

A vSAN stretched cluster is an architecture that provides resilience of data in the event of a site-level outage. This capability doesn’t use any special hardware, is easy to implement, and uses software you already know. But what about performance? Spreading out the data across a geographic distance will impact performance as data must be written in a resilient way. But how much of an impact? And what is the best way to mitigate if site-level resilience and performance are equally important?
Let’s sort through this conundrum.
Relationship of Performance to Hardware, Configuration, and Topology
vSAN is highly customizable, and as a result, several user-adjustable variables can influence performance. Hardware-based decisions include the size and type of write buffer in the disk groups, the number of disk groups per host, the type of capacity devices used at the capacity tier, and the capabilities of the network. vSAN settings influencing performance include the level of failure to tolerate and data placement scheme used, and cluster-wide data services enabled. A more complete understanding of influencing factors can be found in the Discovery/Review – Environment section of the Troubleshooting vSAN Performance guide.
For a vSAN stretched cluster, all the factors above still apply, but additional variables are introduced, including the Intersite link (ISL) and secondary or local levels of resilience assigned. The ISL is used by the cluster to transmit read and write I/Os as necessary. Whether it be a cloned write operations from a VM to the remote site or resynchronization traffic to maintain policy compliance, the ISL is the conduit for data payload between the two sites. The performance capabilities of the ISL are defined by two traits: The latency, which is partially a result of the physical distance between two sites, and the throughput of the connection. The latency incurred by ISL is additive to the latency seen in the rest of the hardware stack at each site.

Figure 1. The role of the ISL in the latency of the guest VM.
While the ISL is often the primary bottleneck of a stretched cluster, this should not imply an absence of other significant contributors to performance outcomes. Let us look at how this can happen.
Storage policies in a stretched cluster define how objects will be protected. Site-level resilience, known in the UI as “Site disaster tolerance” provides availability in the event of a full site outage when it is set to “Dual site mirroring (stretched cluster).” For stretched clusters, an optional, secondary or local level of resilience, known in the UI as “Failures to tolerate” will store data redundantly at each site in the event of smaller failures within a site, without needing to fetch the data from the other site.
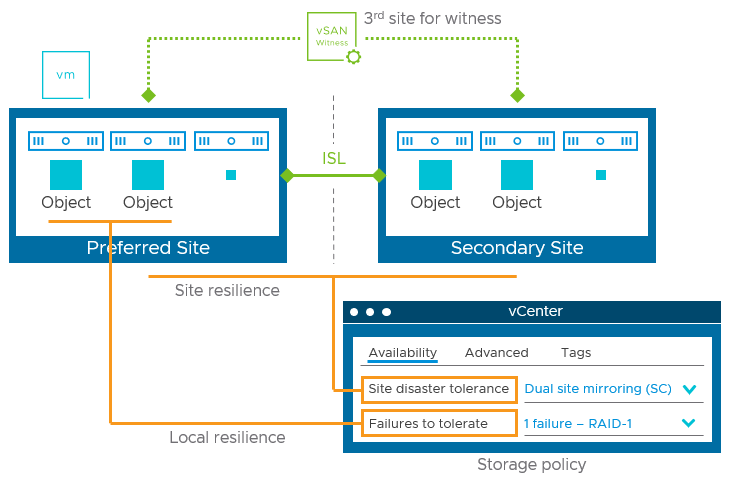
Figure 2. Relationship of storage policy rules in a stretched cluster.
vSAN achieves this synchronous secondary level of resilience efficiently. On the site opposite of the object owner, a “proxy owner” receives a cloned write through the ISL, from the object owner, and then proceed with the I/O activity to the respective hosts. This prevents the amplification of I/Os across the ISL when a secondary level of resilience is configured – be it RAID-1 based mirroring, or RAID-5/6 erasure coding.

Figure 3. Proxy owner reducing I/Os across the ISL for an object stored using local resilience.
This makes for an efficient delivery of I/Os across the ISL but does not eliminate the challenges of synchronous I/O in a stretched cluster. For example, imagine the objects of a VM are protected by site-level resilience, and a secondary level of resilience of FTT=1 using RAID-5. A RAID-5 erasure code typically amplifies a single write operation into 4 I/Os, but since this occurs on each site, a single write operation will be a total of 8 I/Os. Since vSAN emphasizes data consistency in its architecture, it must wait for all the I/O operations of the participating hosts on both sites to complete before the write acknowledgment can be sent back to the VM. When the secondary level of resilience is set in a storage policy, a stretched cluster doubles the number of hosts participating in a write operation before it can send a write acknowledgement back to the VM. If all hosts participating in the storage of the VM respond quickly, but one host does not, then the effective latency will only be as good as the slowest response time of the hosts, in addition to the response time of the ISL.

Figure 4. Poor response time from a single host affecting the write latency of a VM.
The scenario described above can occur in environments where the ISL may be sufficiently sized for fast and consistent performance, but the hosts are not. An example might include hosts that use value-based, lower-performing devices at the buffer tier, as they are poor at delivering performance consistently compared to higher-end offerings. But the same thing can occur with poor host NICs or network switches at each site. For stretched clusters with a good ISL, the poor or inconsistent performance of one discrete element of the hardware stack may impact the overall performance as seen by the VM.
Understanding the Source of the Latency
Latency measurements only quantify the amount of time a VM is waiting. The experiment below will help you better understand the sources contributing to the latency of a VM in a stretched cluster.
- Choose a VM that is using site-level resilience and note the current storage policy rules assigned to it, as well as the VM group it is associated in the DRS settings.
- For that same VM, observe the range of effective latency as seen by the guest VM in the vSAN performance service in the vCenter Server. Viewing a 24-hour window of time will be a good sampling.
- Create a new storage policy. For site disaster tolerance, instead of “Dual Site Mirroring…” select “None – keep data on Preferred” (or non-preferred). The one you choose should match the site of the VM group noted in step #1. This will help keep the data and the VM instance on the same site. For the “Failures to Tolerate” setting, set this equal to the original policy noted in step #1.
- Apply the new policy and wait for the policy to gain compliance.
- Observe the range of effective latency for the VM as described in step #2 for the next 24 hour period.
- Compare the results to determine how much of an impact the ISL is having. If you are still observing higher than anticipated latency, then you know that the source of the performance issue is somewhere else in the stack.
- Change the VM back to the original settings to ensure your desired resilience.
There is no need to convert or change the cluster in any way and is a fine example of storage policy-based management in action.
Recommendations for Performance focused vSAN stretched clusters
When performance is a priority in a stretched cluster environment, follow these recommendations.
- Use only NVMe devices at the buffer tier. NAND flash or Optane-based NVMe devices remove the challenges associated with other storage device types and can drive better performance with more consistency to the guest VMs. Do not use SATA at the cache tier, and only use it at the capacity tier when it you know it can support the steady state demands of the cluster.
- Ensure sufficient, properly configured network switches at each site. Poor network gear at each site can undermine investments in a quality ISL and vSAN hosts. Insufficient hardware on just one side of a stretched cluster will degrade performance for all VMs using resources at both sites.
- Know your ISL Round Trip Time (RTT) between sites. The RTT is typically the doubling of time of advertised latency of the ISL. The lower the RTT, the lower latency your VMs may see. The Skyline Health checks has a “Network Latency Check” that will show an alert when a stretched cluster exceeds the maximum threshold of 5ms.
- Minimize cluster-based data services. Refrain from data services that create more effort in the data path, including encryption offerings, as well as deduplication and compression. If you still would like to use some space efficiency, use the compression-only feature instead of deduplication and compression. While these processes occur only during the destaging of data, deduplication and compression, in particular, can eventually impact guest VM performance if steady-state activity is high enough.
- Minimize object-based space efficiency techniques. Apply storage policies that use simple RAID-1 mirroring for secondary levels of resilience in each site. This requires less computational effort to achieve and reduces the number of hosts that the source must wait on for a write acknowledgment. Since data is already protected across sites, a local FTT=1 may be sufficient for most scenarios.
- Verify the proper configuration of DRS Affinity groups for hosts and VMs. DRS affinity groups for hosts and VMs ensures that the VM instance is running in the site desired. This is especially important for VMs not using site-level resilience – ensuring that the VM and the data reside on the same site.
- Reduce ISL strain through storage policies. Know your ISL bandwidth limit, and if the ISL regularly hits the throughput limits. If this occurs, review which VMs need site-level resilience, then assign those VMs with storage policies to reflect the appropriate site affinity.
- Consider a multiple-stretched cluster design. A stretched cluster with fewer hosts that has been optimized with hardware and settings for performance may be an alternative to a single larger cluster that is trying to cover a wider variety of requirements. See “vSAN Cluster Design – Large Clusters versus Small Clusters” for more information.
- Use common VM virtual hardware settings used to improve performance. Using multiple VMDKs when appropriate (e.g. SQL servers, etc.) with each VMDK using their own paravirtual SCSI controllers will help reduce I/Os queuing higher up in the stack. For more information on application optimization, see this section of the Troubleshooting vSAN Performance guide.
- Consider application-level replication if your critical application supports it. Some applications like Microsoft Active Directory have built-in replication capabilities, while other applications like SQL Server have optional application-level replication through SQL Availability groups. When used, these VMs could use site affinity policies and rely entirely on multiple instances of the application for resilience.
Summary
Stretched clusters are a wonderful way to ensure the availability of applications, data, and services beyond a site, but they introduce additional performance considerations. For stretched clusters, the ISL may be one of the most important aspects of the performance, but it is not the ONLY aspect. Hardware specifications, cluster data services, and other aspects of the topology can have a significant impact on performance.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




