
Digital transformation is a key C-level initiative, driving organizations to create and deliver greater value and business insights from the massive volumes of data generated daily. When managed properly, these insights can provide instant competitive advantage, maximize efficiency and increase productivity that can be measured directly to the organizations’ quarterly earnings per share (EPS). This transformation is occurring across all industries, and artificial intelligence (AI) is at the center of this revolution.
The challenge for many organizations architecting AI infrastructure into their overall technology stack is the complexity associated with it. Traditionally, AI technology hasn’t integrated seamlessly into existing IT stacks and operational processes. This is compounded by the fact that data scientists typically want to experiment quickly, configuring and reconfiguring clusters to get to their desired outcome. There is also business pressure to move these initiatives rapidly along the AI lifecycle, with a goal of scaling AI workloads into production-ready environments as quickly and seamlessly as possible.
Announced at VMworld 2021, the integration of the NVIDIA AI Enterprise software suite and vSphere 7 Update 3 makes it possible to deliver Kubernetes clusters to AI developer teams at a rapid pace, while still enabling enterprise-class governance, reliability, and security within VMware vSphere with Tanzu environments. For organizations implementing AI/ML (machine learning) infrastructure, the combination of these technologies becomes a cornerstone to deliver business outcomes without creating friction between IT operations and lines of business.
The reason this solution is so powerful is that it combines the strengths of both companies. VMware brings deep knowledge of infrastructure, operations, and management, and NVIDIA delivers accelerated computing expertise, GPU virtualization technology, and prebuilt sets of AI software, pre-trained models, and other tools that data scientists can use to create applications and quickly deploy them. The NVIDIA AI Enterprise suite includes frameworks and tools like PyTorch, TensorFlow, TensorRT, NVIDIA RAPIDS, and NVIDIA Triton Inference Server, all packaged up as containers that can be easily deployed and managed.
Delivering AI-Ready Infrastructure
With the GA announcement of VMware Cloud Foundation 4.4, these innovations are now available through integration with VMware’s flagship hybrid cloud platform. This elevates the solution to deliver AI-Ready Infrastructure, supporting VM and container-based workloads integrated with NVIDIA AI Enterprise to enable deployment of AI on NVIDIA-Certified Servers from leading manufacturers with simplicity at production scale. This solution enables IT infrastructure teams to stand up VM and Kubernetes clusters using NVIDIA AI Enterprise when deployed with VMware Cloud Foundation. In addition to the accelerated performance characteristics, this solution reduces time to market, minimizes deployment risk, and lowers the total cost of ownership.
As shown in figure 1, this combined solution enables customers to deploy AI/ML workloads with confidence using the NVIDIA AI Enterprise suite to run and operate AI workloads within a full stack VMware Cloud Foundation environment. Performance gains are realized through the raw power of NVIDIA Ampere architecture GPUs while providing a platform that scales to meet the demands of development and production workloads. This enables data scientists and researchers to build AI-Ready Infrastructure as it’s needed.
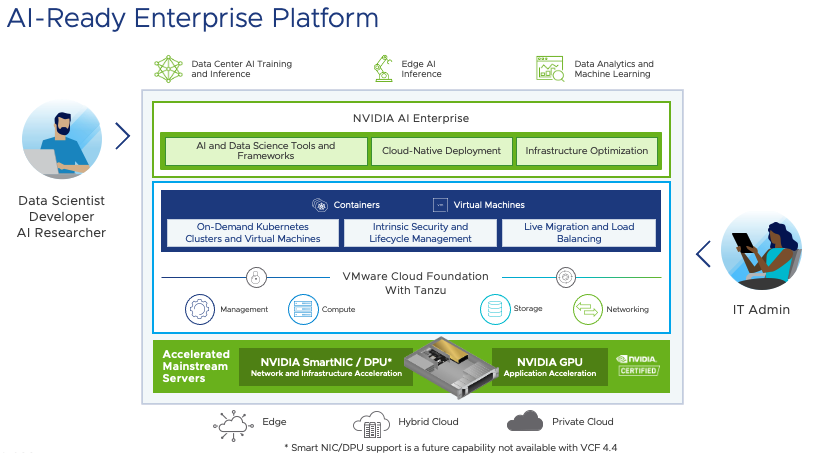
Figure 1: NVIDIA AI Enterprise with VMware Cloud Foundation
vSphere Admins Maintain Full Control of Infrastructure Resources
Admins can also deploy, configure, and manage this infrastructure in an automated fashion, while leveraging the cloud operating model of a flexible, software-defined environment. Administrators also benefit from being able to utilize vSphere DRS for initial placement and vMotion migration for VM-based applications configured with NVIDIA Ampere architecture GPUs during maintenance and LCM operations. This solution enables vSphere admins to configure and control access to the AI/ML optimized resources for access to developers and data scientists on demand using standardized HCI building blocks. VM or Tanzu Kubernetes Grid (TKG) workloads can then be configured to consume GPU resources from a selection of pre-configured profiles. NVIDIA Guest OS drivers are then installed which allow the workload to integrate with the many AI/ML functions contained within the NVIDIA AI Enterprise suite.
Data Scientists Can Self-Serve to Maximize Agility
Data science and developer teams can consume admin-assigned GPU resources when they need them, to support AI and data analytics applications and run them on-premises without having to wait extended periods of time for provisioning. Physical GPU resources can be dedicated, shared, or partitioned across one or more virtual machines or Tanzu worker node VMs, driving up utilization and improving economies of scale. Developers can consume GPU resources that have been assigned by the IT admin team by selecting a pre-configured vGPU profile. Developers can consume GPU resources and scale up and down when needed by data scientists/dev teams independently of the IT admin teams, by selecting preconfigured vGPU profiles.
Delivering Raw Performance While Maximizing GPU Utilization
Partitioning NVIDIA A30 or A100 Tensor Core GPUs into multiple instances provides predictable performance while increasing utilization of these critical system resources. An NVIDIA GPU using the NVIDIA AI Enterprise suite can be configured to support Time Slicing or Multi-Instance GPUs (MIG). Both offer many advantages. Here are some top considerations:
Time Slicing:
Workloads configured in Time-Sliced mode share a physical GPU and operate in series. It is enabled with NVIDIA vGPU software, which is included in the NVIDIA AI Enterprise suite. Time Slicing mode is the default setting on an NVIDIA GPU. Time Slicing mode is best for workloads where resource contention is not a priority. Time Slicing is the most economical approach to sharing GPU resources. It allows users to maximize utilization of GPU resources by running as many workloads as possible on the device. Time Slicing also works best for large workloads that need to consume more than one physical GPU. This allows multiple physical GPUs to be assigned to a single workload.
Multi-Instance GPU
NVIDIA AI Enterprise enables MIGs to provide full hardware isolation, allowing multiple separate workloads which require GPU resources to operate in parallel. MIG technology is an excellent choice when dedicated GPU resources are required to be run by multiple users or tenants. MIG configurations of NVIDIA A30 or A100 Tensor Core GPUs allow users to share a physical GPU and provide predictable levels of performance and quality of service to each VM workload that is using the device. NVIDIA GPUs configured with MIG allow for higher levels of throughput and lower levels of latency when compared with workloads configured using Time Slicing. Another benefit of configuring MIG is security isolation, as memory is not shared across slices.
Dell Technologies, NVIDIA, and VMware
Building on the partnership between Dell Technologies, VMware, and NVIDIA that was introduced at VMworld 2021, Dell Technologies also announced support for the NVIDIA AI Enterprise software suite and GPUs within VMware Cloud Foundation 4.4 on VxRail 7.0.320. VMware Cloud Foundation on VxRail customers will be able to run their AI and ML workloads on a turnkey hybrid cloud for a simplified experience, making it easier than ever to take advantage of all the business advantages of AI.
Impacts to VMware Cloud Foundation Lifecycle Management
When configuring a GPU-enabled cluster within VCF 4.4, hosts are to be configured using vLCM Images. The use of vLCM Baselines (formerly known as VUM) is not supported. Note that while running vGPU workloads on VMware Cloud Foundation 4.4, if the workload is running on TKGs, the TKG worker nodes will be automatically powered off during vLCM operations. If the cluster contains traditional VMs which require GPU resources, these VMs will need to be manually powered-off prior to performing LCM operations for ESXi host patching and updates. After these VMs are powered-off, the VCF operator can then commence with the LCM process. If the GPU-enabled VM is not powered-off the LCM operation will fail. The VCF upgrade pre-check is not GPU aware.
Take The Next Step:
VMware Cloud Foundation takes the integration of vSphere with Tanzu and NVIDIA AI Enterprise to the next level. VMware Cloud Foundation customers can now extend their software-defined private cloud platform to support a flexible and easily scalable AI-ready infrastructure. You can learn more with the resources presented below.
Resources:
VMware Cloud Foundation 4.4 Blog
VMware Tech Zone – vSphere 7U3 What’s New
Sizing Guidelines for ML/AI in VMware Environments
VMware Cloud Foundation Tech Zone
This article may contain hyperlinks to non-VMware websites that are created and maintained by third parties who are solely responsible for the content on such websites.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




