

In this article, we explore the new features in the VMware Cloud Foundation (VCF) Add-on product “VMware Private AI Foundation with NVIDIA”. The set of AI tools and platforms within that VMware Cloud Foundation Add-on product are developed as part of an engineering collaboration between VMware and NVIDIA.
We describe the technical values that this new product brings to data scientists and to the devops people who serve them, with the following outline: –
- Providing an improved experience for the data scientist in provisioning and managing their AI platforms using VCF tools
- Deep learning VM images as a building block for these data science environments
- Using a Retrieval Augmented Generation (RAG) approach with NVIDIA’s microservices for Large Language Models (LLM)
- Managing and planning your GPU consumption from within the VCF platform
Let’s first take a look at the architecture outline for VMware Private AI Foundation with NVIDIA to see how the different layers are positioned within it with respect to each other. We will dig into many of these areas in this article and how they are used for implementing applications on VMware Private AI Foundation with NVIDIA. The key layers here are the list of openly available and permissibly-licensed LLMs on the top, the NVIDIA software in the green layer and the VMware Cloud Foundation Add-On layer in blue background and the VMware Cloud Foundation that constitutes the basis for all this work. This article is mainly about the the VMware by Broadcome layer containing the four main items, but it will make references to the other layers, too.

Improved Experience for the Data Scientist
Our objective in this section is to quickly deploy and optimize the development environment that data scientists want in a self-service way. We do this by automating many pieces of the infrastructure needed to support the models, libraries, tools, and UIs that data scientists like to use. This is done in a VCF tool called Aria Automation. What a data scientist sees, once some background work is done by the administrator or platform engineer, is a user interface with a set of tiles they can use to request a new environment. An example of this user interface is shown below.
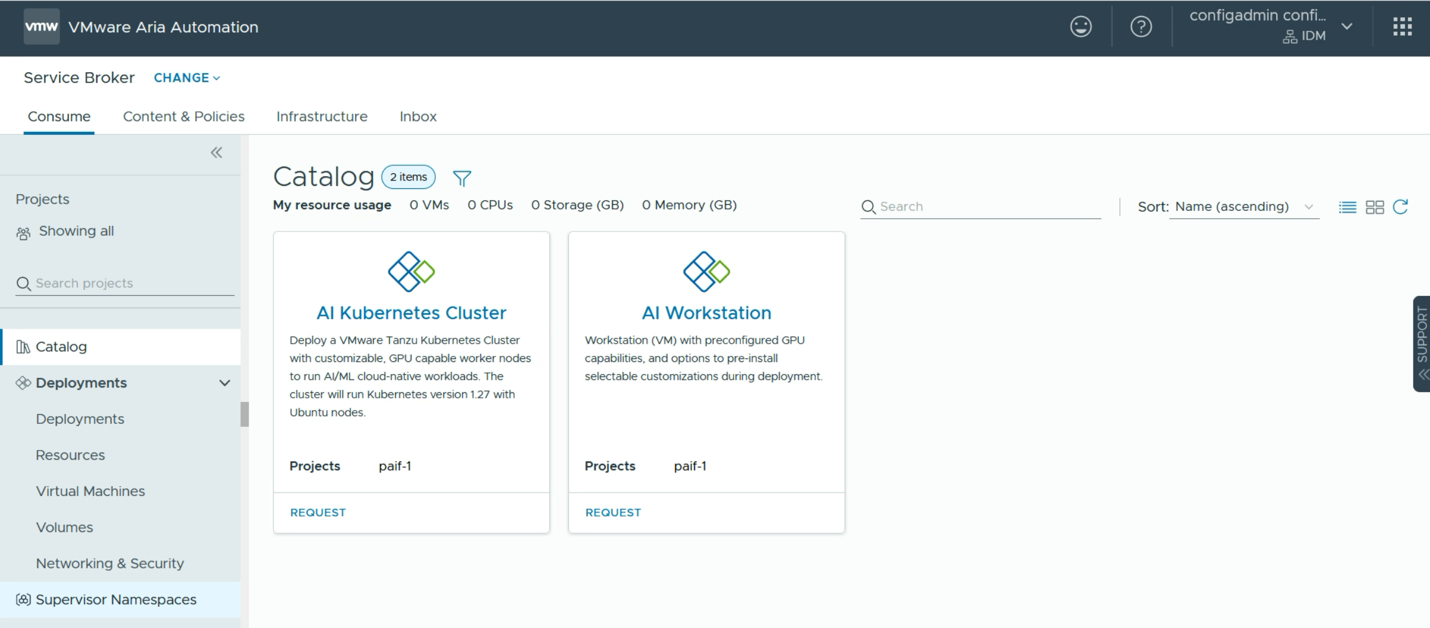
VMware Aria Automation is a key tool within the VMware Cloud Foundation suite. It provides a Service Broker function with customizable user “quickstart” features that show up as tiles or panels in the user interface. Examples of those quickstart tiles appear in the “AI Kubernetes Cluster” and “AI Workstation” examples above. Aria Automation allows you to custom build your own quickstart templates to suit your own data scientists’ needs. There are likely to be a number of these custom deployment templates available in your organization. There are tools for creating these in a graphical way within the Aria Automation environment.
A data scientist user would need some basic information about their desired GPU requirement (e.g. one, two or more full GPUs or a share in a physical GPU), along with their access details for the container repository that is held internally or externally to the enterprise, such as an NGC API key). With that, they can proceed to submit a request for one or more of these environments. We show that request step below.
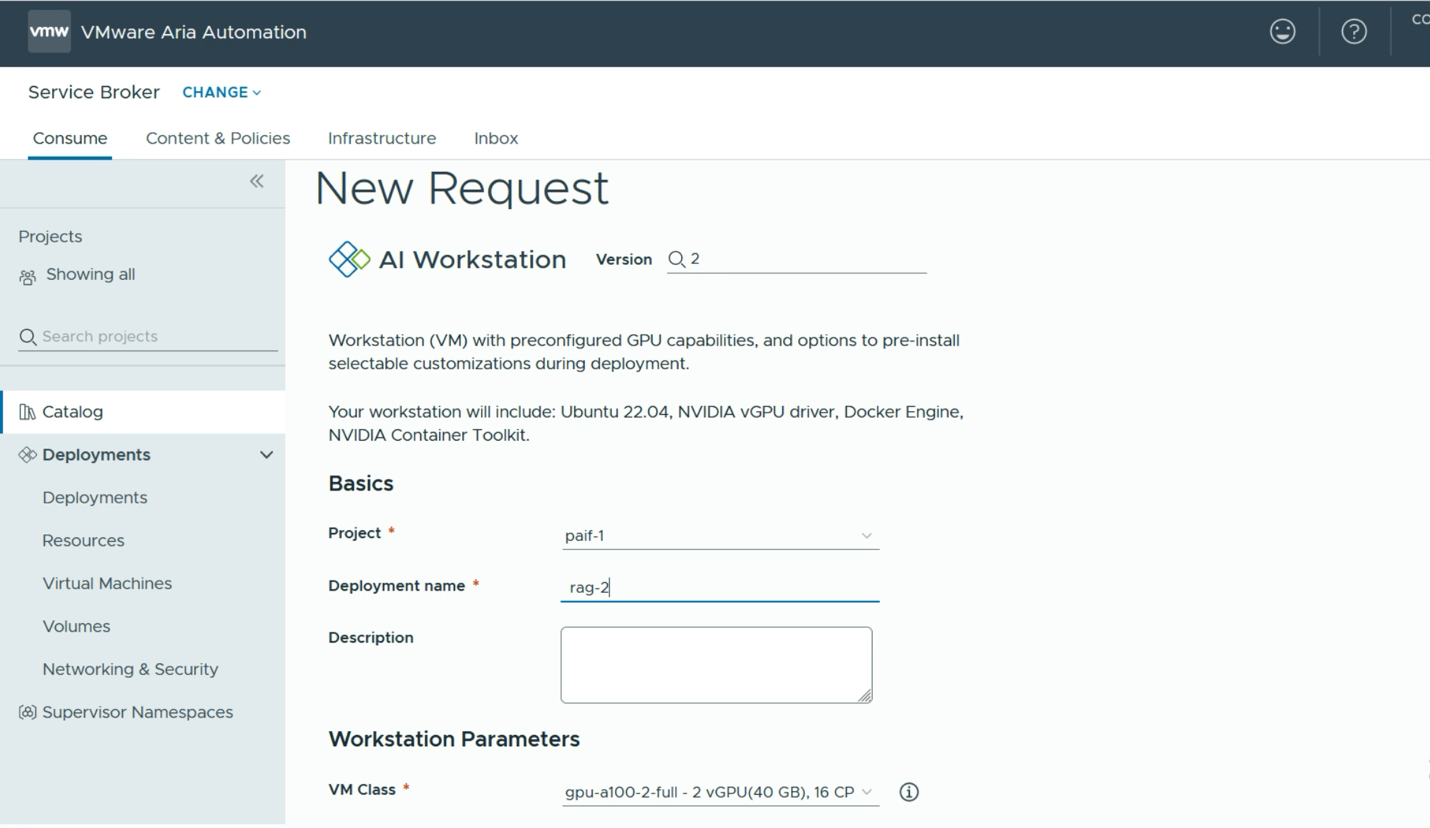
Here the user simply decides on a name for their new deployment and this name will become a namespace into which one or more of the resulting VMs will be placed. An important decision that is made here is the “VM Class”. There are a number of these to choose from – all set up in advance by a systems administrator. The choice here determines the amount of GPU power and the number of GPUs that will be assigned to this deployment (at the VM level). This is a similar concept to the vGPU Profile that is commonly used in setting up NVIDIA’s vGPU software on VMware. The user may also choose to lower or increase the CPUs and Memory that are allocated to their deployment VM, or VMs. Once that decision is taken, we move on to deciding on the tooling and containers that will be present in the deployment VM. As seen below in the Software Bundle section, we could just go with a simple PyTorch Notebook. There will be several different software bundles for TensorFlow, DCGM, RAG example workflows and others that are provided.
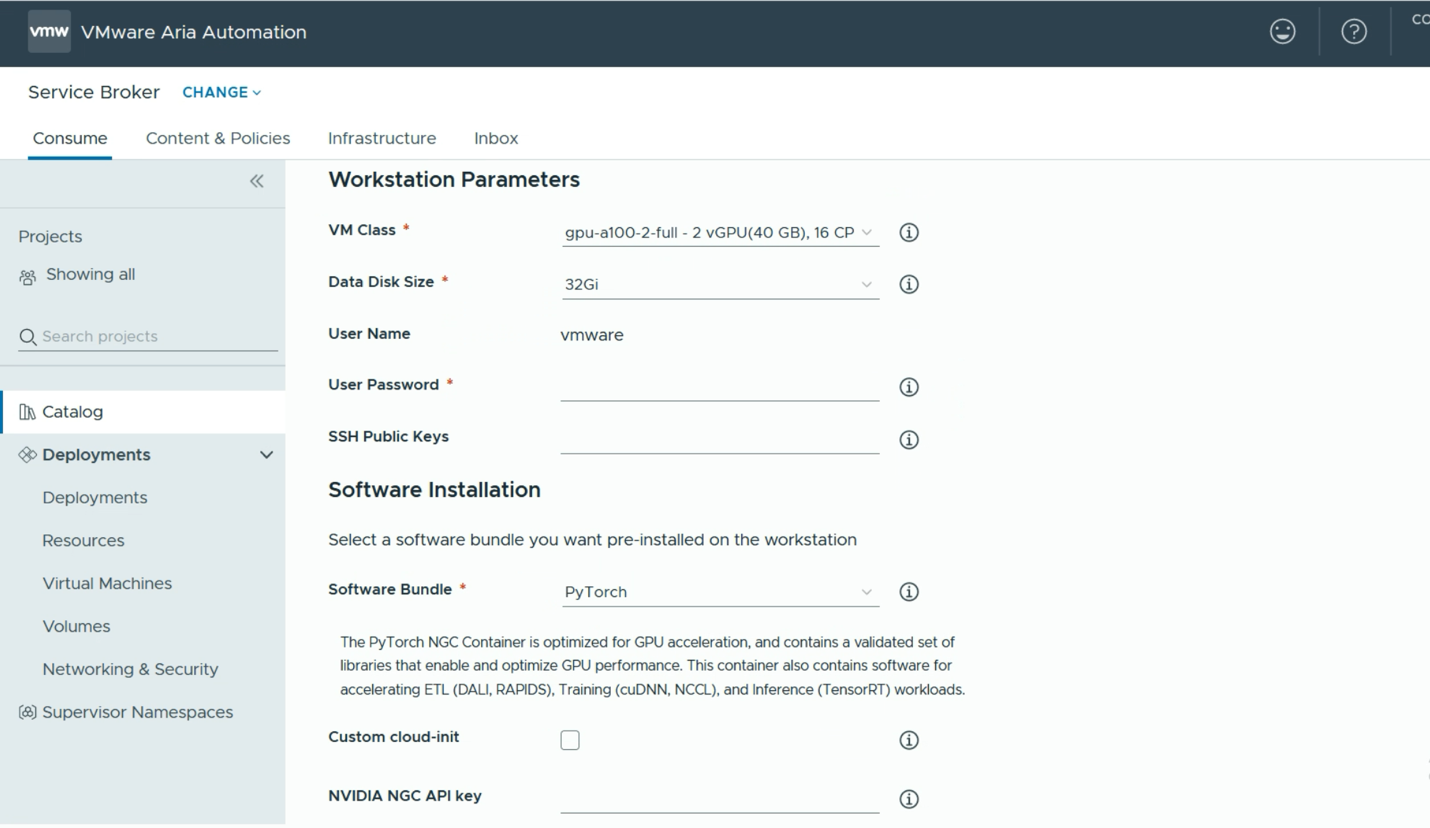
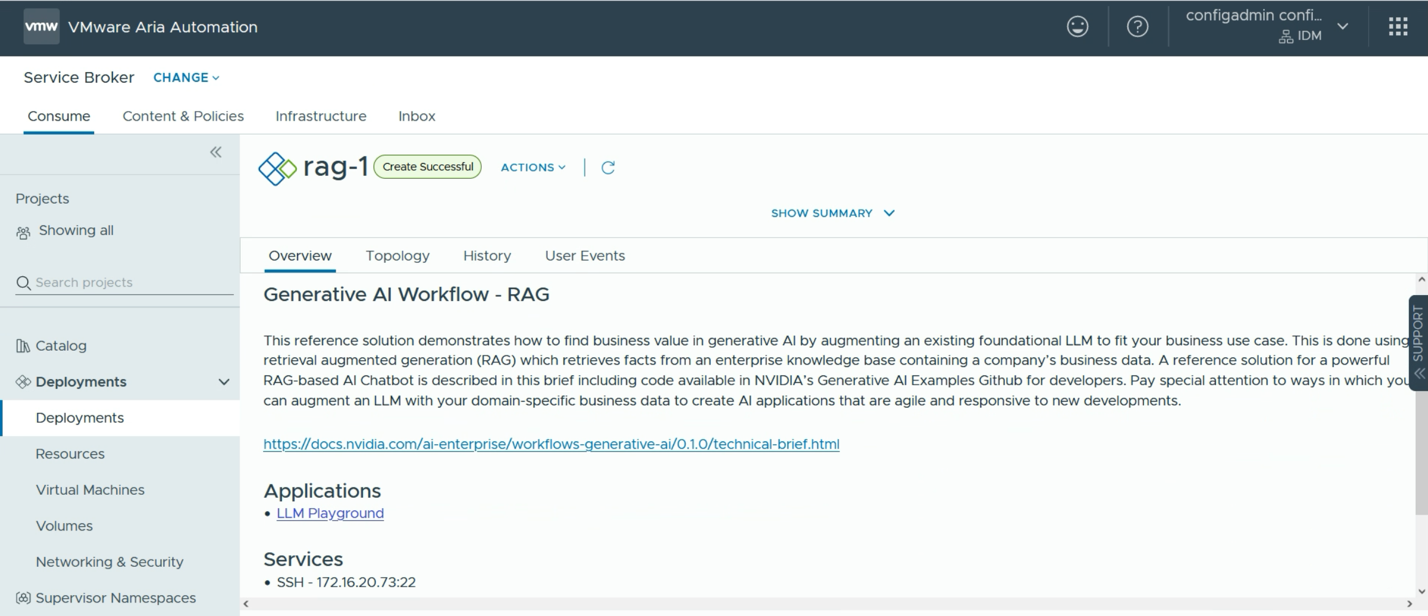
However, there are several tooling platforms from which the data scientist user can choose here. One example is the Generative AI Workflow – RAG example shown below. This will give us a pre-built application that is capable of being used as a template or prototype for a Retrieval Augmented Generation application, using multiple NVIDIA microservices, such as the NVIDIA NeMo Retriever and the NVIDIA Inference Microservice (NIM). Below, we see that RAG Workflow software bundle being chosen. The set of microservices and models supporting this workflow can be loaded into a private repository, such as Harbor, or they can come directly from NVIDIA’s GPU Cloud (NGC). If our user wants to use the NGC, then the appropriate NGC API key is required.
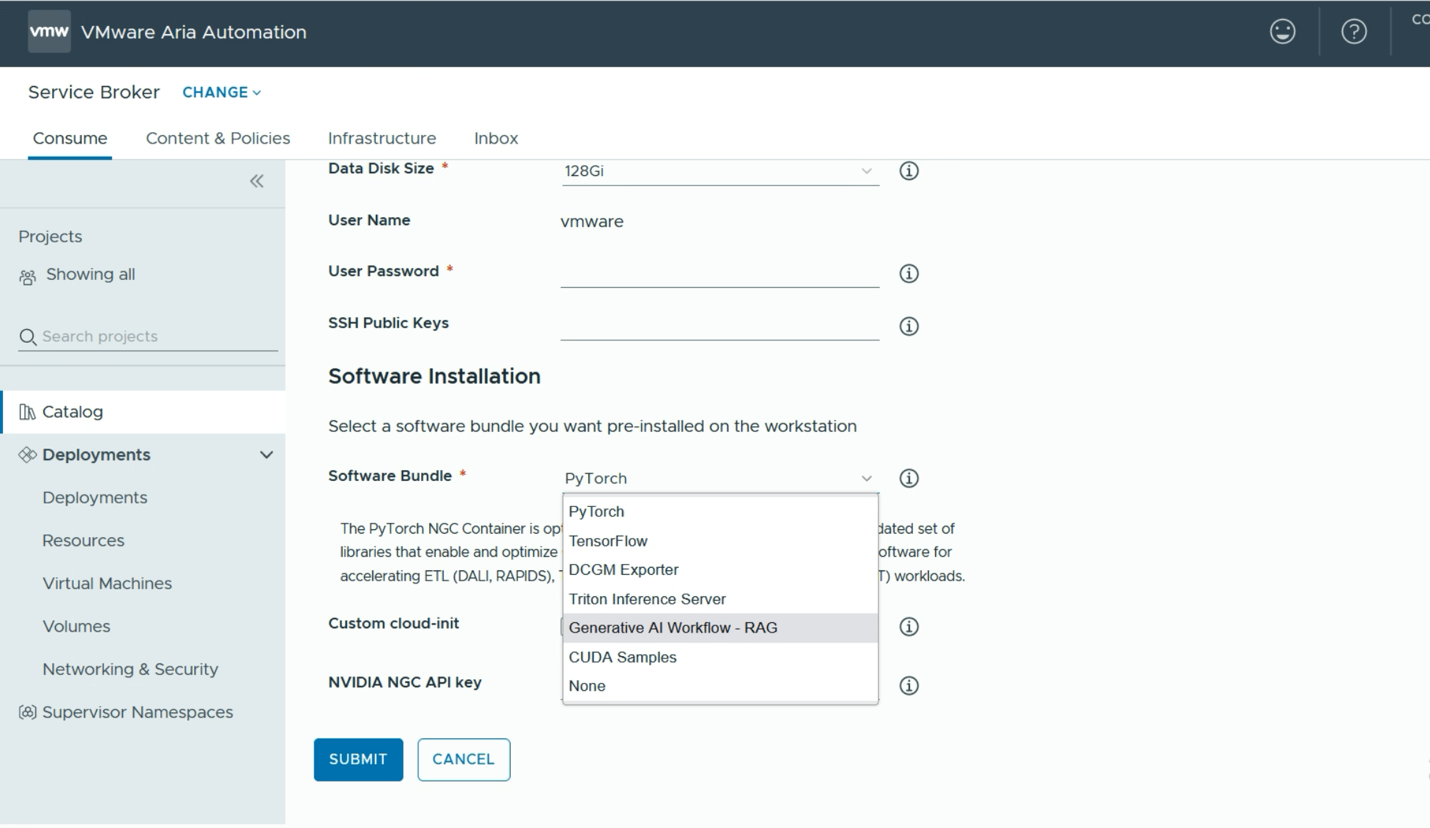
At this point, we are ready to submit our request. From this point onwards, no further interaction with the data science user is required and one or more VMs will be deployed automatically by the Aria Automation tool, with all the necessary microservices and tools loaded into them. One can monitor the progress of this automated deployment using the tool as seen below.
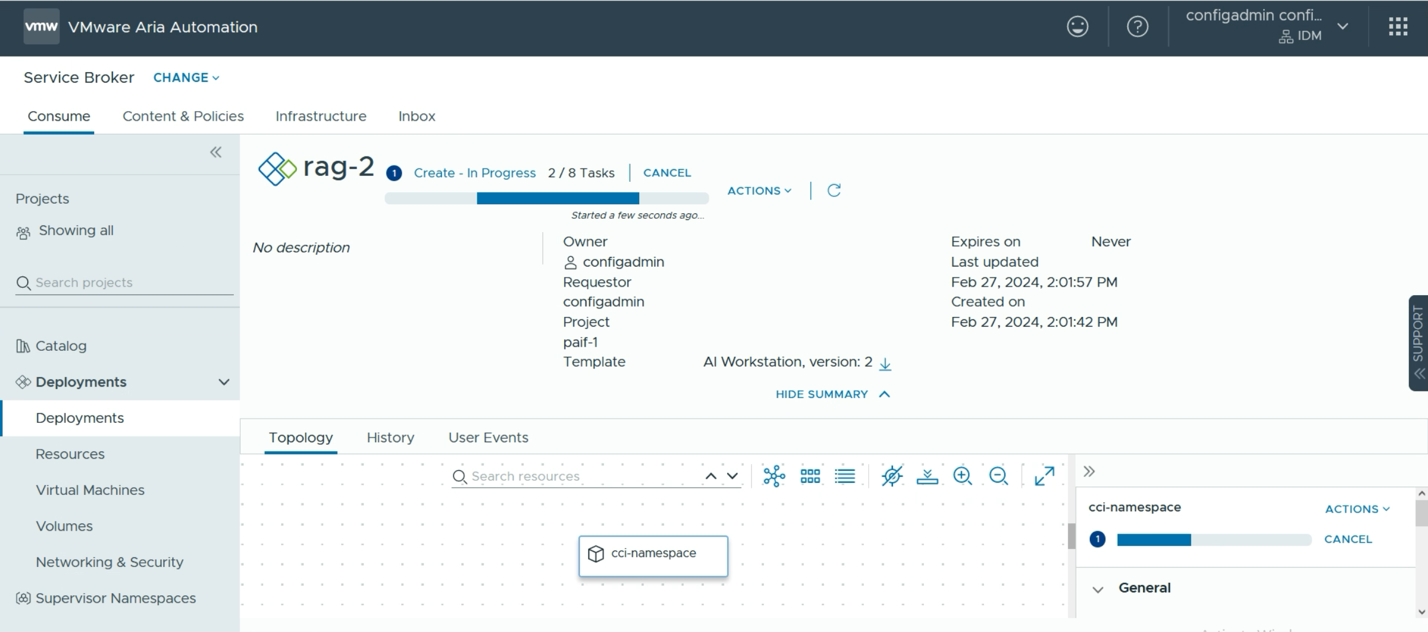
Once the deployment has been done, we see the summary page below, indicating the deployed VMs are now ready and actively deploying all the tooling from the repositories that were chosen. A short time after this, all necessary tools and platforms will be fully downloaded and deployed and ready to go. At that point, the data scientist user would simply click on the “Applications” link and be taken straight into their environment.
Deep Learning Virtual Machines
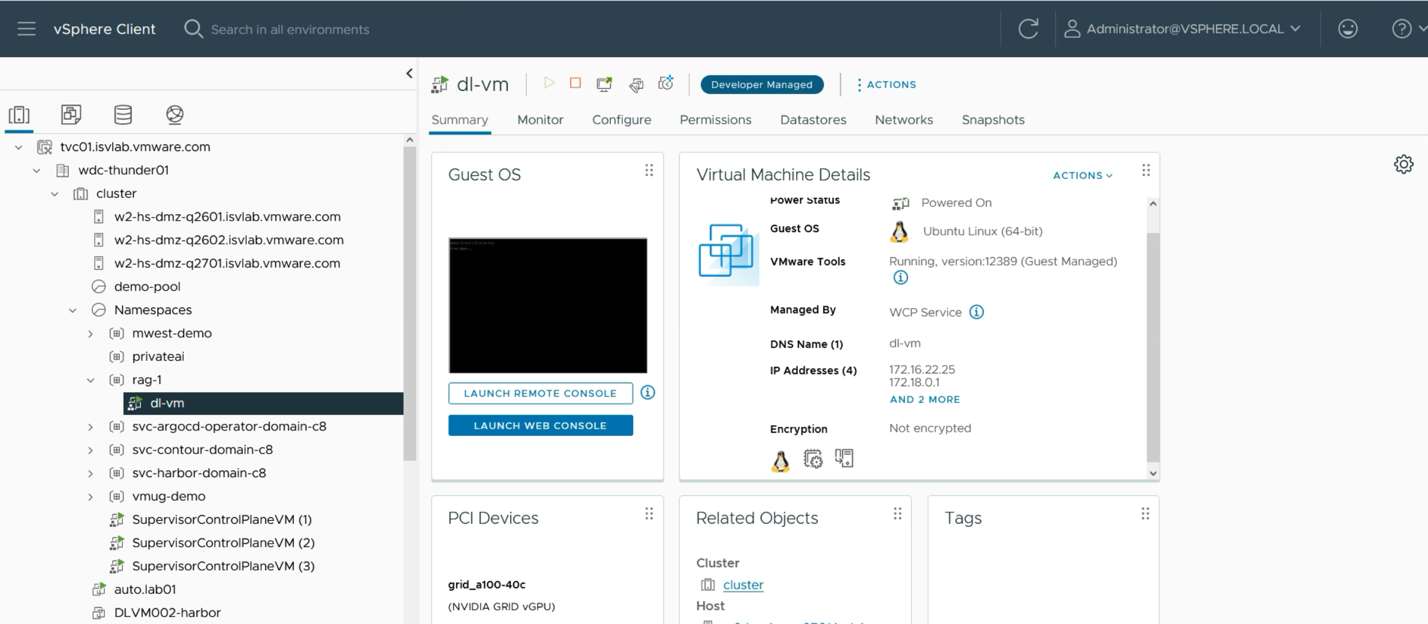
In a very simple deployment example, a VM running within a namespace is seen by the systems administrator or devops person using the vSphere Client as shown below. The “dl-vm” in this case contains all the container runtime, libraries and microservices that make up this RAG application. One of the two vGPUs that we assigned to fulfill the data scientist’s request is shown in the PCI Devices pane within the vSphere Client. We will see further monitoring of these GPUs later in this article.
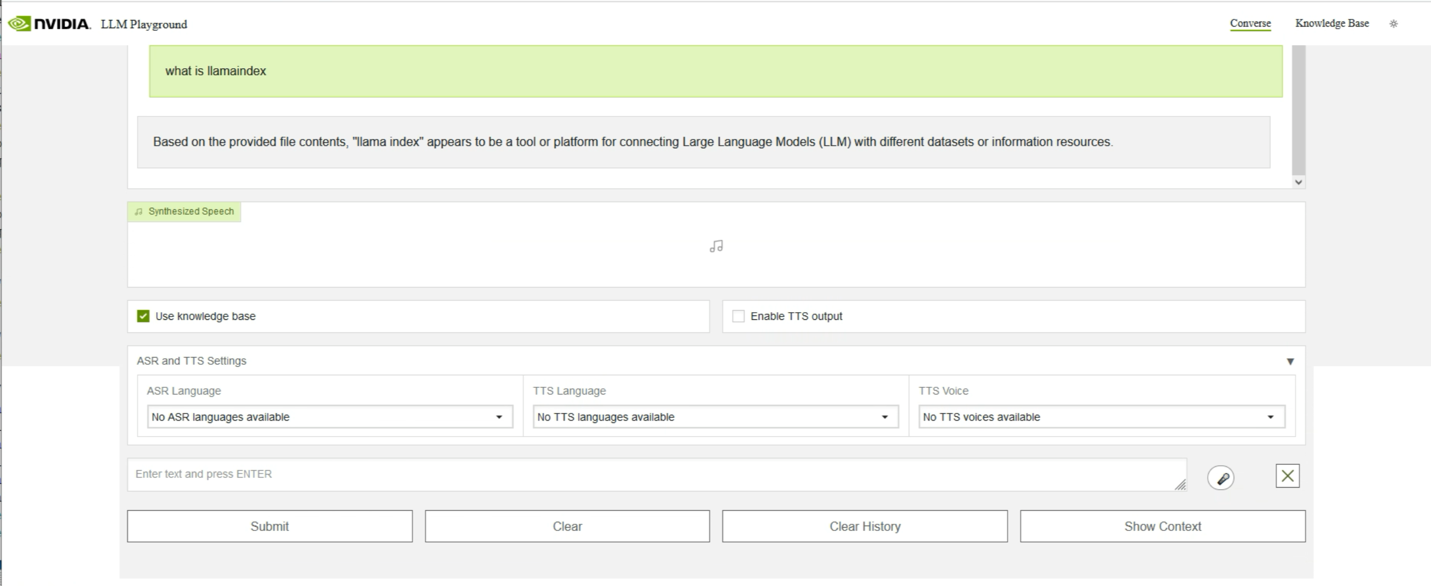
A Chatbot Application that Uses Retrieval Augmented Generation (RAG)
Here is an example of a chatbot application’s user interface that is making use of the LLaMa-2 model along with a vector database (pgVector in our case) to support the RAG of the application. The radio button named “Use Knowledge Base” shown as activated here, instructs the application to use the vector database as a source of documents and information to answer the user’s question. That question may not have an answer in the LLaMa 2’s training data, so it cannot answer questions that refer to “private” data. Here we use “llamaindex” as a proxy for such private enterprise data.
In fact, LlamaIndex is a very modern technology that is used behind the scenes by the RAG application itself for access to data sources.
If the data scientist is curious as to what microservices are deployed to support this application, then they can see that by logging into their new VM. This can be done from the final deployment page in Aria Automation as seen above under “Services” -> SSH with the address of the new VM. On logging in to their VM, with their own password chosen earlier at from original request time, the data scientist can see their microservices names with their status.
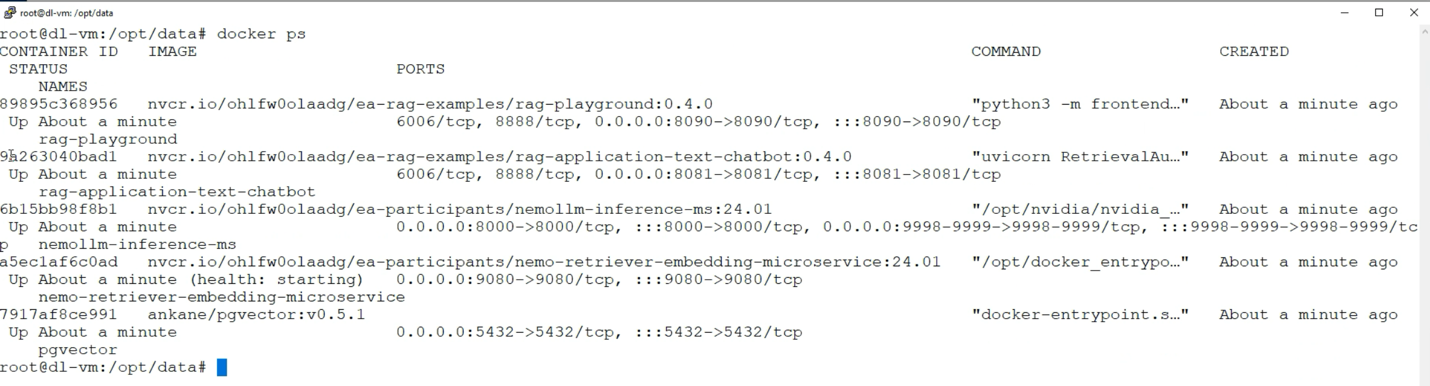
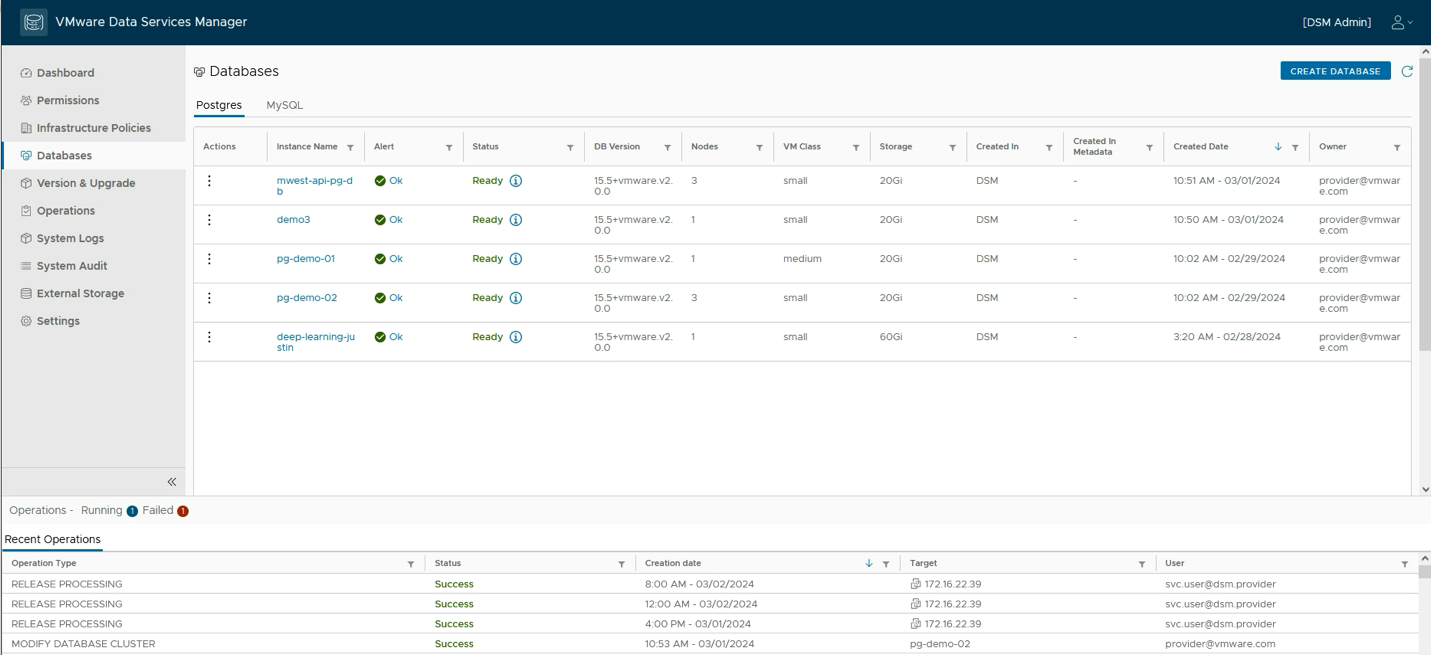
The third microservice from the top above is the NVIDIA Inference Microservice supporting the Llama 2 model that we chose to deploy. The fourth microservice in the list is the NVIDIA NeMo Retriever microservice that is handling the embeddings for the loaded data into the vector database as well as handling embeddings for queries executed on the database to answer user questions. The pgVector microservice seen above uses a Postgres database instance running within the enterprise separately. We provision such databases using a VCF tool called Data Services Manager, that presents a UI for provisioning several different database types.
If the user required this kind of application to be deployed on Kubernetes, then the NVIDIA suite of microservices includes a “RAG LLM Operator” that can be used with Helm for that purpose – in a separate deployment. There are many different RAG-based application examples seen in the appropriate NVIDIA NGC repository.
Private Containers/Microservices
Depending on the privacy level that is required by the enterprise, the process above can be customized to use a local repository for the various artifacts shown above. VCF enables us to use a Harbor repository running locally within our enterprise to store these container images once they have been vetted by the data science team and accepted for use in applications. With the Harbor service enabled, a user can see their private collections of containers within various projects, as shown in the VCF Harbor service here. This Harbor deployment is running as a supervisor service in a Tanzu Kubernetes environment that is running in the lab. A manager of such a repository would choose the labels that apply to the microservices/containers that they wish to make available for download to the data science community.

Monitoring GPU Consumption and Availability
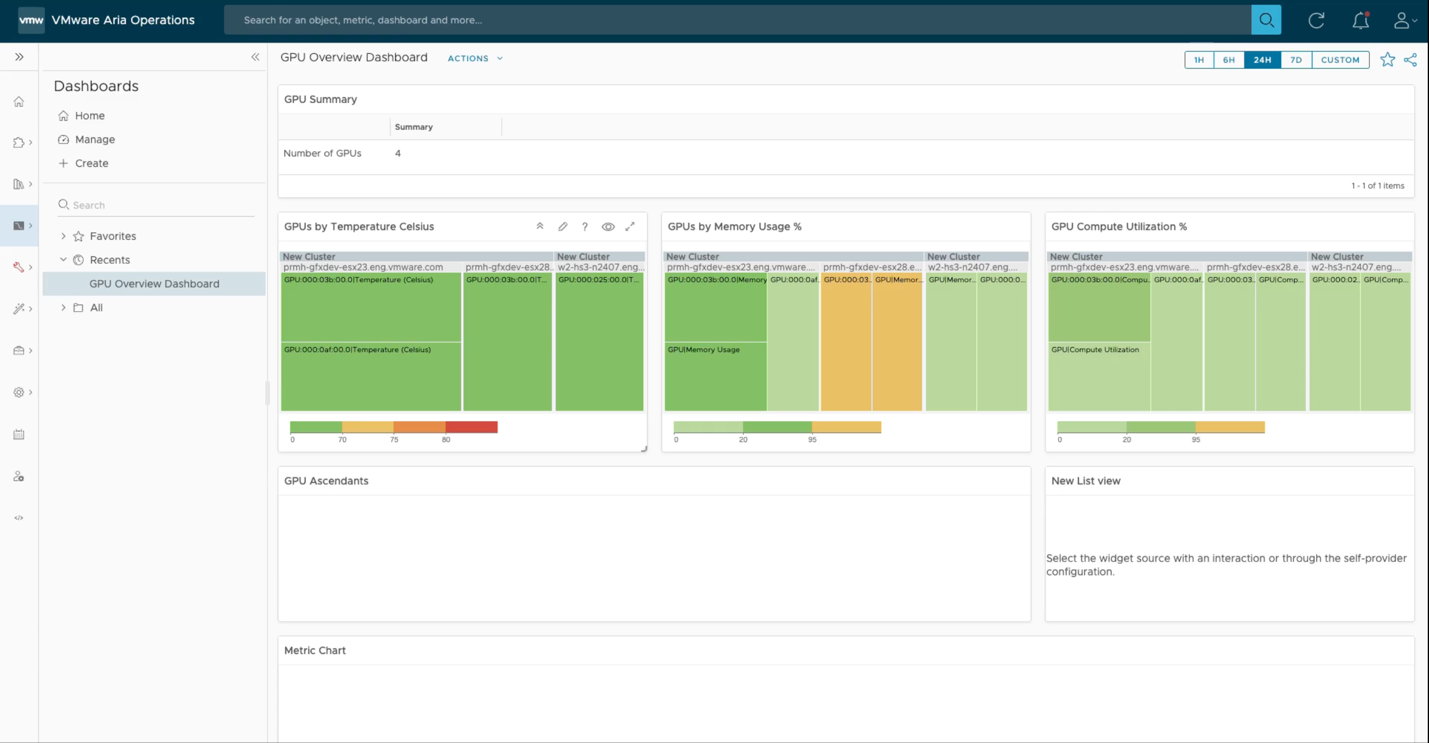
Within the VMware Cloud Foundation portfolio, there are configurable views you can use or build of your GPU estate, embodied in tools such as Aria Operations seen below. What we present here is a heatmap view of the various clusters within the datacenter that contain GPUs and their status with respect to core compute, GPU memory usage and temperature. These are top level panels that can be drilled down into to get more fine-grained views of the behavior of any one system or GPU device.
As we see below, we can choose a particular cluster of host servers and observe the GPU consumption for that cluster only. A cluster may be dedicated to one group of users within a certain Workload Domain in VMware Cloud Foundation, for example. We can drill down here to individual hosts within the cluster and to individual GPU devices within a host server. The second from left navigation pane here shows the cluster members, i.e. the set of physical host servers, and the pane to the right of that shows the physical GPUs on the selected host, identified by the PCIe bus ID here. We have full customization power over the metrics shown in the graphs within the rightmost panel here. We can compare these different metrics using the Aria Operations tool.
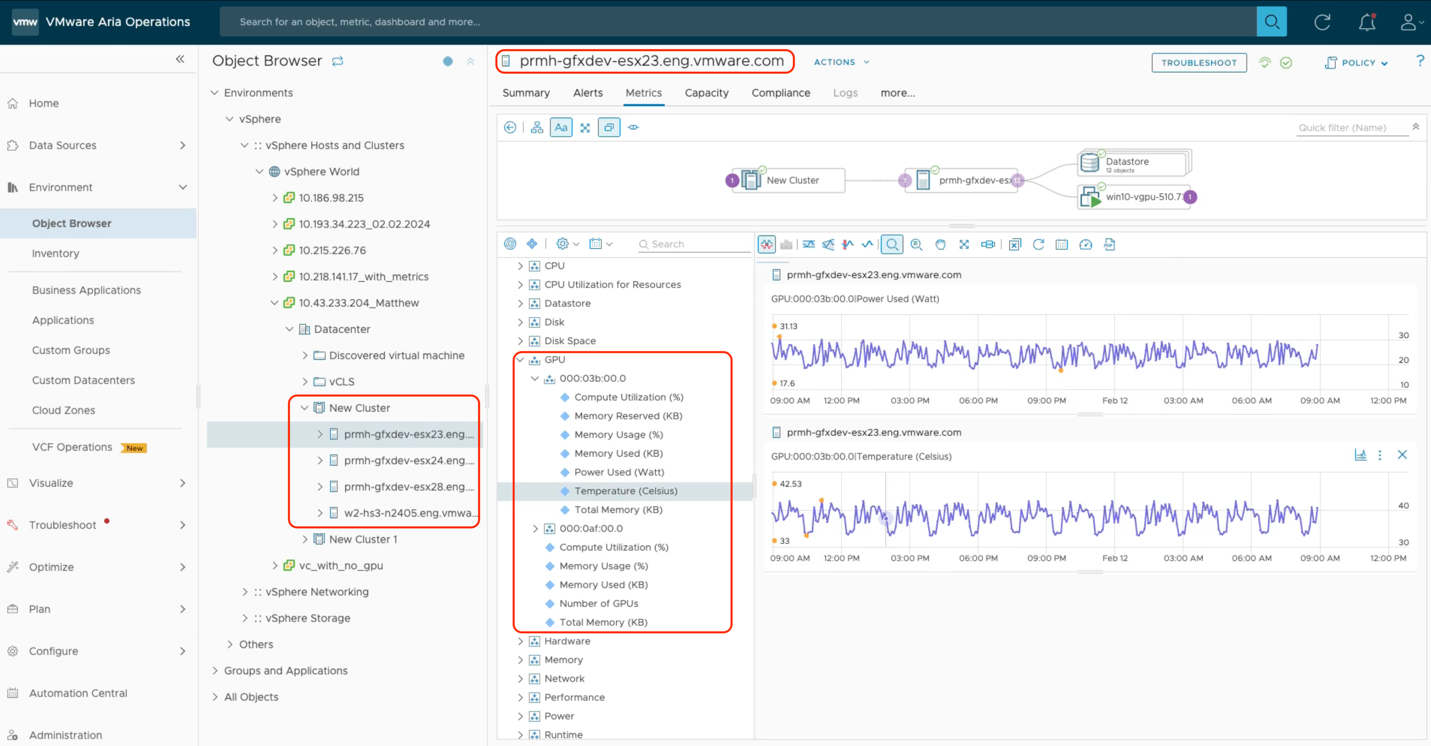
Lastly, if we want to see the overall cluster’s performance as a function of the GPU power used on that cluster of hosts, we can use the GPU metrics seen here to get a view on how the whole cluster is behaving, not just with respect to its total GPU consumption, but all other factors as well.
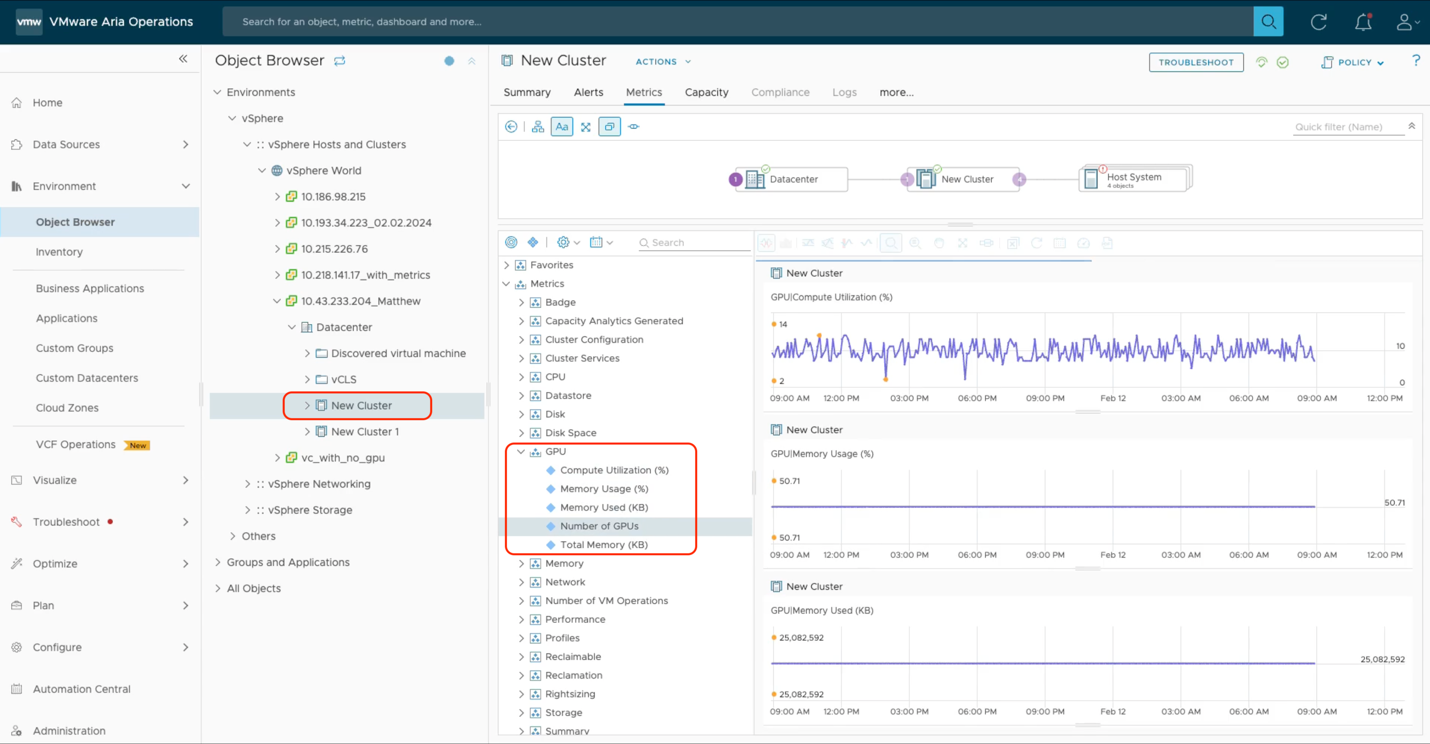
These views of GPU usage and availability are very important to the systems administration team who want to see what remaining capacity they have in the GPUs on all clusters. This is key to doing accurate capacity planning for new applications they want to deploy. Future developments in this area are being investigated to allow further drill down to the VM and vGPU levels.
Conclusion
In this article, we explore the VMware Private AI Foundation with NVIDIA technology, to understand the ease of use the system provides to the data scientist at provisioning time and further at ongoing management time. We use the Aria Automation capability for customizing AI deployment types and for removing the infrastructure details from the data scientist’s concerns, allowing them to be more productive in their modeling and inference work. We use a set of Deep Learning VM images as a basis for this provisioning step, where these images can be downloaded from VMware or indeed custom-built to serve the needs of a particular enterprise. A sample RAG application is deployed on a single VM as a proof-of-concept. That application makes use of the NVIDIA Inference Microservice (NIM) and NeMo Retriever Embedding Microservice, along with the pgVector database technology to support the end-use application, the LLM UI. We used the Harbor container repository to maintain a private collection of tested microservice containers for ease of download and for privacy. We explore the monitoring and management capabilities of the Aria Operations tool within the VMware Cloud Foundation to determine the current and past state of our GPU consumption, to do capacity planning and optimization of the GPU estate. This comprehensive set of technologies shows the commitment of the VMware by Broadcom and NVIDIA organizations to making you successful in your work on Large Language Models and Generative AI to optimize your business.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.



