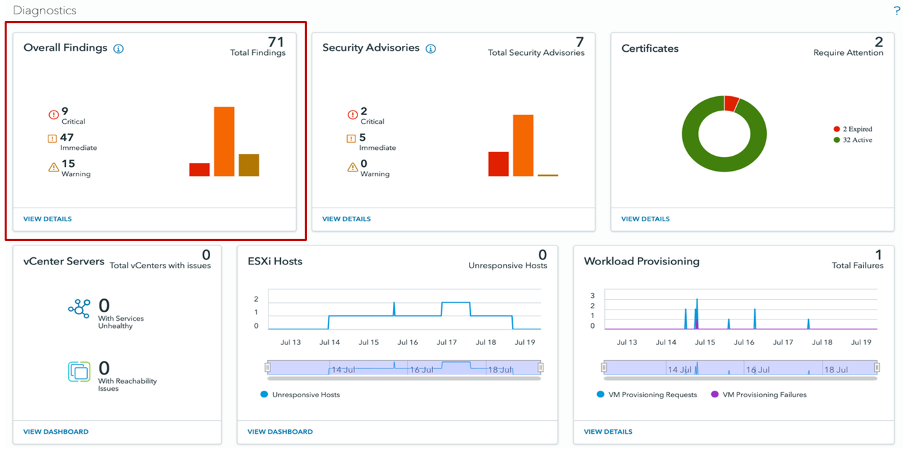
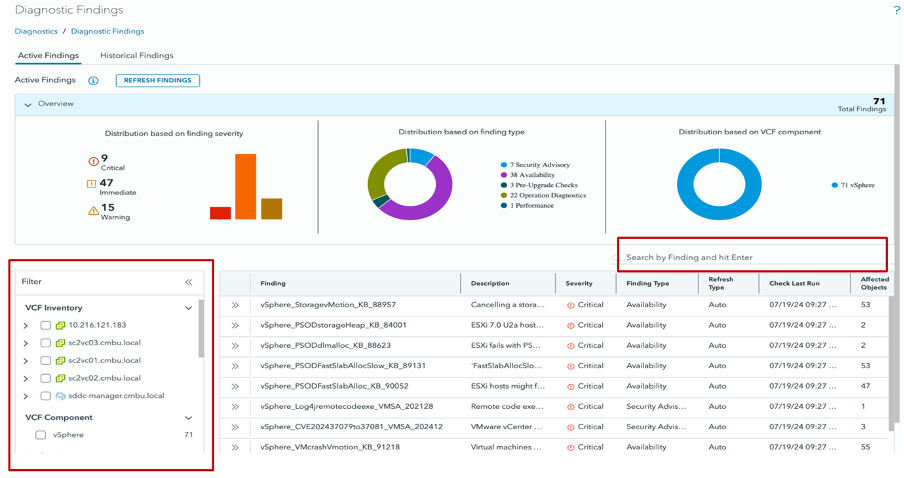
From the main ‘Overall Findings’ dashboard, you can quickly view all the findings. You can refine the number of findings by selecting components in the left pane. Furthermore, you can search for specific findings or use wildcards in the search bar located above the list of findings.
Figure 3. Filter and Search Option from the “Diagnostic Findings” dashboard
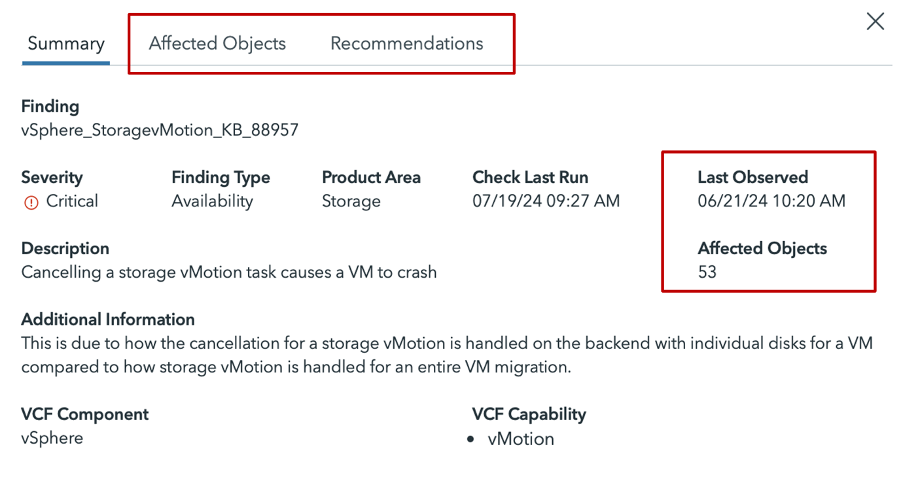
You can drill deeper to view specific details by selecting an individual finding, such as Last Observed, Affected Objects, and Recommendations.
Figure 4. View Last Objerved and Affected Objects
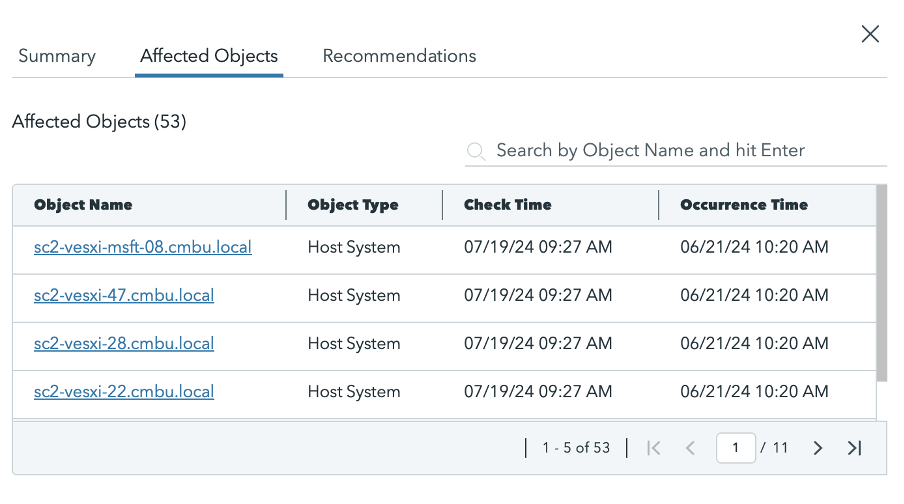
On the “Affected Objects” tab, you can locate the Object Name, the time it was first observed (Occurrence Time), and the time it was last checked (Check Time). The environment will be scanned every four hours, and the details on this tab will be refreshed accordingly. Make sure to remember the following information:
Figure 5. See “Affected Objects” details
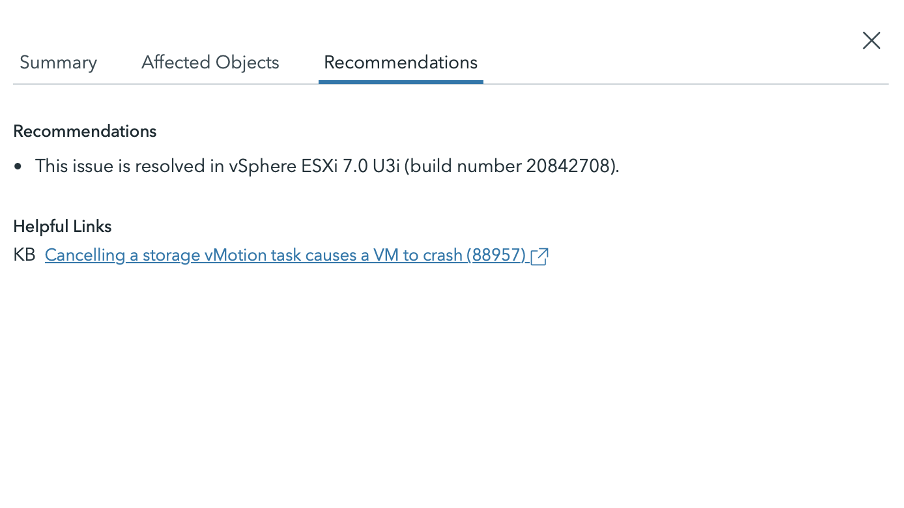
In the Recommendations, you can find the product version that resolved the concern, as well as the KB article that provides details about the problem, fix, and workaround.
Figure 6. Review “Recommendations” for “fixed versions” and “KBs”
Here are some common use cases:
- Review VMSA and CVE to identify the possible problems and upgrades for a particular set of servers
- Help plan for vCenter and ESX upgrades to solve several findings at a time
- Divide the list of findings based on region to divvy up the work based on regional staff members
Certificates Management
All certificates in the environment will be shown here. These certificates exist on all VMware applications to ensure application identity (to reduce “man in the middle” security attacks). Because each application can have up to three certificates, managing certificates are time consuming and complex. Based on expiration date and external certificate authority, managing the schedule of renewal and imports is problematic.
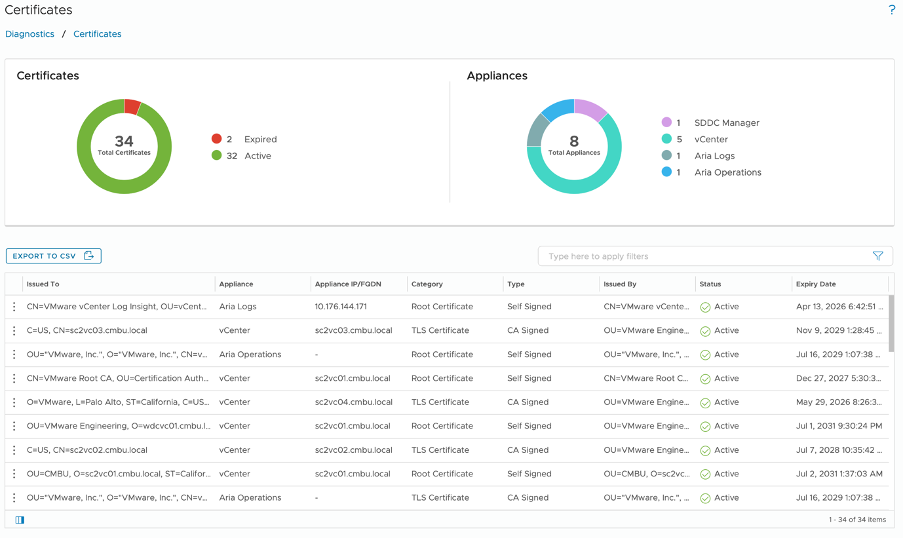
When you set up the Diagnostics console, it will also populate the Certificate Dashboard. You can easily see all the certificates for a specific server, whether they are self-signed or CA certificates, and if they are active. For active certificates, users can see the time remaining before the expiry date, which helps in starting the certificate renewal process before expiration to prevent potential outages.
Figure 7. Quick glance of Certificate Dashboard
Here are some common use cases:
- Check to see if any certificate are “inactive” and fix them right away
- Review Expiry date and fix the “self-sign” certificate right away
- Proactively prevent expired certificates
vCenter
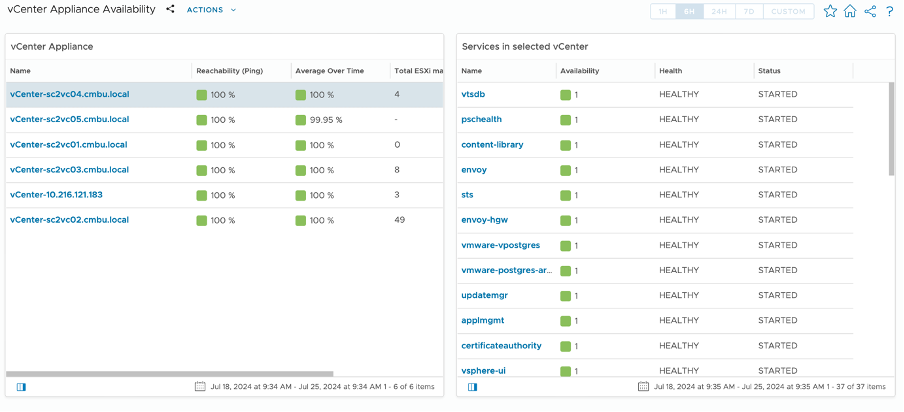
In the vCenter Diagnostic dashboard, you can easily view all the vCenters connected to VCF Operations. This combines all of the details from vCenter as well as the data from VCF Operations. You can quickly check the operational status of each vCenter. If a vCenter is down, you can identify the number of impacted ESX hosts and VMs. Additionally, you can see all the services running on a specific vCenter. Within seconds, you can identify any services that are not running, address the issues, and bring them back online. This process would have taken 30 minutes or more using traditional methods such as checking the vCenter through the server console (5480) and logs. When needed, you can select individual vCenters to investigate further.
Figure 8. vCenter Dashboard
Here are some common use cases:
- Check to see if any vCenter is reachable and identify the servers and VMs impacted
- Review services on each vCenter to ensure all are running fine
ESXi Hosts
The ESXi dashboard provides crucial diagnostic information about ESXi hosts. First, you can check for any “unresponsive ESXi” servers, as these are high-priority issues. Next, you can verify if any ESXi servers are in “Maintenance Mode” and determine whether they should remain there or exit Maintenance Mode. It’s also important to address ESXi servers that have been “disconnected” or “notResponding” for an extended period of time. When selecting each ESXi server, you can access the “parent cluster” settings, which can provide valuable insights into potential problems. Within seconds, you can identify issues and initiate the necessary remediation.
Figure 9. ESXi Dashboard
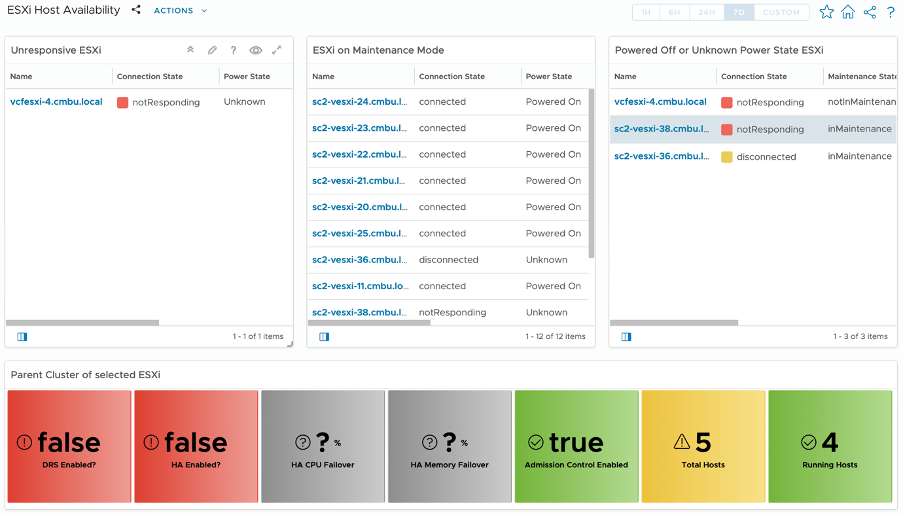
Here are some common use cases:
- Identify all “nonresponding” ESXi servers and restore them to proper state
- Review ESXi in “Maintenance Mode” to ensure they belong there. Take out of “Maintenance Mode” as soon as possible to best use the resources
- Identify the “Parent Cluster” of a particular ESXi and ensure all settings are correct.
Workload Provisioning
In the Workload Provisioning dashboard, you can view common workload tasks such as “Create New VM”, “Deploy OVF”, and “Clone VM”. you can quickly identify any failures. When reviewing the details, users can see information like “Time of Request”, “VM Name”, “Initiator”, “vCenter”, and “Cluster”. With this information, you can inspect the environment for potential issues, make necessary fixes, and notify initiators to re-perform their tasks.
Figure 10. Workload Provisioning Dashboard
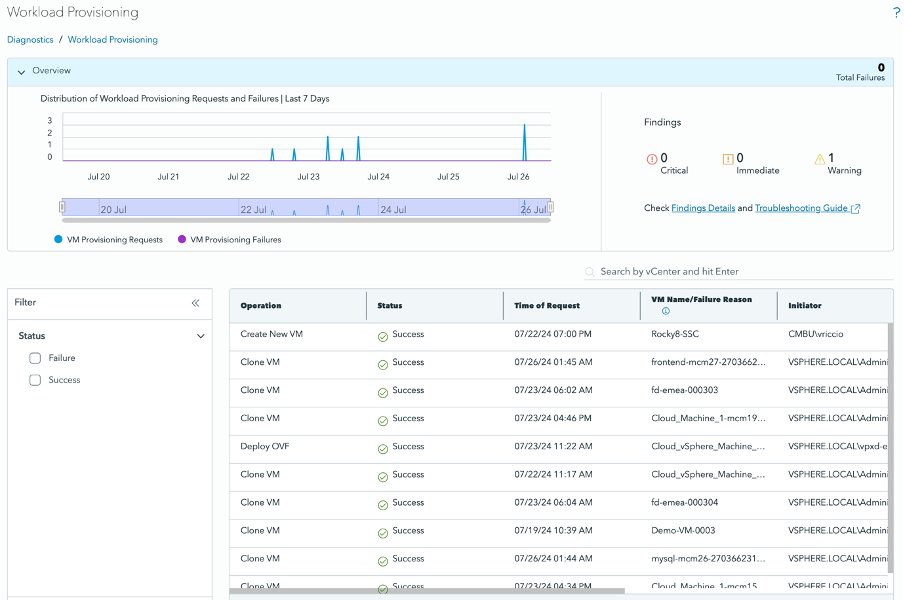
Here are some common use cases:
- Identify all Diagnostics findings based on Workload Provisioning
- Check to see any “failure” to find the root cause of the problem
- Review “initiators” to ensure all of the users are properly assigned
vMotions
vMotion has been available for quite some time. You can observe vMotion activities in the “recent tasks” list on vCenters. However, it was not possible to see all vMotion events from a single view. Now, you have the ability to do so. You can select each vCenter to view all occurrences of vMotion, identifying any failures as well as successful events. In case of a failure, you can view details such as the VM name, source, destination, and time, which can help identify and address the issue, preventing similar failures in the future. For those who uses HCX (which leverage vMotion), all HCX vmotion activities are captured as well.
Figure 11. vMotion Dashboard
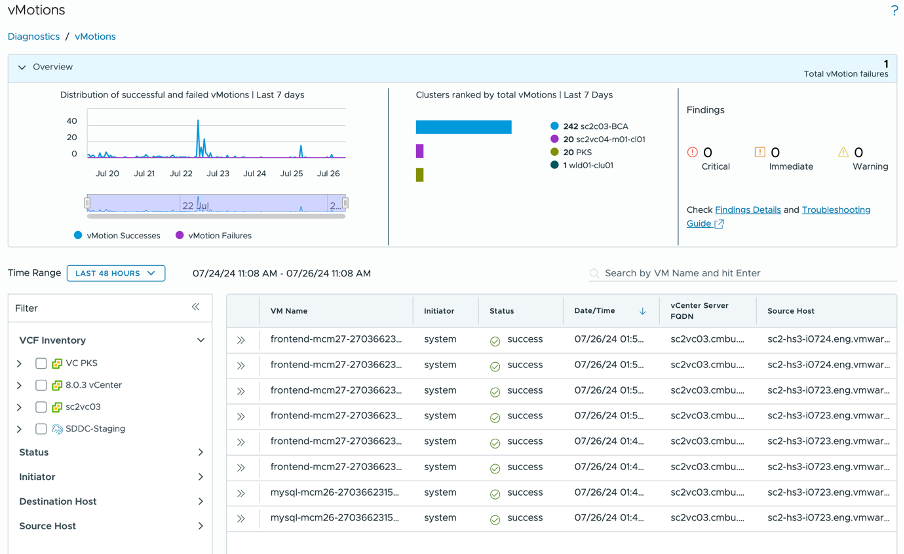
Here are some common use cases:
- Identify all Diagnostics findings based on vMotion
- Review all locations as well as each vCenter based on historical problems
- Check Soure and Destination host(s) to help identify problems
Snapshots
In the Diagnostic Console, you can view all the snapshots within the environment. You will be able to identify the most problematic virtual machines (VMs) with snapshot concerns, especially those requiring consolidation. Another important aspect is assessing the total number of snapshots for the top seven VMs. You have the option to filter between successful and failed snapshots. For each snapshot concern, you can review details such as the VMs, vCenter, datastore, and timestamp. This should provide enough information to determine whether the issue is specific to an individual VM or if it’s a systemic problem involving vCenter, ESXi, or the datastore.
Figure 12. Snapshot Dashboard
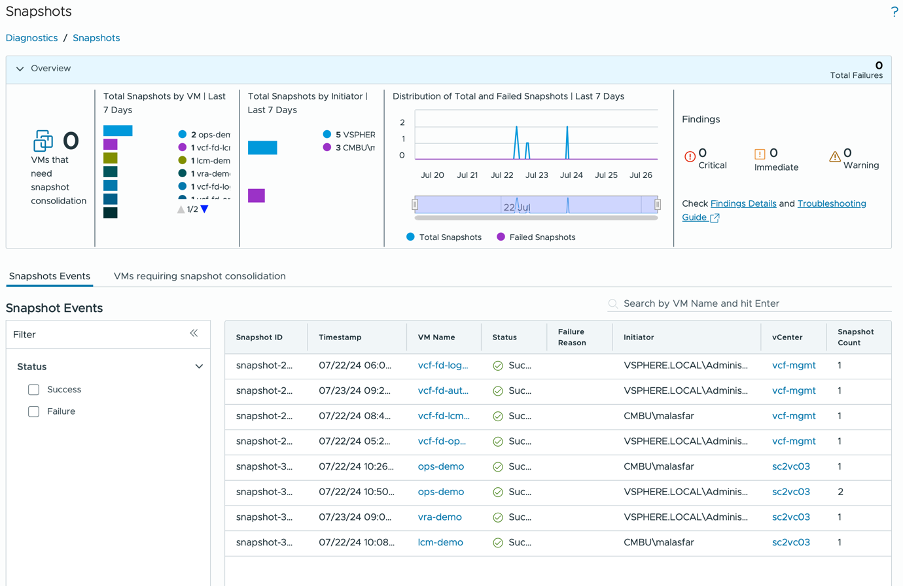
Here are some common use cases:
- Identify all Diagnostics findings based on Snapshots
- Review any “failure”
- Corollate any failure with ESXi problem, Backup schedule, or other failures (Network, Storage, etc)
vSAN Clusters
The vSAN Health section of the Diagnostics console gives an overview of the vSAN landscape. You can quickly filter the number of “Red,” “Orange,” and “Yellow” alerts. When selecting each cluster, details about the selected cluster’s properties will appear to help you ensure that all the desired settings are in place. Below, you can review the details of each alert, which will help them prioritize and fix issues to ensure the best performance and stability of the vSAN cluster.
Figure 13. vSAN Health Dashboard
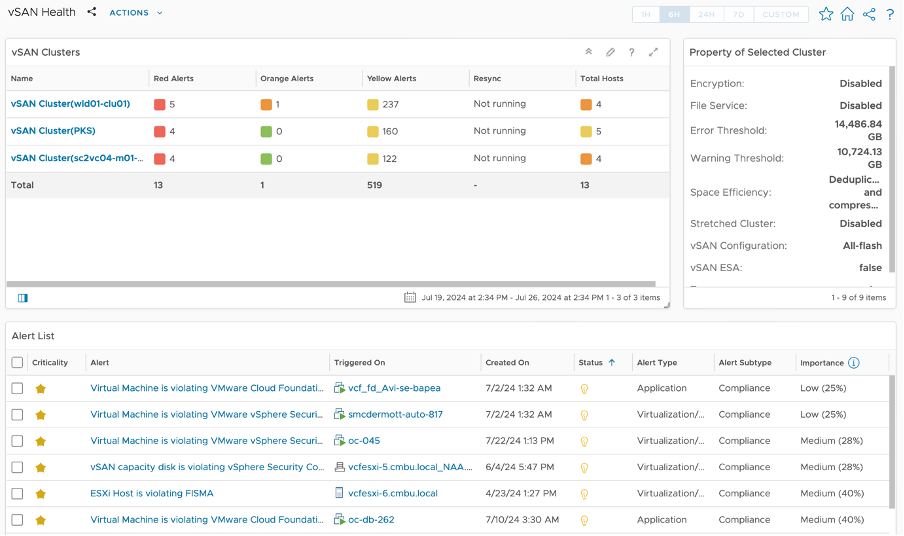
Here are some common use cases:
- Review all “Red”, “Orange”, and “Yellow” alerts
- Check all “Property of Selected Cluster” to proper settings
- Go through all findings individually to plan for upgrade to solve the problem
After exploring all the features in the Diagnostic Console (Findings, Certificates, vCenter, ESXi, Workload Provisioning, vMotion, Snapshots, and vSAN Clusters), you can find great value in the new dashboards. Some are new features recently added from other products, while others are details from existing dashboards that are combined in this console. The goal is to provide valuable insights with minimal deployment and configuration efforts. It will make use of existing Aria Operations and Operations for Logs instances, ultimately saving time for customers to resolve issues and reduce downtime and maintenance.”
Resources:
VMware Aria operations 8.18 Release Notes
What is Diagnostics for VMware Cloud Foundation
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




