

Writing data quickly and consistently while maintaining resilience and data integrity is no easy task. Enterprise storage solutions like vSAN are designed to achieve these requirements, even in the face of high-demanding workloads and a variety of operational conditions. But writing data is only one responsibility of a storage system. It must know where to read the data from and retrieve the requested data consistently, and accurately. This is more challenging than it sounds as data capacities grow to extraordinary levels.
The Express Storage Architecture (ESA) in vSAN introduced a new way of processing and storing data with the highest levels of performance and efficiency. Its new data path and underlying data structure achieve this by writing data in a highly optimized way that minimizes I/O amplification and computational effort. It was also built to write data to modern NVMe flash devices in the most efficient way, minimizing garbage collection activities, and prolonging endurance. But its ability to store large amounts of data efficiently means that it also must be able to read data in a speedy and efficient manner. Let’s look more closely at how the ESA in vSAN reads data.
Data Storage in the ESA
Much like vSAN’s original storage architecture (OSA), the ESA stores data in a manner that is analogous to an object store, where an object, such as a VMDK is a logical boundary of data, instead of an entire volume like a datastore using a clustered filesystem like VMFS. See the post “vSAN Objects and Components Revisited” for a refresher. The two architectures also share many of the same layers in the vSAN storage stack that help determine object and component placement, data paths to the object data, host membership, and so on.
But the data path and vSAN ESA’s handling of metadata is quite different from the OSA, which not only gives the ESA the ability to write data quickly and efficiently but read data efficiently. vSAN ESA’s patented log-structured filesystem (vSAN LFS) and the ESA’s heavily revised local log-structured object manager (LSOM) are what is behind the ESA’s impressive performance, data efficiency, and snapshotting capabilities. Both vSAN layers create and manage their own metadata to help determine what should be retrieved, and where. The focus of this post is how metadata in the vSAN LFS helps with guest VM read operations.
Metadata Storage in the ESA
Metadata, or “data about data” is what allows a storage system to know where to fetch the data requested. As storage system capacities grow to extraordinary levels, metadata can place strain on a storage system if it has not been designed for scalability. This can lead to excessive consumption of CPU, memory, and storage resources as well as hampering performance.
The ESA uses a highly efficient and scalable approach to metadata management. It uses several data tree structures, known as B+ Trees that provide a mapping for vSAN to reference data efficiently. It is comprised of index and leaf pages that hold the respective metadata. But this metadata can grow to be quite large given the device capacities of today and on the horizon. As shown in Figure 1, the ESA uses a highly scalable approach where some pages are held in memory, while others are stored in the performance leg components of an object, or even the capacity leg components of an object in compressed form. vSAN accounts for this metadata storage in its LFS overhead calculations. See the post “Capacity Overheads for the ESA in vSAN 8” for a better understanding of capacity overheads in the ESA.
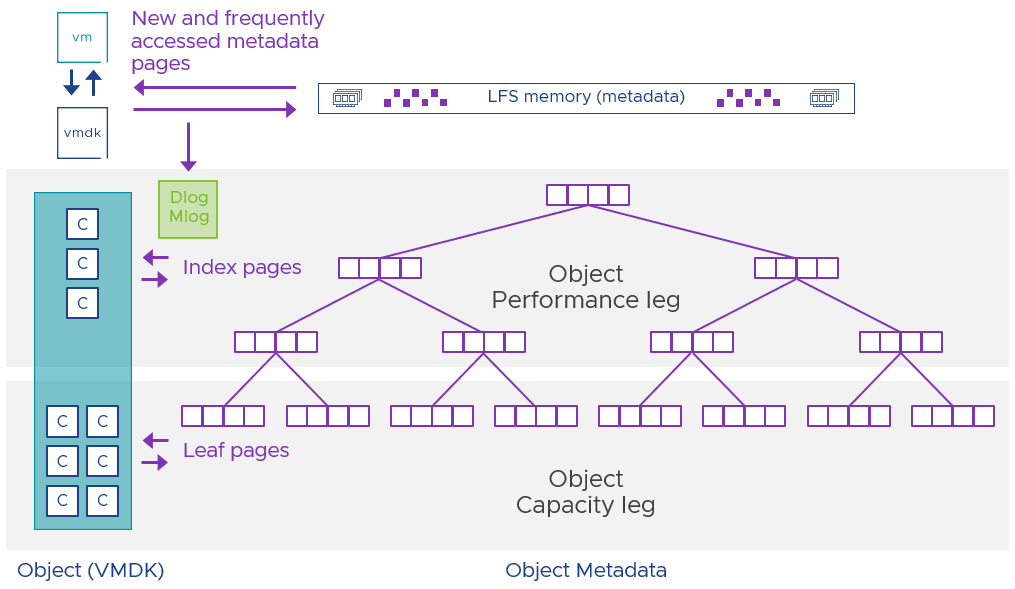
Figure 1. vSAN ESA’s use of B+ Trees for efficient metadata storage and management.
The ESA strives to maintain as much of an object’s metadata pointing to the actively accessed data blocks (called the “working set”) in memory as possible. This caching of metadata in memory allows frequently accessed B+ Tree index and leaf pages to be referenced quickly in memory, as opposed to the additional effort taken to retrieve these pages from disk. This improves performance for accessing its working set since those B+ Tree pages would be readily available in memory.
Read Operations in the ESA
Let’s look at how data is retrieved in the ESA. The example below assumes a VM is using a vSAN storage policy of a Failures to Tolerate of 2 (FTT=2) using RAID-6 erasure coding. This means that the data with parity is spread across a minimum of 6 hosts. We will also assume the I/O is aligned, and that checksum verifications and data compression is enabled since they are enabled by default in the ESA.
The following describes the flow of a read operation in the vSAN ESA.
- The Guest OS of the VM issues a read request and passes that through the vSCSI stack of ESXi to the Distributed Object Manager (DOM) client for the VM.
- The DOM client will check the DOM client cache for any recently used blocks, and satisfy the read operation if the available block is in cache. Otherwise, it proceeds to the next step.
- The DOM owner of the object (determined when the client opens the connection to the owner) will take the additional steps:
- The object’s LFS in-memory stripe buffer, sometimes referred to as a bank, will be checked if it is holding the requested data payload. If not, it proceeds to the next step.
- A lookup of metadata will be performed to build a collection (referred to as an “array”) of physical addresses of the data payload requested. This metadata resides in memory or on disk in metadata tree structures, known as B+ Trees.
- A multi-read operation will be issued to the portions of the requested data payload referenced in the lookup.
- The multi-read operation will return the data payload to the DOM client, where the checksum will be verified and the data will be decompressed.
- The data will be received from the DOM client through the vSCSI stack to the guest OS of the VM.

Figure 2. The anatomy of a read operation in vSAN ESA.
How do the durable log and metadata log shown in the illustration above plays a role in a read operation? As described in the steps above, they don’t. These logs are only used to persist the metadata to disk as it is initially created so that the metadata can be reconstructed in the event of a host failure. While the metadata is initially persisted to disk in these logs, it is held in memory for as long as possible before being written from memory to the B+ Trees on disk. This makes B+ Tree update operations highly efficient.
Summary
As the industry moves to extremely high-capacity storage devices, the challenge for storage systems is not necessarily the storage of data, but rather the design of metadata structures that allow for fast and efficient data retrieval. The Express Storage Architecture in vSAN was designed with this in mind and is what helps make it so flexible, scalable, and special.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




