工作負載優化演示 — 實現服務等級 SLA
下面給大家看一個利用 vRealize Operations 的工作負載優化能力提供不同服務等級來保證關鍵業務應用性能的演示,建議先閱讀一下文章“vRealize Operations 自動駕駛式運維之性能優化”,有助於理解演示中所涉及的知識和概念。
在演示的環境 有兩種類型的伺服器:
- Gold (金牌):最新的高性能伺服器,提供最高等級的計算服務;
- Silver (銀牌):比較老的伺服器,性能相對差一些,提供一般等級的計算服務。
這些伺服器都被打上了 標籤類型“SLA Tiering (SLA 等級)” ,根據伺服器的類型分別打上金牌和銀牌兩種標籤。這些伺服器組成了兩個集群:
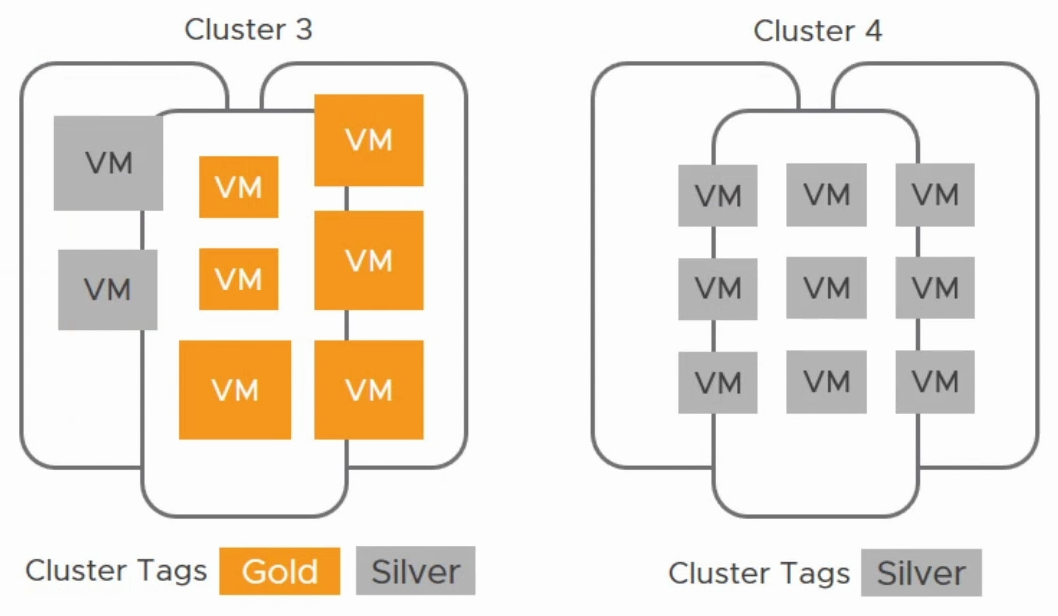
- Cluster3:兼有金牌和銀牌伺服器,“SLA Tiering” 打上了 Gold 和 Silver 兩種標籤;
- Cluster4:只有銀牌伺服器,所以打上了“SLA Tiering = Silver” 的標籤。
演示環境中的工作負載也分為兩類:
- 關鍵應用:對應於關鍵業務,要求保證應用運行性能,需要“金牌”等級的計算服務,虛機被打上 “SLA Tiering = Gold” 的標籤,在下圖中表示為橙色;
- 一般應用:對於性能的要求相對較低,只需要“銀牌”等級的計算服務即可,虛機被打上 “SLA Tiering = Silver” 的標籤,在下圖中表示為灰色。

優化前:有兩個關鍵應用虛機運行在 Cluster4 中
管理員在 vRealize Operations 中把運維意圖設置為“均衡 (Balance)”;把業務意圖 (Business Intent) 設置為分層的服務等級 (SLA Tiering),指定了 Gold 和 Silver 兩種服務等級,並且啟動了 優先考慮高等級服務開關 (Enable Prioritization)。優先考慮高等級服務意味著同時存在金牌和銀牌伺服器的情況下,調度工作負載時優先考慮高等級的伺服器,在下圖中 “SLA Tiering = Gold” 的編號是1,優先順序要高於編號為2的 “SLA Tering = Silver”。

設置好工作負載優化策略後就可以啟動優化操作,優化後原來運行在 Cluster4 中的兩個關鍵應用虛機被遷移到了 Cluster3 中,這樣它們可以享受金牌等級的計算資源,保證關鍵應用的性能。同時,原來 Cluster3 中的非關鍵應用虛機也保持不動,繼續運行在金牌等級的 Cluster3 中,因為現在的優化策略是優先考慮高等級服務,當 Cluster3 中還有空閒的計算資源時,也會允許一般的應用在其中運行,以充分利用高性能的伺服器資源。

優化後:這兩個關鍵應用虛機被遷移到了 Cluster3,在“金牌”服務等級的伺服器上運行
這是一個零售企業,雙11的時候業務量暴增,Cluster3 中的資源消耗殆盡,在下面的示意圖中可以看到某些虛機變大了 (消耗的資源變多了),從而導致某些關鍵應用的性能下降 ,甚至無法正常工作 (演示中 Nginx 因為資源競爭出現了 Bad Gateway 的錯誤),vRealize Operations 提示該資料中心需要性能優化。
管理員手動啟動優化後,Cluster3 中的部分非關鍵應用 (灰色 VM) 被遷移到到了 Cluster4,從而釋放了一部分資源給 Cluster3 中的其他應用,我們可以看到原來受阻的關鍵應用恢復了正常工作。

為了清楚地展現每一個步驟,演示中的性能優化操作都是手動啟動的,在實際環境中更多的是採用自動優化,vRealize Operations 會根據管理員設置的優化策略尋找優化機會,並且自動地進行資料中心性能優化。為了讓管理員瞭解在過去一段時間內是否有自動的優化操作發生,vRealize Operations 還提供了一個優化歷史 (History) 工具 (如下圖所示),管理員可以拖動時間軸來顯示過去一段時間內自動執行的優化操作,直觀地看到虛機遷移的過程。

演示視頻:
延伸閱讀
加速滿足業務需求是企業進行數位化轉型的驅動力,IT應該提供一個數位化的基礎架構來支撐現代企業應用的運行。VMware 和 Intel 通力協作,跨資料中心和公有雲提供一致的基礎架構和運維體驗,支持應用的快速交付運行,以滿足業務創新和市場競爭的需要,為企業構建了一條數位化轉型之路。VMware 和 Intel 的解決方案,以緊密集成的計算、網路和存儲虛擬化技術為基礎來構建軟體定義的超融合架構,基於業界的標準和 Intel 的技術來為用戶提供自動駕駛式的運維和管理體驗。這種創新方案交付了一致的運維模式,可以在任何基於 Intel 平臺的雲環境上運行任何的應用。
Comments
0 Comments have been added so far