

In this article we walk you through the steps to configure one or more GPUs/vGPUs on VMs that act as Kubernetes nodes. This will be useful to systems administrators and developers/devops people who intend to use Kubernetes clusters with vSphere/VCF for compute-intensive machine learning (ML) applications.
In the AI-Ready Enterprise Platform architecture, seen below, VMware’s vSphere with Tanzu allows developers, data scientists and devops people to rapidly provision multiple Kubernetes clusters onto a set of VMs to enable faster development turnaround. These Kubernetes clusters are called Tanzu Kubernetes Grid clusters (TKG Cluster or TKC for short).
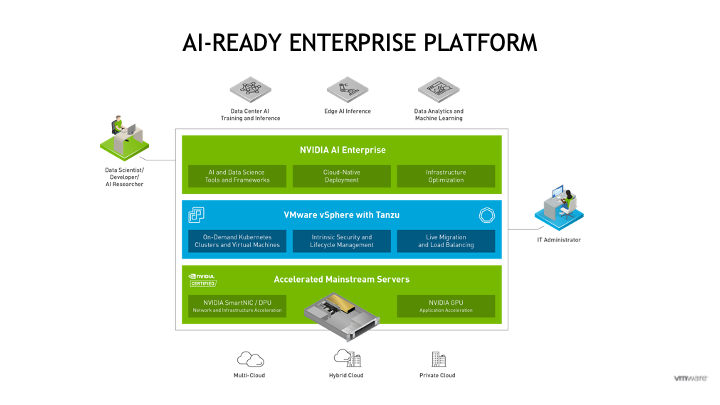
TKG (Kubernetes) clusters host and manage the pods and containers that make up the NVIDIA AI Enterprise suite for the data scientist, as well as their own application pods. Training of an ML model and subsequent inference/deployment with that model very often require compute acceleration. This is because these operations are compute intensive – many matrix multiplications are being executed in parallel during the model training process on large quantities of data.
GPUs have been virtualized on VMware vSphere for many years – and are used today for both graphics-intensive and compute-intensive workloads. Today, using the VMware vSphere Client, a virtual GPU (vGPU) profile can be associated with a VM. These profiles can represent a part of, or all of, a physical GPU to a VM. You are now guided through the parts of this vGPU profile creation at VMClass creation/editing time in vSphere with Tanzu. With Kubernetes tightly integrated into vSphere with Tanzu, vGPUs for VMs on vSphere now accelerate the nodes of a TKG cluster. Naturally, vGPUs are a core component of the joint NVIDIA and VMware architecture for the AI-Ready Enterprise.
On vSphere, the Kubernetes “node” (i.e. a machine destination for deploying pods) is implemented as a VM. There are VMs that play the role of control plane nodes and worker nodes in a TKG cluster. When you create a TKG cluster, as a devops or data scientist developer, using “kubectl apply -f tkc-spec.yaml” what we see in the vSphere Client UI are new VMs that carry out the work of those nodes in Kubernetes. This set of VMs is shown in the vSphere Client for a simple TKG cluster named “tkc-1”, highlighted below.
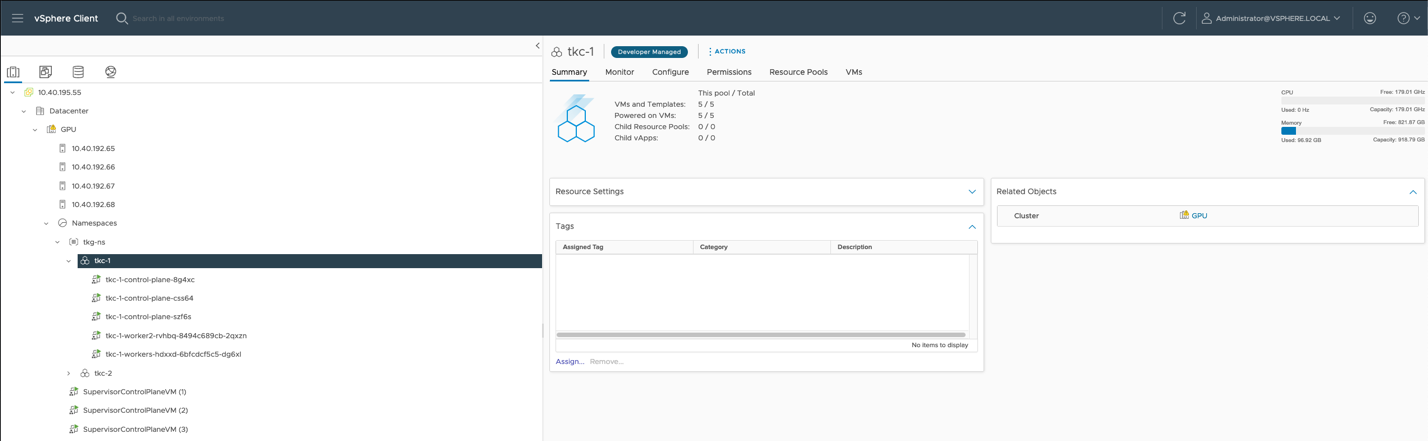
To create a TKG cluster, all the devops/developer person needs is edit access to a namespace, access to the kubectl tool along with a YAML spec file for their cluster. That namespace access is provided to the user by the System Admin who manages the Supervisor Cluster (i.e., the management cluster) in vSphere.
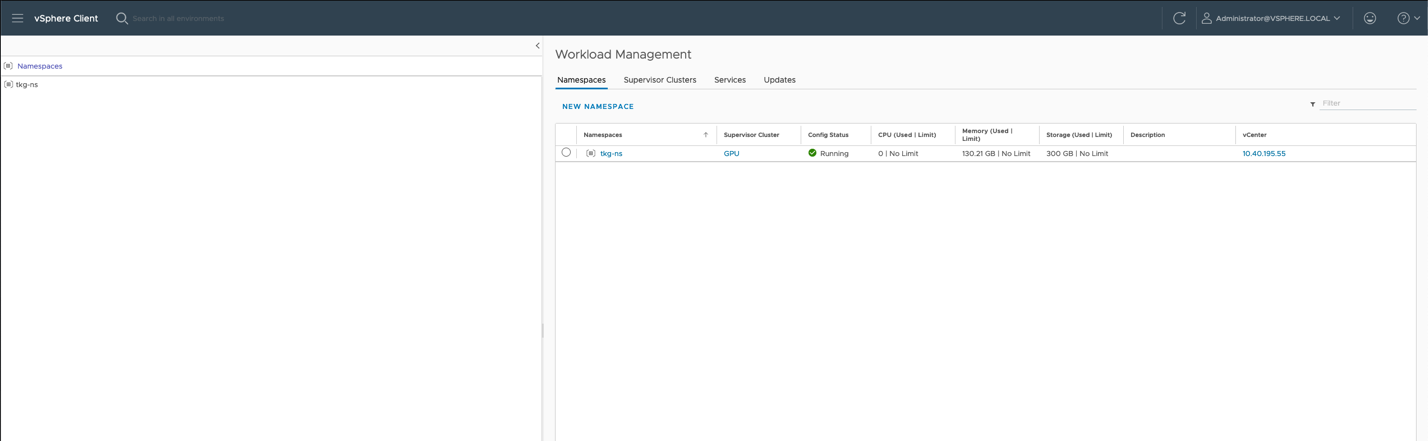
Looking at the example namespace in the vSphere Client that was created as part of the Tanzu setup, we see the various aspects of that namespace, including any resource limitations that may be imposed on it.
If we choose the “Services” item in the menu shown above, we get to see a summary screen describing the set of VMclasses that are part of the Tanzu setup. We drill down into the “VM Classes” tab within the VM Service screen to see the set of VM classes that come associated with this namespace.
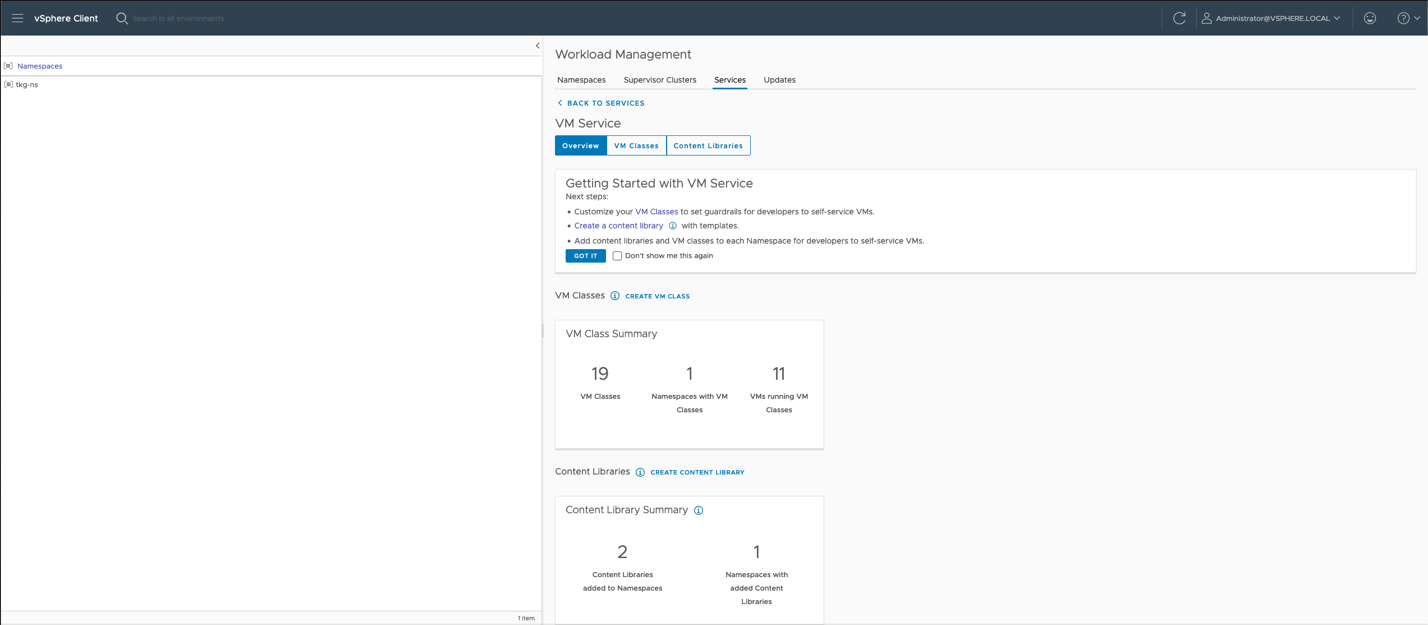
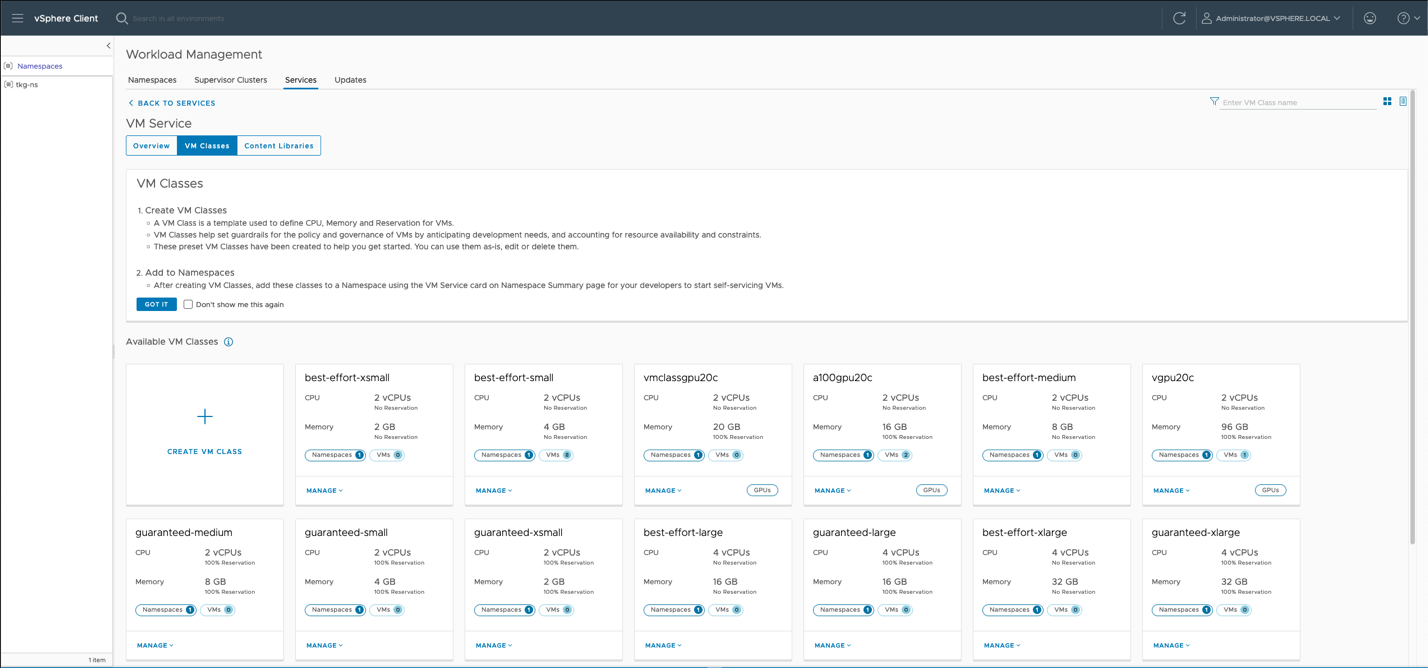
Many of these VMclass examples are provided with the vSphere with Tanzu functionality, but custom VMclass objects can also be created by the user. We look at the set of steps to create a custom VMclass next. Let’s click on the “Create VM Class” tile from the above set to look at that process. We will enter a name for our new VM Class, decide on sizing and choose to add PCIe device, which is going to be our GPU device. This is a familiar step to those who have dealt with vGPU profiles in the vSphere Client in the past.
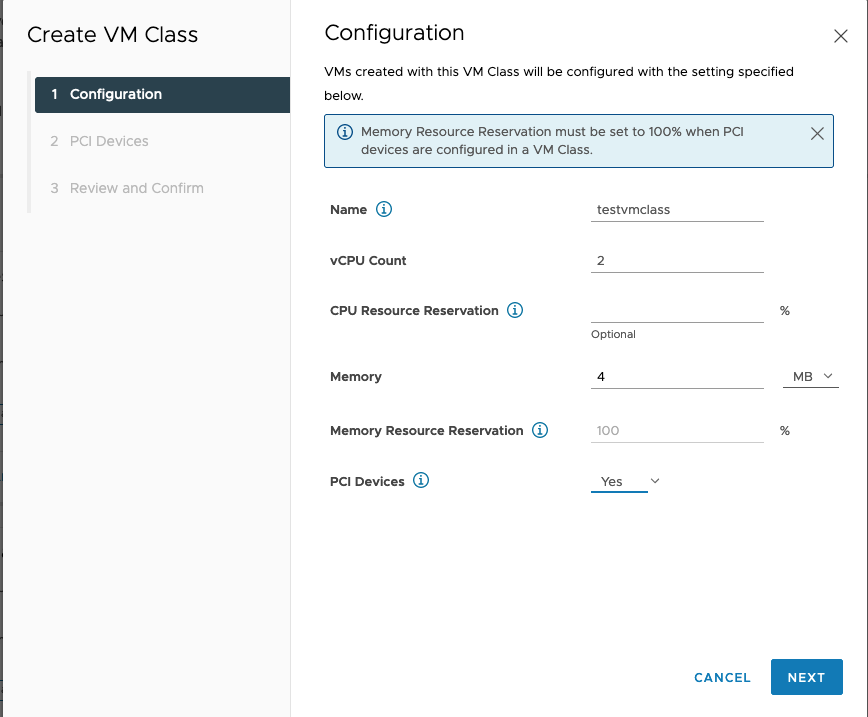
You can adjust the amount of RAM and vCPUs for your VMclass at this point also. We can specify more VM memory than that shown here, if needed. Notice that when you choose to add a PCIe device, the VMs created from your VM class are going to have a full reservation set on their RAM. This is the normal case when GPUs or other PCIe devices are assigned to a VM. Hit “Next” and confirm on the next screen that we are adding a PCIE device. We choose “Add PCIe Device” on the next screen.
When we choose “Add PCIe Device”, we are given an option to choose the “NVIDIA vGPU” device type and then taken to a details screen for GPU hardware type that will back the added vGPU. The options here come from different types of GPU hardware that are visible to our cluster. Different GPU models may be on different hosts in our cluster. Here, our cluster has a mix of A100 and A40 models of GPUs.
In our example class, it is the A100 GPU that we are interested in using – especially for compute-intensive ML work. In your own setup, you may see different choices of GPU hardware here. These are presented to vSphere by the NVIDIA vGPU Host Driver that is installed into the ESXi kernel itself by the system administrator as part of the installation and setup of the GPU-aware hosts. There may be a Passthrough option for a GPU here in certain cases, but we will set that to one side for now and focus on vGPU setup.
|
1 2 3 |
<img class="wp-image-17104" src="https://blogs.vmware.com/wp-content/uploads/sites/75/2024/12/graphical-user-interface-text-application-descr-1.png" alt="Graphical user interface, text, application Description automatically generated" /> |
We proceed by choosing the NVIDIA A100 GPU option here. This takes us to a dialog where we supply more details on the vGPU setup that VMs of this VMclass will have associated with them.
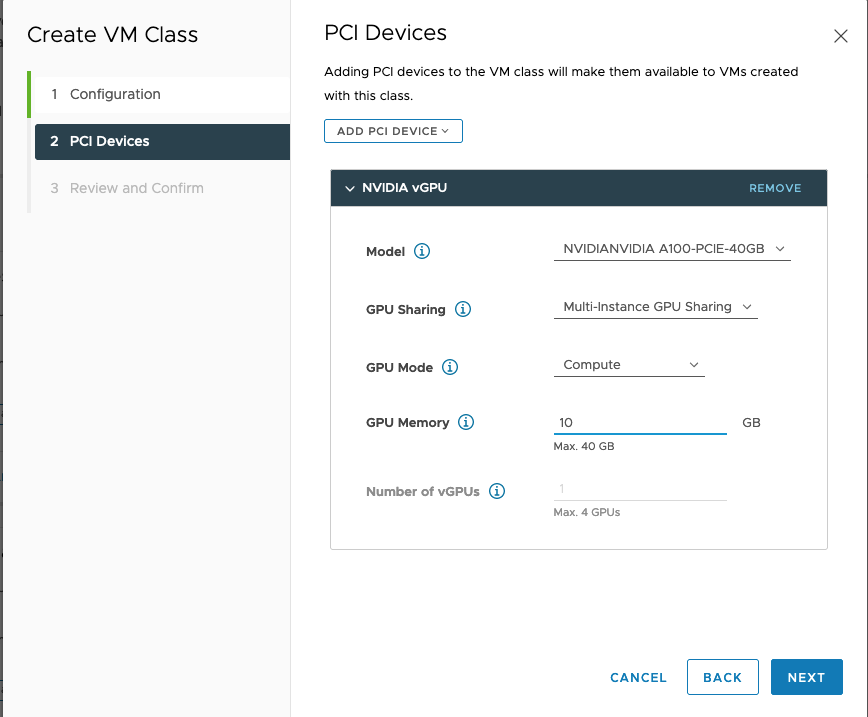
There are some important features of a vGPU being described here. Firstly, the model of GPU hardware that backs up this vGPU is seen at the top.
The type of vGPU Sharing is either “Time-sliced” or “Multi-instance GPU Sharing”. These are alternate backing mechanisms, built by NVIDIA, for a vGPU that determine how that vGPU will share the physical GPU exactly. “Time-sliced” does not provide physical separation of the GPU cores between one VM that is sharing the GPU with another. Time-sliced depends on GPU memory segmentation but not core segmentation. On the other hand, the “Multi-instance GPU” type of vGPU backing enables strict hardware-level separation )of cores, memory, cache, etc.,) between one VM that is sharing a physical GPU and another. Isolation of these hardware-level items is good for giving predictable performance on each VM that is sharing the GPU. More technical detail on these options can be found at this site.
You will also see in the screen above that we chose “Compute” for the GPU Mode, indicating that we want the compute-intensive rather than graphics-intensive mode for the new vGPU. “Compute” here is designed to optimize performance of the GPU for the frequent Machine Learning mathematical calculations, such as matrix multiply and accumulate.
Importantly, we can decide how much of the GPU’s own framebuffer memory is assigned to the VM in the GPU Memory entry on this screen. This determines how large a portion of the total GPU memory is given to any VM of this VMclass.
In vSphere 7, it is only if we choose “time-sliced” for “vGPU Sharing” and we allocate ALL of the physical framebuffer memory on a GPU to one VM would the option for multiple vGPUs of that type be allowed. This is the last entry on the screen shown above. It would allow a VM to make use of multiple full physical GPUs, if that were needed. The larger machine learning models, such as LLMs, may require multiple GPUs to support them at inference time. As we can see here, that option is not available to us when we are in Multi-Instance GPU mode or when we use up less than the full GPU’s physical memory.
Click “Next” to complete the details of this new VMclass.
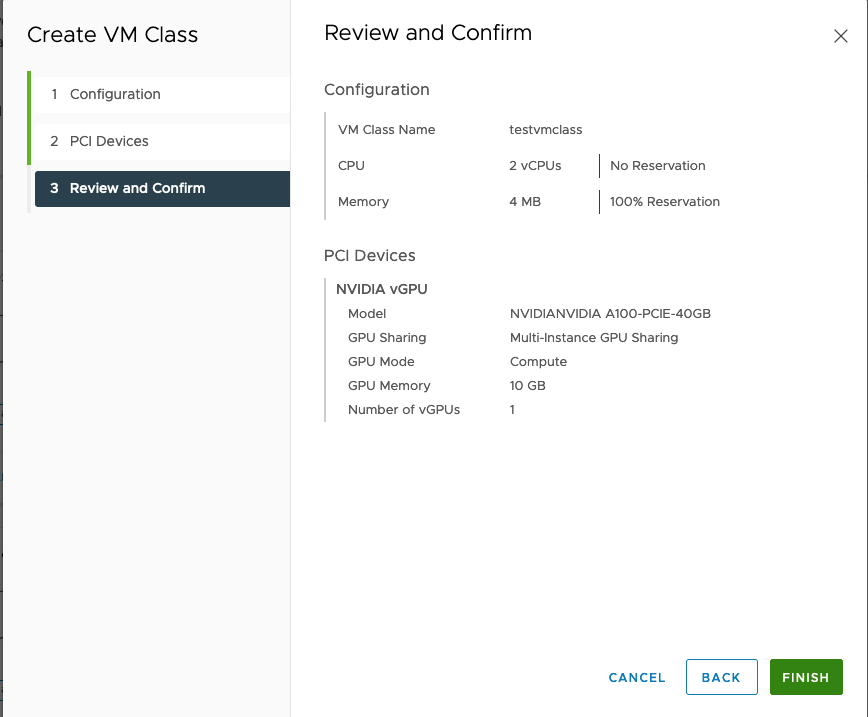
We review the details here, confirm that all is in order and click “Finish” to complete the creation of the new VMclass. Once the process has completed, we see the new VMclass in the collection of VM classes that are available.
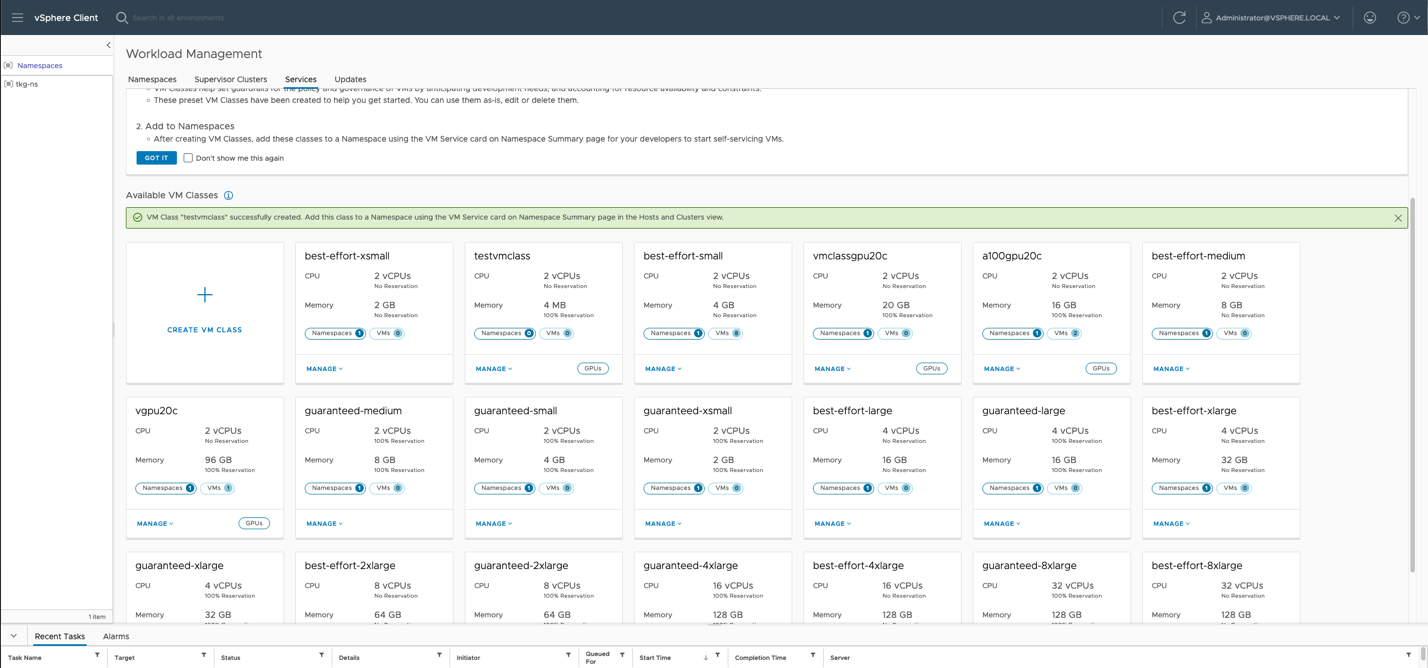
There are just a few more steps to take before we are ready to use the VMclass in a TKC specification YAML file. When we create a new VMclass, it is initially not associated with any namespace, as you see in the tile for the “testvmclass” above.
We must first ensure that the new VM class is associated with a namespace. We can use the namespace that we installed when we set up Tanzu initially or a new namespace that is created at the Supervisor level. In our example here, that namespace is called “tkg-ns”. To do this, we choose “Namespaces” from the top-level menu and then choose “Summary” to see the tiles that come with a namespace, as seen here.
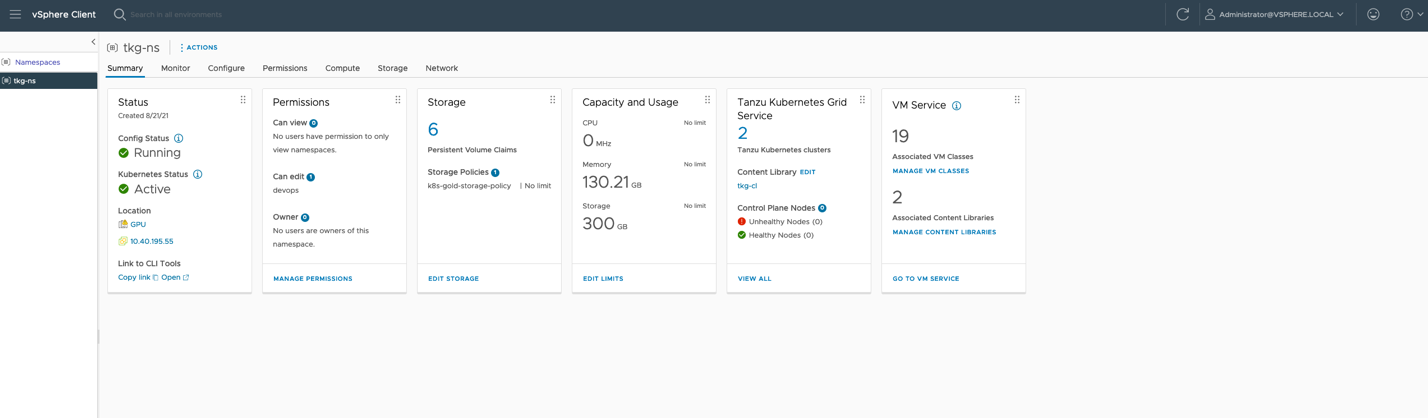
Choose “Manage VM classes” in the VM Service tile above. This shows all the VM classes that are already associated with this tkg-ns namespace. Our new “testvmclass” is not yet associated with the namespace, as you see here.
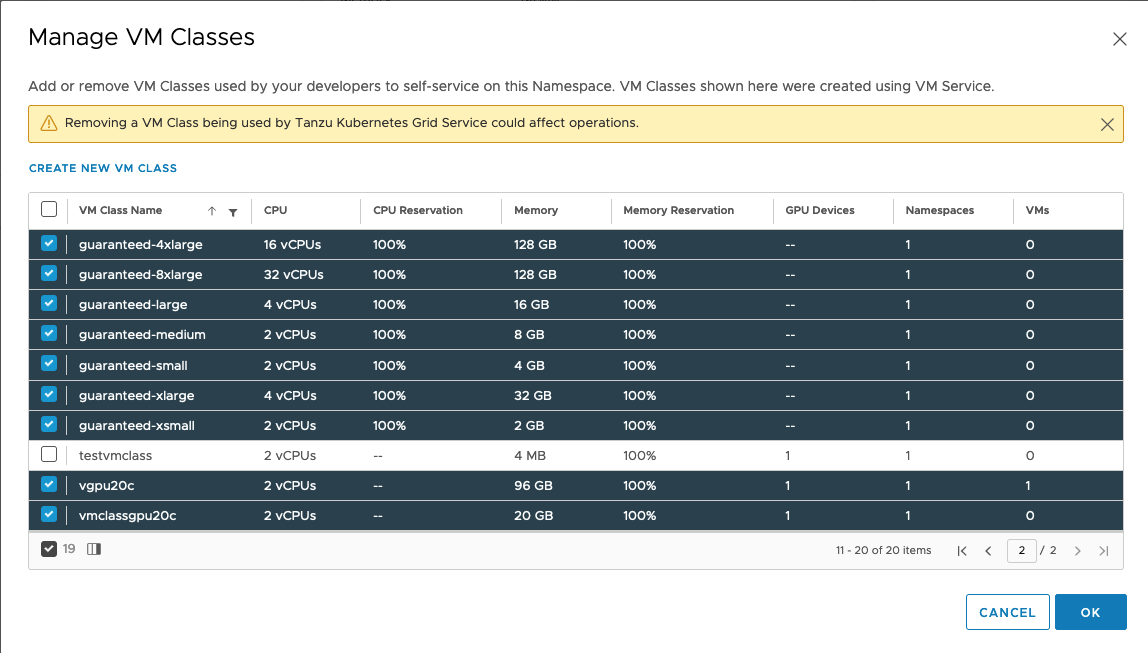
We click on the checkbox adjacent to our “testvmclass” entry and hit “OK”. The VMclass is added to the namespace – and so in the Summary screen, we see that the number of “Associated Classes” has increased to 20.
Our last setup step is to ensure that a suitable VM image (OVA) is available for creation of the VMs that will take their structure from the new VM class. This VM image is loaded into a vSphere Content Library. We see the names of the associated content libraries by clicking on “Manage Content Libraries” in the VM Service tile.
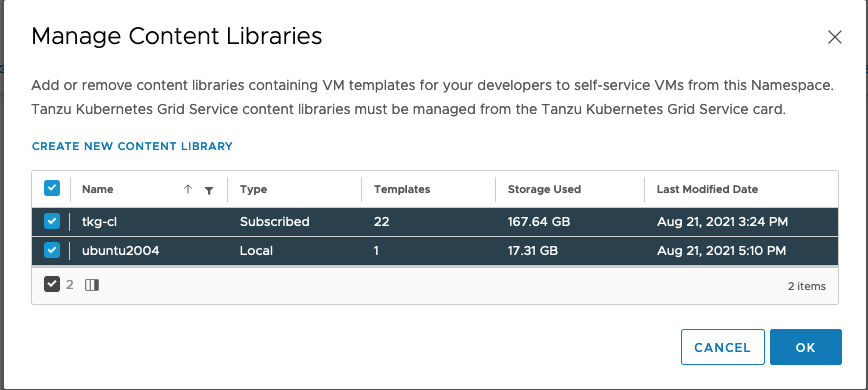
Earlier, we created a new content library in vSphere named “uUbuntu2004” to store an OVA image that has been tailored to be ready for adding a vGPU profile to it. Loading an image into a content library is done by means of the “Import” functionality in vSphere content libraries. Here is what that looks like, once imported.
From the vSphere Client main navigation options, choose “Content Libraries”, click on the name of your user-created content library and you will see your imported OVA image there.

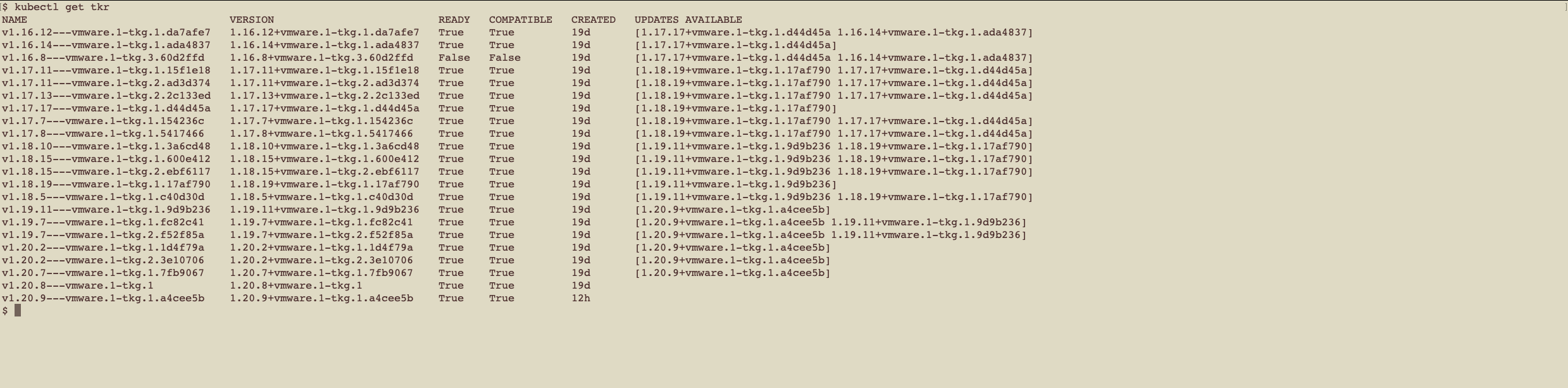
vSphere with Tanzu understands the creation of this VM image and registers it such that it can be seen using a “kubectl get tkr” command – where “tkr” stands for Tanzu Kubernetes Release. The VM image is referred to in our YAML for TKG cluster creation using just its version number as shown below. In our example deployment YAML, we used version “1.20.8+vmware.1-tkg.1” that is seen second from last in this list.
Finally, with suitable access to the tkg-ns namespace allowed, the devops or developer can create their TKG cluster as seen in our first picture using the YAML specification below. You will see that the VMclass is used in the description of one category of Worker nodes – the ones that use the GPU. A second category of Worker nodes does not need GPUs and so does not participate in that class.
This TKG Cluster is deployed by the user, using a command “kubectl apply -f tkc1.yaml” where the contents of the tkc1.yaml file are shown below. Now, you are ready to deploy further pods and applications into this cluster. The TKG cluster can be expanded with further worker nodes that have vGPUs, as applicable, simply by editing the number of replicas in the “workers” Node Pool and re-applying the YAML specification, using the kubectl apply command again.
apiVersion: run.tanzu.vmware.com/v1alpha2
kind: TanzuKubernetesCluster
metadata:
name: tkc-1
namespace: tkg-ns
spec:
distribution:
fullVersion: v1.20.8+vmware.1-tkg.1
topology:
controlPlane:
replicas: 3
storageClass: k8s-gold-storage-policy
tkr:
reference:
name: v1.20.8—vmware.1-tkg.1
vmClass: best-effort-small
nodePools:
– name: workers
replicas: 1
storageClass: k8s-gold-storage-policy
tkr:
reference:
name: v1.20.8—vmware.1-tkg.1
vmClass: testvmclass
volumes:
– capacity:
storage: 50Gi
mountPath: /var/lib/containerd
name: containerd
– capacity:
storage: 50Gi
mountPath: /var/lib/kubelet
name: kubelet
– name: worker2
replicas: 1
storageClass: k8s-gold-storage-policy
vmClass: best-effort-small
Summary
We explore the ease with which a vSphere system administrator can create a Kubernetes namespace for resource management, design a VM class providing a pattern for GPU-aware VMs and provide access to these objects to data scientists/developers who want to build their own TKG clusters (TKCs) within their allocated namespaces. This gives the data scientist/developer the freedom to create the Kubernetes clusters they need, when they need them – whether that be for ML model training, testing or inference using their models. These end users can supply the clusters with the appropriate number of GPUs as they see fit. This removes the need for ticketing systems for such operations, once a library of suitable VM classes are created and supplied to the data scientist user. On vSphere, these different user communities (administrators, devops, data scientists) can now collaborate in an elegant way to accelerate the production of machine learning models that enhance the business and save costs.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.





