

VMware vSphere has three main methods of setting up GPUs for use in VMs. This article helps you navigate through those methods. It outlines the pros and cons of using each approach so that you can judge how to proceed to best serve the needs of your machine learning user community .
The detailed descriptions and setup steps for the methods given below are given in the blog article series here and several other very useful technical articles on the subject of GPU deployment for ML and HPC are located here
As a systems administrator, you are faced with a choice of different methods for GPU usage with varying trade-offs. We understand that in some organizations, the company alignment with a vendor may pre-determine that choice.
This article goes further and gives you some more advice on navigating this choice based on our experiences with vSphere customer scenarios.
1. The DirectPath I/O Approach (Passthrough)
This method is really the “minimal intervention” path for working with GPUs on virtual machines on vSphere. The detailed steps for the DirectPath I/O method are given here
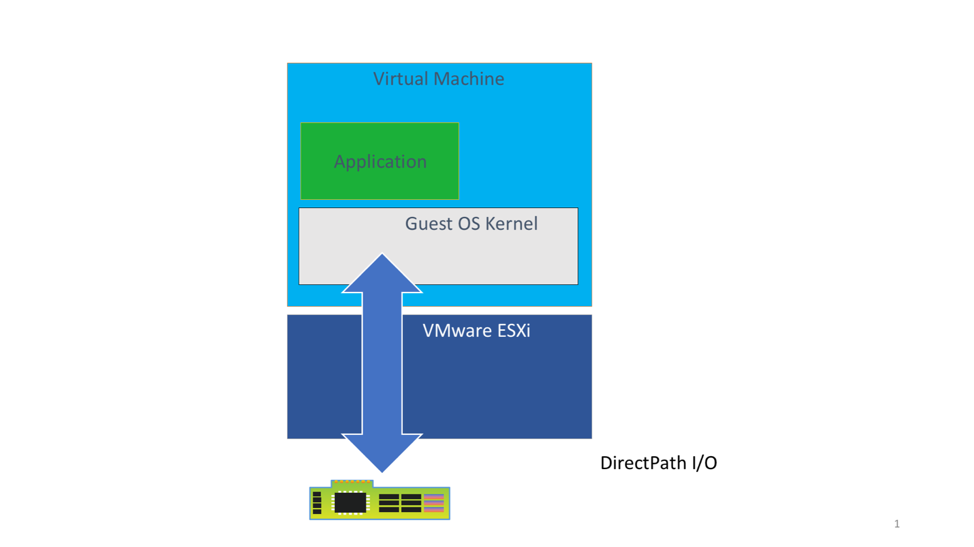
DirectPath I/O – What Types of ML use-cases is this for?
- Machine Learning training users that need one full physical GPU or multiple physical GPUs assigned fully to a single VM for a period of time. Some data scientists’ projects may require as many as 4 to 8 GPU devices all to themselves – that can be done here. Consider this to be an advanced use case of GPUs
- The DirectPath I/O method applies for the data scientist who wants one or more GPUs exclusively assigned to them for the full duration of their project. In many cases, the reason for this is that their machine learning models and data can consume all the memory of the allocated GPUs and perhaps also all of the cores it supplies.
- This provides the highest level of performance, comparable to that of native GPUs.
- These will typically be long-running model training jobs.
- DirectPath I/O can be used with all PCIe-compatible devices, such as GPUs, FPGAs and ASICs
- No sharing of physical GPUs is required here.
- DirectPath I/O may also be used as a starter test environment to get a team into the GPU area.
- The DirectPath I/O method is often used in High Performance Computing scenarios, such as in simulation or scientific workloads that are highly compute-intensive.
Advantages of the DirectPath I/O Method
- DirectPath I/O is native to all versions of vSphere. The vendor’s GPU driver is required at the Guest OS level.
- Easy to get started, it is just a few steps in vSphere Client tool to get this going,
- You can have 1 or many GPUs assigned to one VM or one data science user.
- The user has exclusive access to the GPU’s memory and cores. There is no sharing of GPU memory or cores, so no interference from other users outside of your own VM.
- DRS in vSphere 7 can be used with its Assignable Hardware feature to place your VM on a suitable host server
- DirectPath I/O has been shown to give application performance that is within a few percentage points of the native performance of the same application on the same physical GPU. This places it as the highest performing method of using GPUs on vSphere. This performance comparison work is described in this article
Disadvantages of the DirectPath I/O Method
- A VM using DirectPath I/O is tied to the host server it is created on and cannot be moved once it placed on that host. There is no vMotion allowed.
- Limited use of DRS for this reason – initial placement of the VM onto a server (with the vSphere Assignable Hardware feature)
- No fractional use of a GPU
- No snapshots of the VM are allowed
- Sharing of a single physical GPU among different VMs is not allowed.
- GPU power may be under-utilized at quiet times or when other activities are taking the data scientist’s/end-user’s attention. Not all ML jobs need the full power or memory capacity of a GPU.
2. The NVIDIA vGPU Software Approach
Using the NVIDIA vGPU method for ML and compute-intensive workloads means using the NVIDIA vCompute Server product within the vGPU family of products. Implementing this method involves installing a special driver (the vGPU Manager) into the ESXi kernel, using the “vibinstall” tool, and installing a separate NVIDIA GPU driver into the guest OS of each virtual machine that will be using a vGPU profile. The GPU appears as a virtual object, or vGPU, to the VM through choosing a vGPU profile at VM configuration time. There is a choice of different vGPU profiles for each physical GPU. Users therefore have a similar abstraction to the vCPU one in vSphere, but now applied to GPUs – both are managed through vSphere and vCenter.
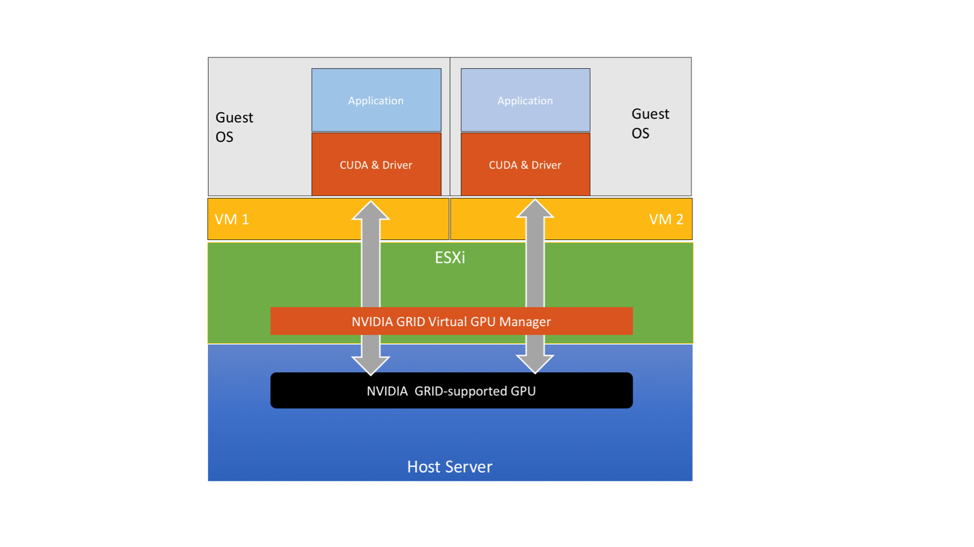
More details on the setup process for NVIDIA vGPU are here.
What Types of ML Use-Cases is this for?
- Systems administrators want the ability to live migrate/vMotion a VM that has a GPU associated with it from one physical host to another, without interrupting the work of the GPU. This is useful if some maintenance work is scheduled on the underlying host server while a long training job is in progress, which we do not want to interrupt.
- Users want the ability to suspend a VM that uses part or all of a physical GPU and resume that VM later in time. This feature can optimize the use of the physical GPU underlying the vGPU software.
- Long-running model training jobs (hours/days)
- Users who want to use fractional GPUs. A part of a GPU’s frame buffer memory (one half, one quarter, etc.,) are allocated to a VM through assigning a vGPU profile to it at VM configuration time. This allows users to operate in a physical GPU sharing fashion with others on the same host server.
- Users who want multiple GPUs from the same host server in a VM for their work
- Users who are content with assigning their GPU power at VM creation time and leaving that assignment static over the lifetime of the VM;
- Users who are committed to using NVIDIA GPU management software
- Systems administrators who can install special drivers in the hypervisor itself
- Use cases where there is a preference for local use of GPUs rather than remote access over the network
- An organization that has used other NVIDIA GPU software before now – such as the vDWS software product and wants to continue in that direction.
Advantages of NVIDIA vGPU Software
- Share a single physical GPU among different users/VMs/use cases by means of a vGPU profile on the VM.
- Allocate multiple physical GPUs to one VM and thus to one job. This involves setting multiple vGPU profiles for one VM. Those profiles must occupy their GPU memory fully.
- The GPU performance can be within a few percent points (single-digits) of DirectPath I/O performance
- The vGPU management software understands NVLink-connected physical GPUs and can maintain safety of sharing across different VMs.
- Up to four full physical GPUs can be allocated to a VM through individual vGPU profiles.
- Different scheduling algorithms (best effort, fair-share, equal-share) may be used to optimize use of the physical GPU cores for different workload types and priorities. More details on this can be found here: https://docs.nvidia.com/grid/latest/grid-vgpu-user-guide/index.html
Disadvantages of NVIDIA vGPU Software
- The method for setting up a vGPU calls for a vGPU profile to be assigned to a VM in the vSphere Client interface. Once that profile is assigned, then it stays allocated to that VM for the long term. That share of the GPU’s memory is therefore dedicated to that VM. The particular vGPU profile chosen may cover all of the memory of the GPU, thereby disallowing sharing. This last point on full GPU use is also applicable to DirectPath I/O.
- When multiple GPUs are associated with a VM, they must be done so in full (i.e. the vGPU profile accounts for the full framebuffer memory of those GPUs). The maximum number of vGPUs for a VM is capped at 4.
- Partial vGPU profiles must be of equal memory size on any one host server.
- We need a separate license for the vGPU software and in particular for the vCompute Server product within that family to operate. This has some cost per physical GPU device.
- Requires host server shutdown for vGPU Manager VIB installation
- Guest OS vGPU driver must match vGPU Manager software installed with the VIB into ESXi.
It is important to note that the vGPU Guest OS driver is specific to the vGPU family and is not the same as the driver you would install in a DirectPath I/O setup.
3. The VMware vSphere Bitfusion Approach
vSphere Bitfusion allows VMs to attach to remote GPUs over the network within a datacenter. The vSphere Bitfusion technology enables VMs that do not themselves have a GPU assigned to them to use GPUs from other VMs. In that way it “virtualizes” access to GPUs. Bitfusion has a client-side and server-side part of the software.
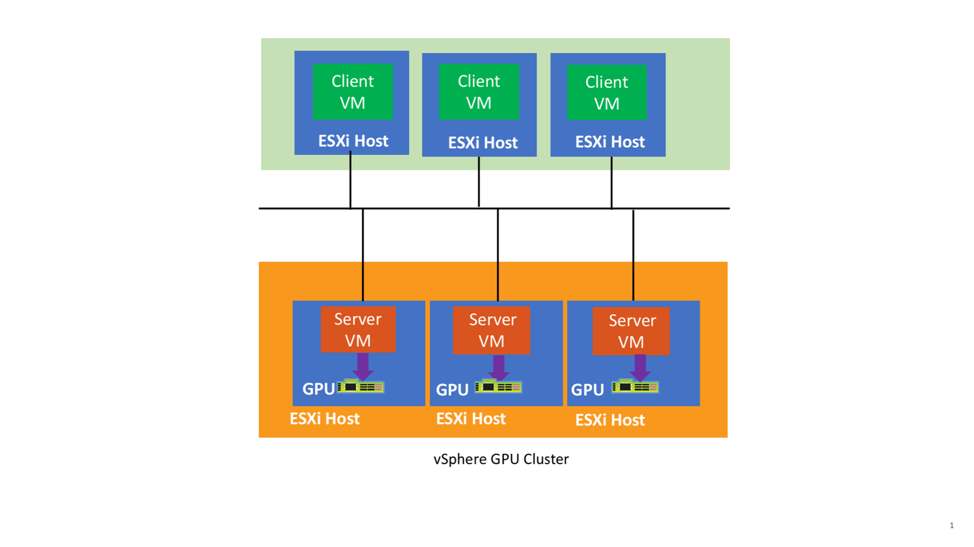
At the time of writing, the server-side of Bitfusion comes in a virtual appliance or custom VM that is shipped by VMware and then instantiated on a customer’s site. That server-side VM uses the DirectPath I/O method to access its local GPU hardware, which can be one, or multiple physical GPUs. When multiple GPUs are needed in one client request, all GPUs that serve that request must be on the same server-side host and VM.
The client-side of Bitfusion may be installed in different guest OS versions, usually Linux flavors. Both parts of the Bitfusion software operate in user space and do not themselves contain any drivers. The vendor’s GPU driver software is required on the server side as is normally the case. Parts of the CUDA stack are also required on the client side of Bitfusion.
What Types of ML Use-cases is this for?
- Organizations that want to maximize the efficiency and utilization of their GPUs across a set of users that are open to sharing GPUs. Administrators want to create a pool of GPUs for shared use among several users
- Full GPU use is also allowed, if required.
- Dynamic allocation of GPU power at application demand time – as well as optionally use static allocation of shares of a GPU, if required. Relinquish the GPU back to the pool as soon as the application no longer needs it.
- Want to use fractional GPUs of the same or different part sizes (e.g. one user gets a third and another gets two thirds of the same physical GPU memory)
- Isolate workloads into separate VMs but consolidate their GPU usage – key elements of virtualization
- The Bitfusion approach is regularly combined with the DirectPath I/O method. This is done at the Bitfusion server-side where Bitfusion has direct access to one or more GPUs on the same server. This setup provides for higher levels of utilization, efficiency and flexibility of use of pooled GPUs that can be remote in the data center.
Advantages of Bitfusion
- Provide access to GPU power across the entire data center, on demand. Allow users who don’t have GPUs on their VMs to make use of a pool of GPUs remotely over the network
- Each request for GPU power can be catered for dynamically. We do not need to allocate fixed profiles to a VM.
- Users can request multiple, partial GPUs at once to spread the load across the physical GPUs
- No manager software is needed in the hypervisor kernel. Bitfusion is available as part of the vSphere 7 Enterprise Plus license. There is still the need for the vendor’s GPU driver stack on the client and server side of the Bitfusion setup
- Can use Bitfusion tools to visualize the allocation of GPU power to their requests
- Provides the capability to consolidate multiple GPUs into a single “GPU Cluster” that can serve VMs across the datacenter
- Administrators can vMotion the client side VMs to different hosts without affecting the server-side VMs
- Bitfusion implements optimizations of the CUDA API calls that underlie the client-server model of GPU use
Disadvantages of Bitfusion
- Because the internal CUDA API calls are being re-directed over the network, users need to configure their network to minimize any latency. The speed of the network becomes a key element to the infrastructure setup
- GPUs that are linked together on a server using NVlink technology require care in their allocation to VMs.
Summary
This article provides a list of advantages and disadvantages of three styles of using GPUs for machine learning on vSphere. These enable the system administrator and the end user, i.e. the data scientist or machine learning practitioner, to discuss the latter’s needs and come up with an optimal solution on vSphere to serve those needs for machine learning applications and high-performance compute workloads in general. All three methods are in regular use by VMware’s customers for different scenarios and all undergo regular testing at VMware’s R&D labs.
Other Machine Learning and GPU-related articles from VMware are available here.
The vSphere 7 Assignable Hardware and Dynamic DirectPath I/O features are described further here.
Discover more from VMware Cloud Foundation (VCF) Blog
Subscribe to get the latest posts sent to your email.




