
A performance study is available that shows how to best deploy and configure vSphere for Big Data applications such as Hadoop and Spark. Hardware, software, and vSphere configuration parameters are documented, as well as tuning parameters for the operating system, Hadoop, and Spark.
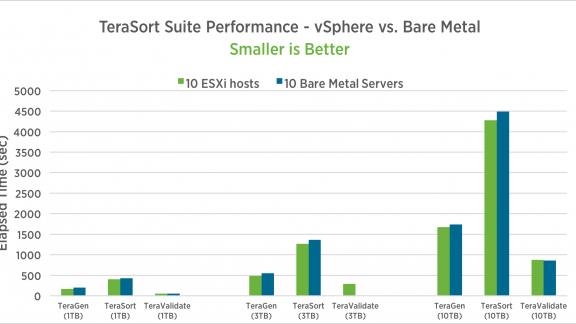
We tested the best practices on a Dell 12-server cluster, with Hadoop installed on vSphere and on bare metal. We ran, on the cluster, workloads for both Hadoop (TeraSort and TestDFSIO) and Spark (Support Vector Machines and Logistic Regression). The virtualized cluster outperformed the bare metal cluster by 5-10% for all MapReduce and Spark workloads with the exception of one Spark workload, which ran at parity. All workloads showed excellent scaling from 5 to 10 worker servers and from smaller to larger dataset sizes.
Here are the results for the TeraSort suite:

And for Spark Support Vector Machines:

Here are the best practices cited in this paper:
- Reserve about 5-6% of total server memory for ESXi; use the remainder for the virtual machines.
- Create 1 or more virtual machines per NUMA node.
- Limit the number of disks per DataNode to maximize the utilization of each disk – 4 to 6 is a good starting point.
- Use eager-zeroed thick VMDKs along with the ext4 filesystem inside the guest.
- Use the VMware Paravirtual SCSI (pvscsi) adapter for disk controllers; use all 4 virtual SCSI controllers available in vSphere 6.0.
- Use the vmxnet3 network driver; configure virtual switches with MTU=9000 for jumbo frames.
- Configure the guest operating system for Hadoop performance including enabling jumbo IP frames, reducing swappiness, and disabling transparent hugepage compaction.
- Place Hadoop controller roles, ZooKeeper, and journal nodes on 3 virtual machines for optimum performance and to enable high availability.
- Dedicate the worker nodes to run only the HDFS DataNode, YARN NodeManager, and Spark Executor roles.
- Use the Hadoop rack awareness feature to place virtual machines belonging to the same physical host in the same rack for optimized HDFS block placement.
- Run the Hive Metastore in a separate database.
- Set the Yarn cluster container memory and vcores to slightly overcommit both resources.
- Adjust the task memory and vcore requirement to optimize the number of maps and reduces for each application.
All details are in the paper, Big Data Performance on vSphere 6: Best Practices for Optimizing Virtualized Big Data Applications.