VMware NSX, Cisco UCS and Cisco Nexus, TOGETHER solve many of the most pressing issues at the intersection of networking and virtualization.
Executive Summary
VMware NSX brings industry-leading network virtualization capabilities to Cisco UCS and Cisco Nexus infrastructures, on any hypervisor, for any application, with any cloud management platform. Adding state of the art virtual networking (VMware NSX) to best-in-class physical networking (Cisco UCS & Nexus) produces significant optimizations in these key areas:
- Provision services-rich virtual networks in seconds
- Orders of magnitude more scalability for virtualization
- The most efficient application traffic forwarding possible
- Orders of magnitude more firewall performance
- Sophisticated application-centric security policy
- More intelligent automation for network services
- Best-of-breed synergies for multi data center
- More simplified network configurations
Cisco UCS and Nexus 7000 infrastructure awesomeness
A well-engineered physical network always has been and will continue to be a very important part of the infrastructure. The Cisco Unified Computing System (UCS) is an innovative architecture that simplifies and automates the deployment of stateless servers on a converged 10GE network. Cisco UCS Manager simultaneously deploys both the server and its connection to the network through service profiles and templates; changing what was once many manual touch points across disparate platforms into one automated provisioning system. That’s why it works so well. I’m not just saying this; I’m speaking from experience.
Cisco UCS is commonly integrated with the Cisco Nexus 7000 series; a high-performance modular data center switch platform with many features highly relevant to virtualization, such as converged networking (FCoE), data center interconnect (OTV), Layer 2 fabrics (FabricPath, vPC), and location independent routing with LISP. This typically represents best-in-class data center physical networking.
With Cisco UCS and Nexus 7000 platforms laying the foundation for convergence and automation in the physical infrastructure, the focus now turns to the virtual infrastructure. VMware NSX, when deployed with Cisco UCS and Cisco Nexus, elegantly solves many of the most pressing issues at the intersection of networking and virtualization. VMware NSX represents the state of the art for virtual networking.
1) Virtualization-centric operational model for networking
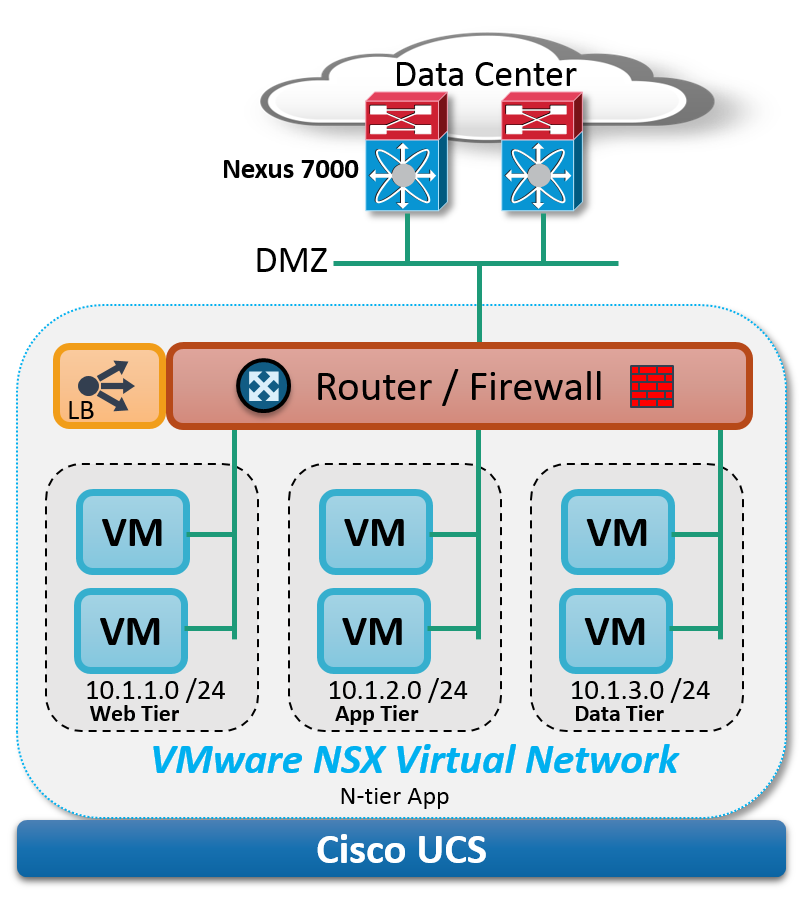 VMware NSX adds network virtualization capabilities to existing Cisco UCS and Cisco Nexus 7000-based infrastructures, through the abstraction of the virtual network, complete with services such as logical switching, routing, load balancing, security, and more. Virtual networks are deployed programmatically with a similar speed and operational model as the virtual machine — create, start, stop, template, clone, snapshot, introspect, delete, etc. in seconds.
VMware NSX adds network virtualization capabilities to existing Cisco UCS and Cisco Nexus 7000-based infrastructures, through the abstraction of the virtual network, complete with services such as logical switching, routing, load balancing, security, and more. Virtual networks are deployed programmatically with a similar speed and operational model as the virtual machine — create, start, stop, template, clone, snapshot, introspect, delete, etc. in seconds.
The virtual network allows the application architecture (including the virtual network and virtual compute) to be deployed together from policy-based templates, consolidating what was once many manual touch points across disparate platforms into one automated provisioning system. In a nutshell, VMware NSX is to virtual servers and the virtual network what Cisco UCS is to physical servers and the physical network.
2) More headroom for virtualization, by orders of magnitude (P*V)
VMware NSX provides the capability to dynamically provision logical Layer 2 networks for application virtual machines across multiple hypervisor hosts, without any requisite VLAN or IP Multicast configuration in the Cisco UCS and Cisco Nexus 7000 infrastructure. For example, thousands of VXLAN logical Layer 2 networks can be added or removed programmatically through the NSX API, with only a few static infrastructure VLANs; compared to what was once thousands of manually provisioned VLANs across hundreds of switches and interfaces.
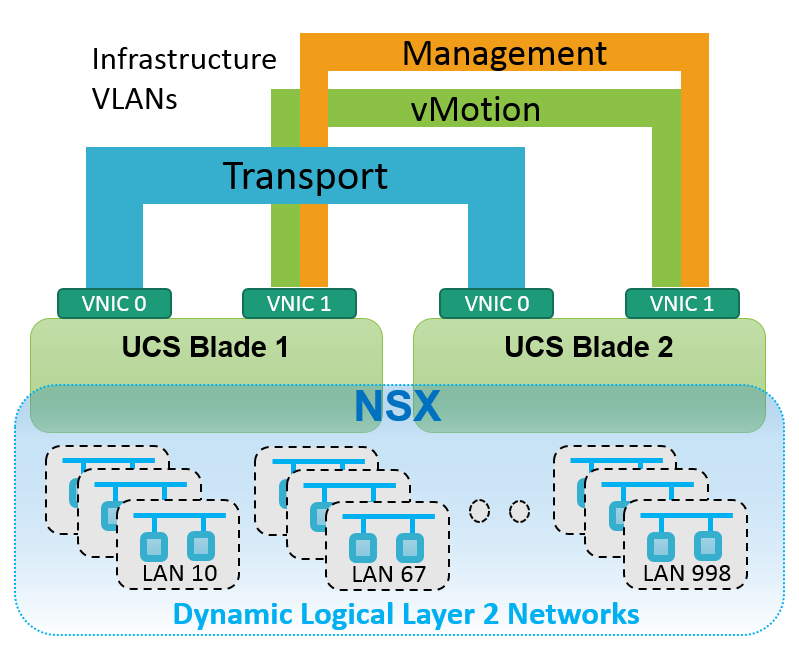
Figure: NSX dynamic logical Layer 2 networks
Two of the most common breaking points when scaling a network for virtualization are:
- Limited number of STP logical port instances the switch control plane CPUs can support, placing a ceiling on VLAN density.
- Limited MAC & IP forwarding table resources available in switch hardware, placing a ceiling on virtual machine density.
VLANs and virtual machines; two things you don’t want a visible ceiling on. Fortunately, VMware NSX provides significant headroom for both, by orders of magnitude, for the simple reason that VLAN and STP instances are dramatically reduced; and hardware forwarding tables are utilized much more efficiently.
Consider (P1 * V1) = T. Switch ports * number of active VLANs = STP logical ports.
One thousand fewer infrastructure VLANs with VMware NSX translates into one thousand times fewer STP logical port instances loading the Cisco UCS and Nexus 7000 control plane CPUs. This can only help ongoing operational stability, along with the obvious scaling headroom.
Consider (P2 * V2) = D. Physical hosts * VMs per host equals virtual machine density.
Normally, the size of the MAC & IP forwarding tables in a switch roughly determines the ceiling of total virtual machines you can scale to (D), as each virtual machine requires one or more entries. With VMware NSX, however, virtual machines attached to logical Layer 2 networks do not consume MAC & IP forwarding table entries in the Cisco UCS and Nexus 7000 switch hardware. Only the physical hosts require entries. In other words, with VMware NSX, the ceiling is placed on the multiplier (P2), not the total (D).
Reduced VLAN sprawl and logical Layer 2 networks compound to both simplify the Cisco UCS and Nexus configurations and significantly extend the virtualization scalability and virtual life of these platforms.
3) Most efficient application traffic forwarding possible
Have you ever noticed the paradox that good virtualization is bad networking? For example, the network design that works best for virtualization (Layer 2 fabric) isn’t the best design for Layer 3 traffic forwarding, and vice versa. That is, until now.
VMware NSX provides distributed logical Layer 3 routing capabilities for the virtual network subnets at the hypervisor kernel. Each hypervisor provides the Layer 3 default gateway, ARP resolver, and first routing hop for its hosted virtual machines. The result is the most efficient forwarding possible for east-west application traffic on any existing Layer 2 fabric design, most notably Cisco UCS.
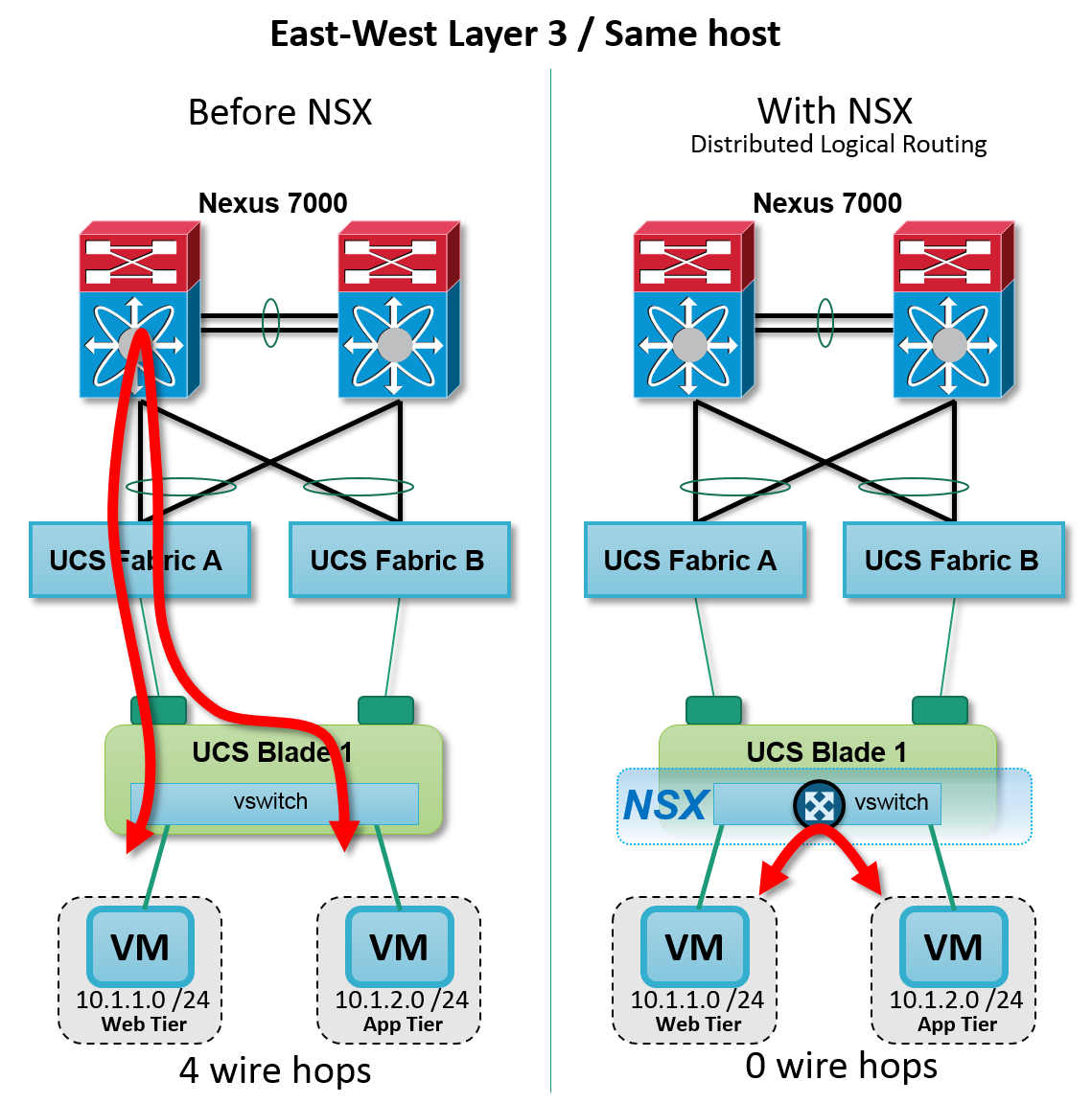
Figure: NSX Distributed Layer 3 routing — intra host
In the diagram above, VMware NSX distributed logical routing provides east-west Layer 3 forwarding directly between virtual machines on the same Cisco UCS host, without any hairpin hops to the Cisco Nexus 7000 — the most efficient path possible.
VMware NSX spans multiple Cisco UCS hosts acting as one distributed logical router at the edge. Each hypervisor provides high performance routing only for its hosted virtual machines in the kernel I/O path, without impact on system CPU. Layer 3 traffic between virtual machines travels directly from source to destination hosts inside the non-blocking Cisco UCS fabric — the most efficient path possible.
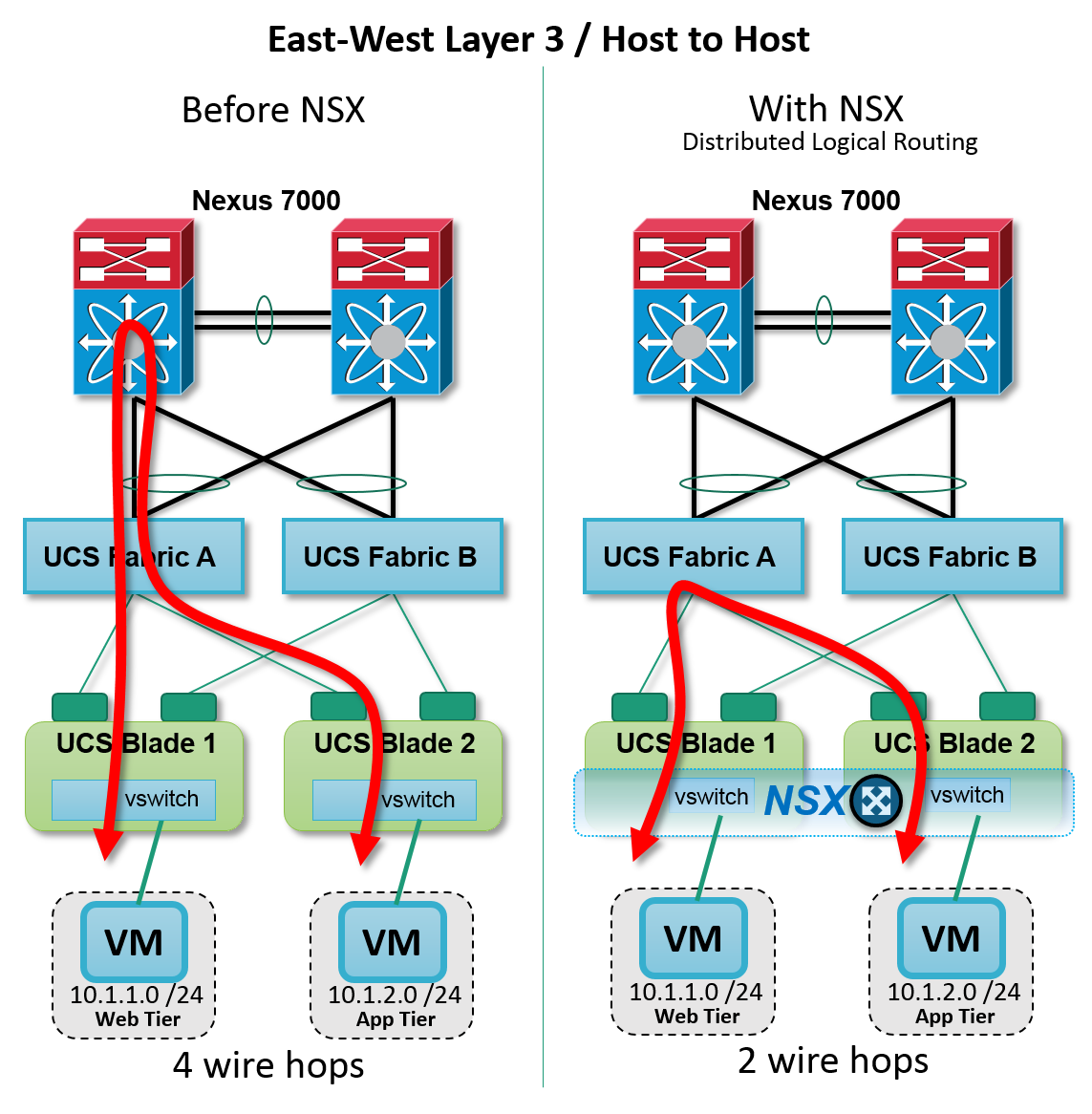
Figure: NSX Distributed Layer 3 routing — inter host
This efficient Layer 3 forwarding works with the existing Cisco UCS Layer 2 fabric, keeping more east-west application traffic within the non-blocking server ports, minimizing traffic on the fewer uplink ports facing the Cisco Nexus 7000 switches.
With Layer 3 forwarding for the virtual network handled by the hypervisors on Cisco UCS, the Cisco Nexus 7000 switch configurations are simpler; because VMware NSX distributed routing obviates the need for numerous configurations of virtual machine adjacent Layer 3 VLAN interfaces (SVIs) and their associated HSRP settings.
Note: HSRP is no longer necessary with the VMware NSX distributed router, for the simple reason that virtual machines are directly attached to one logical router that hasn’t failed until the last remaining hypervisor has failed.
The Cisco Nexus 7000 switches are also made more scalable and robust as the supervisor engine CPUs are no longer burdened with ARP and HSRP state management for numerous VLAN interfaces and virtual machines. Instead, VMware NSX decouples and distributes this function across the plethora of x86 CPUs at the edge.
4) More awesome firewall, by orders of magnitude (H*B)
Similar to the aforementioned distributed logical routing, VMware NSX for vSphere also includes a powerful distributed stateful firewall in the hypervisor kernel, which is ideal for securing east-west application traffic directly at the virtual machine network interface (inspecting every packet) with scale-out data plane performance. Each hypervisor provides transparent stateful firewall inspection for its hosted virtual machines, in the kernel, as a service – and yet all under centralized control.
The theoretical throughput of the VMware NSX distributed firewall is some calculation of (H * B). The number of Hypervisors * network Bandwidth per hypervisor. For example, 500 hypervisors each with two 10G NICs would approximate to a 20 Terabit east-west firewall.
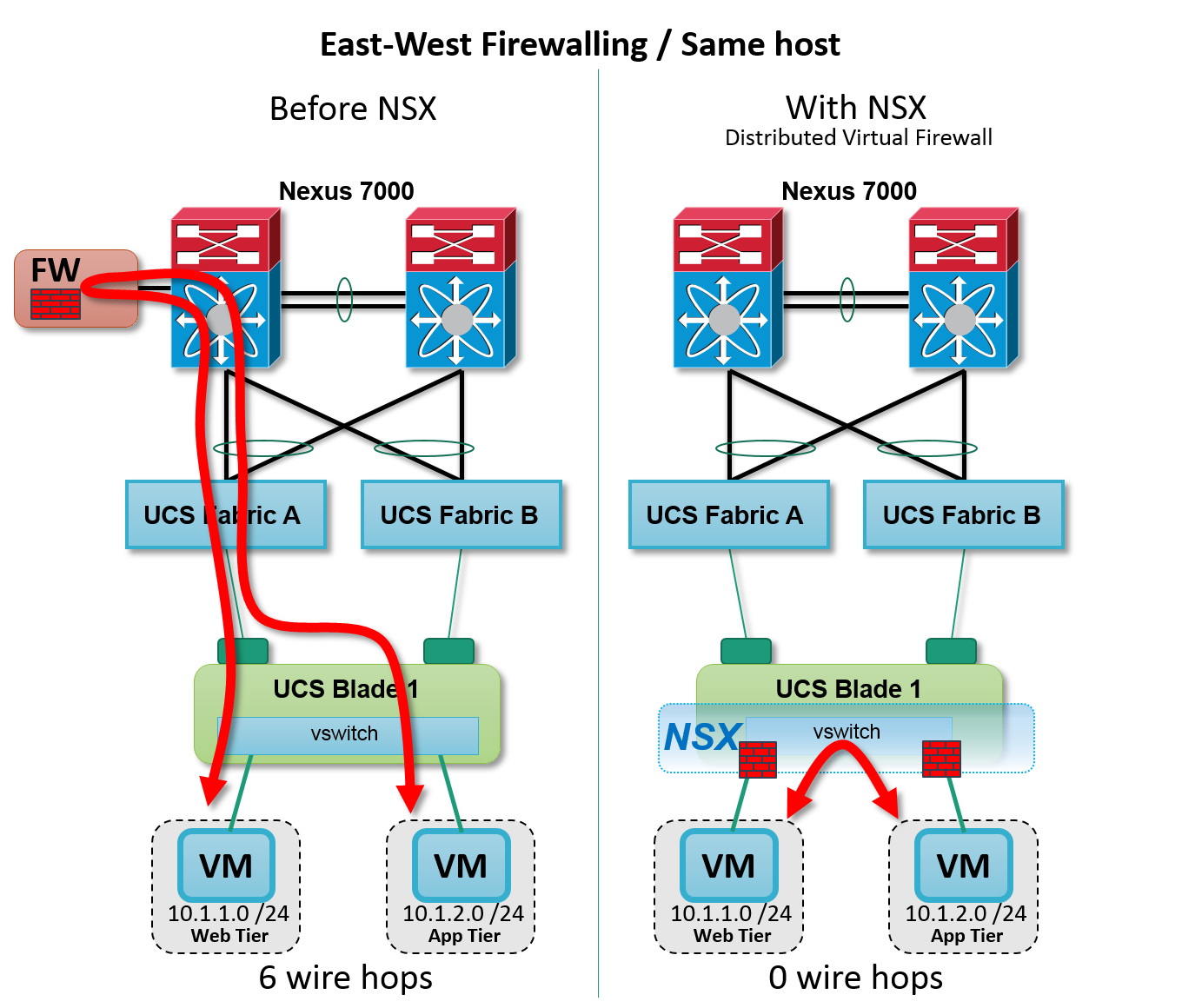
Figure: NSX Distributed Firewall — intra host
As we see in the diagram above, the distributed firewall provides stateful east-west application security directly between virtual machines on the same Cisco UCS host, without any hairpin traffic steering through a traditional firewall choke point. Zero hops. The most efficient path possible.
The VMware NSX distributed firewall spans multiple Cisco UCS hosts, like one massive firewall connected directly to every virtual machines. Each hypervisor kernel provides the stateful traffic inspection for its hosted virtual machines. In other words, traffic leaving a Cisco UCS host and hitting the fabric has already been permitted by a stateful firewall, and is therefore free to travel directly to its destination (where it’s inspected again).
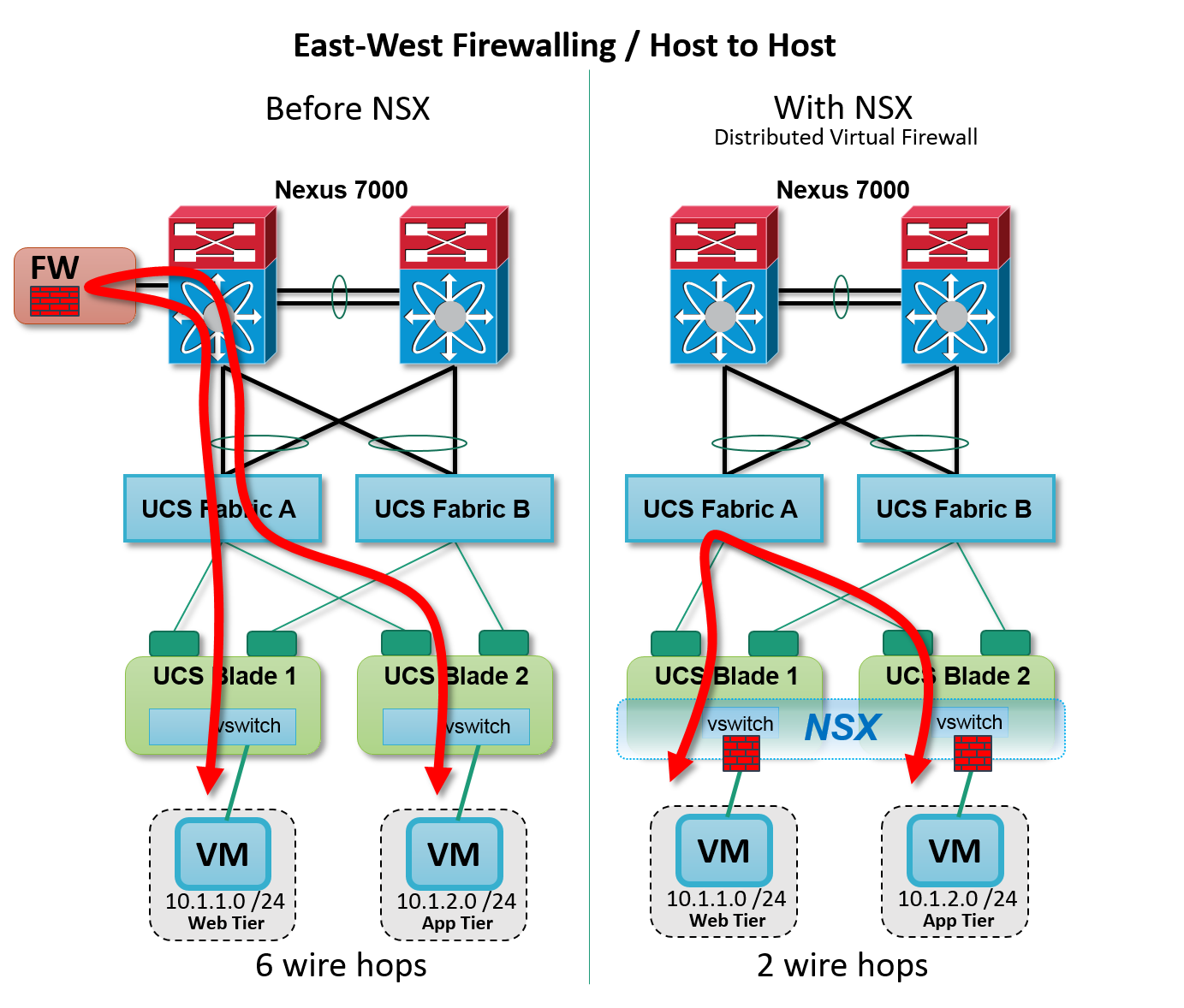
Figure: NSX Distributed Firewall — inter host
Given the VMware NSX distributed firewall is directly adjacent to the virtual machines, sophisticated security policies can be created that leverage enormous amount of application-centric metadata present in the virtual compute layer (things such as user identity, application groupings, logical objects, workload characteristics, etc.); far beyond basic IP packet header inspection.
As a simple example, a security policy might say that protocol X is permitted from the logical network “Web” to “App” — no matter the IP address. Consider a scenario where this application is moved to a different data center, with different IP address assignments for “Web” and “App” networks; and having no affect on the application’s security policy. No need to change or update firewall rules.
Finally, we can see again that more east-west application traffic stays within the low latency non-blocking Cisco UCS domain — right where we want it. This can only help application performance while freeing more ports on the Cisco Nexus 7000 previously needed for bandwidth to a physical firewall.
5) More awesome network services
One of the more pressing challenges in a virtualized data center surrounds efficient network service provisioning (firewall, load balancing) in a multi-tenant environment. Of particular importance are the services establishing the perimeter edge — the demarcation point establishing the application’s point of presence (NAT, VIP, VPN, IP routing). Typical frustrations often include:
- Limited multi-tenancy contexts on hardware appliances
- Static service placement
- Manually provisioned static routing
- Limited deployment automation
- Service resiliency
To address this, VMware NSX includes performance optimized multi-service virtual machines (NSX Edge Services), auto deployed with the NSX API into a vSphere HA & DRS edge cluster. Multi-tenancy contexts are virtually unlimited by shifting perimeter services from hardware appliances to NSX Edge virtual machines on Cisco UCS.
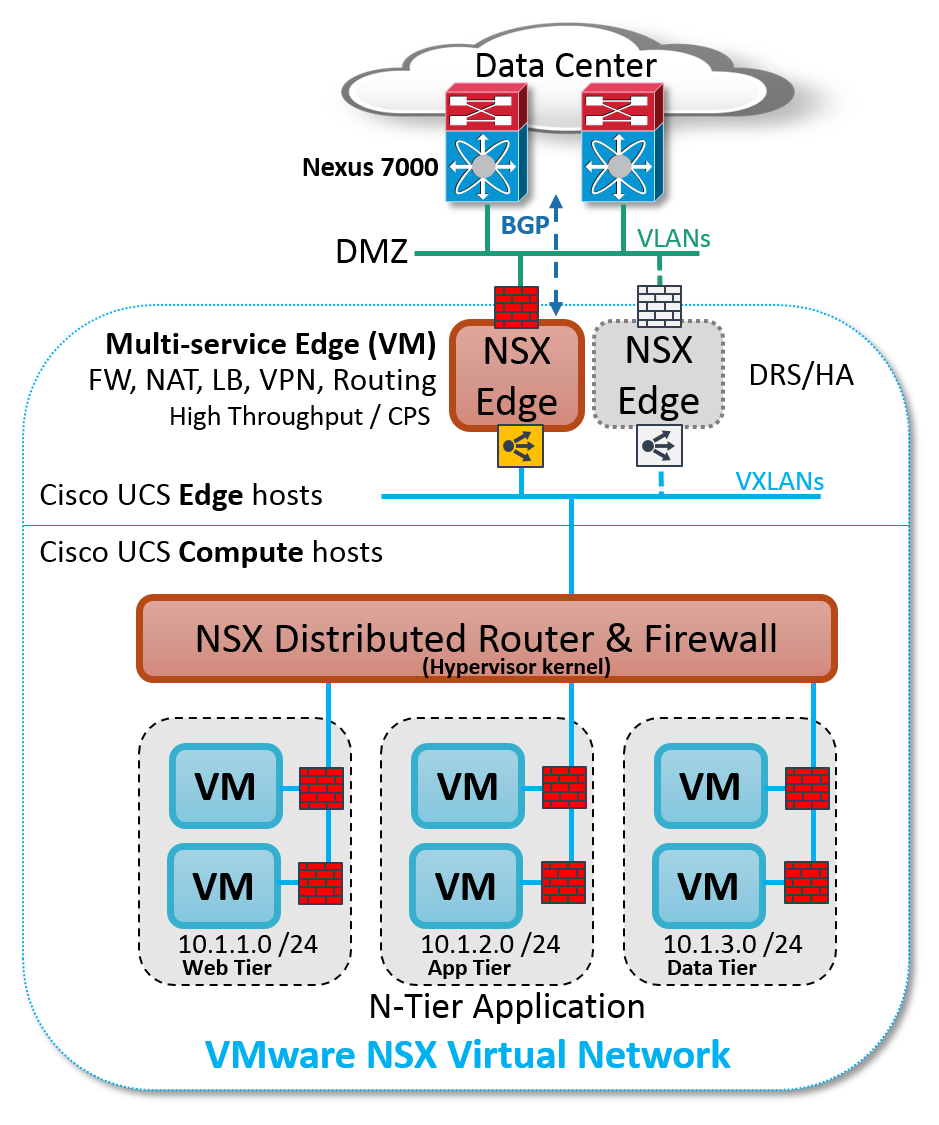
Figure: Sample VMware NSX logical topology on Cisco UCS
Dynamic IP routing protocols on the NSX Edge (BGP, OSPF, IS-IS) allow the Cisco Nexus 7000 switches to learn about new (or moved) virtual network IP prefixes automatically — doing away with stale and error prone static routes.
VMware NSX Edge instances leverage HA & DRS clustering technology to provide dynamic service placement and perpetual N+1 redundancy (auto re-birth of failed instances); while Cisco UCS stateless computing provides the simplified and expedient restoration of service capacity (re-birth of failed hosts).
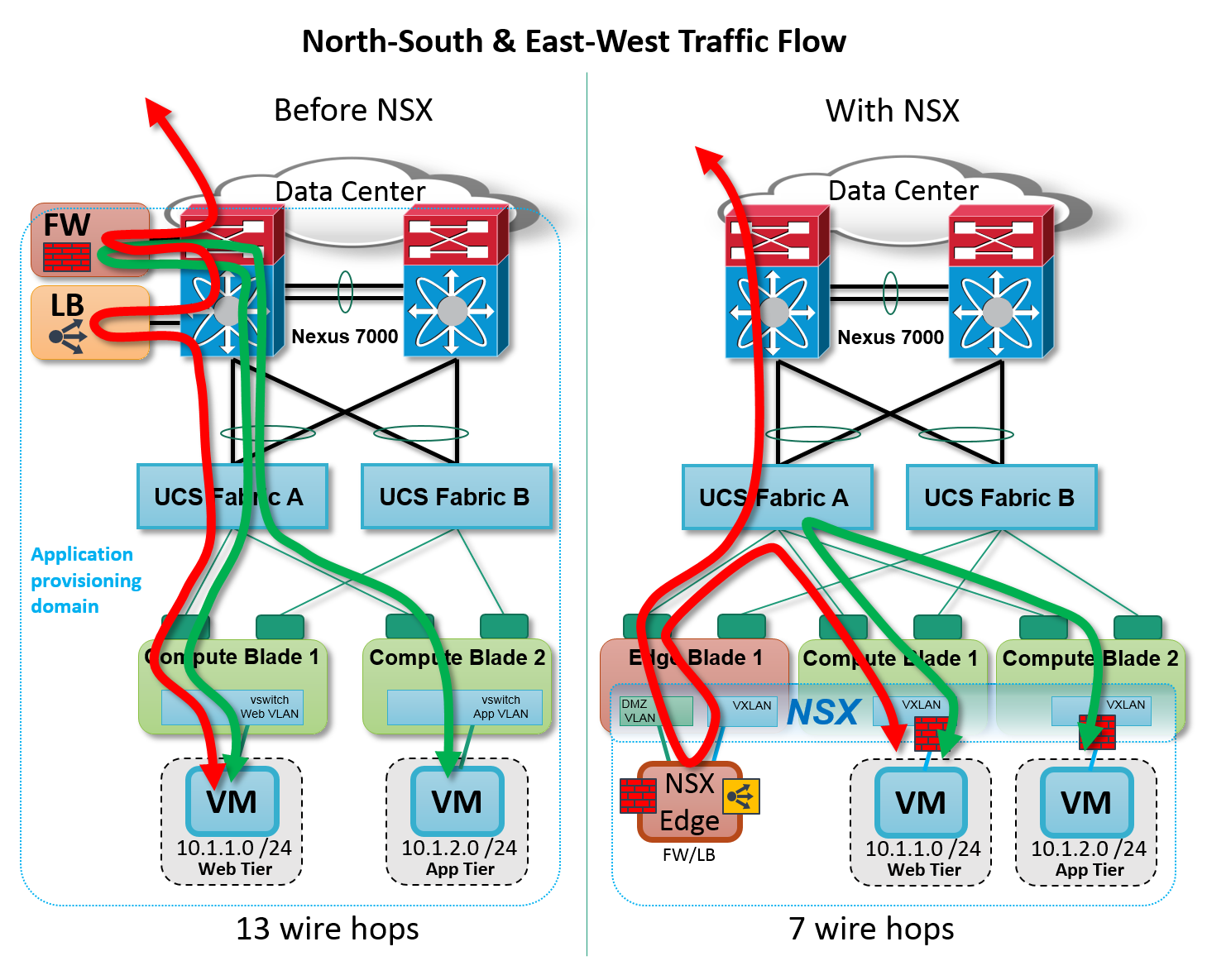
Figure: Application traffic flow. Before & After
With VMware NSX, traffic enters the Cisco UCS domain where all required network services for both north-south and east-west flows are applied using high performance servers within the non-blocking converged fabric, resulting in the most efficient application flows possible.
Note: VMware NSX is also capable of bridging virtual networks to physical through the NSX Edge, where specific VXLAN segments can be mapped to physical VLANs connecting physical workloads, or extended to other sites.
6) Divide and Conquer multi data center
Solving the multi data center challenge involves tackling a few very different problem areas related to networking. Rarely does one platform have all the tools to solve all of the different problems in the most elegant way. It’s usually best to divide and conquer each problem area with the best tool for the job. In moving an application from one data center to another, the networking challenges generally boil down to three problem areas:
- Recreate the application’s network topology and services
- Optimize Egress routing
- Optimize Ingress routing
In abstracting the virtual network, complete with Logical Layer 2 segments, distributed logical routing, distributed firewall, perimeter firewall, and load balancing, all entirely provisioned by API and software, VMware NSX is the ideal tool for quickly and faithfully recreating the applications network topology and services in another data center. At this point the NSX Edge provides the application a consolidated point of presence for optimized routing solutions to solve against.
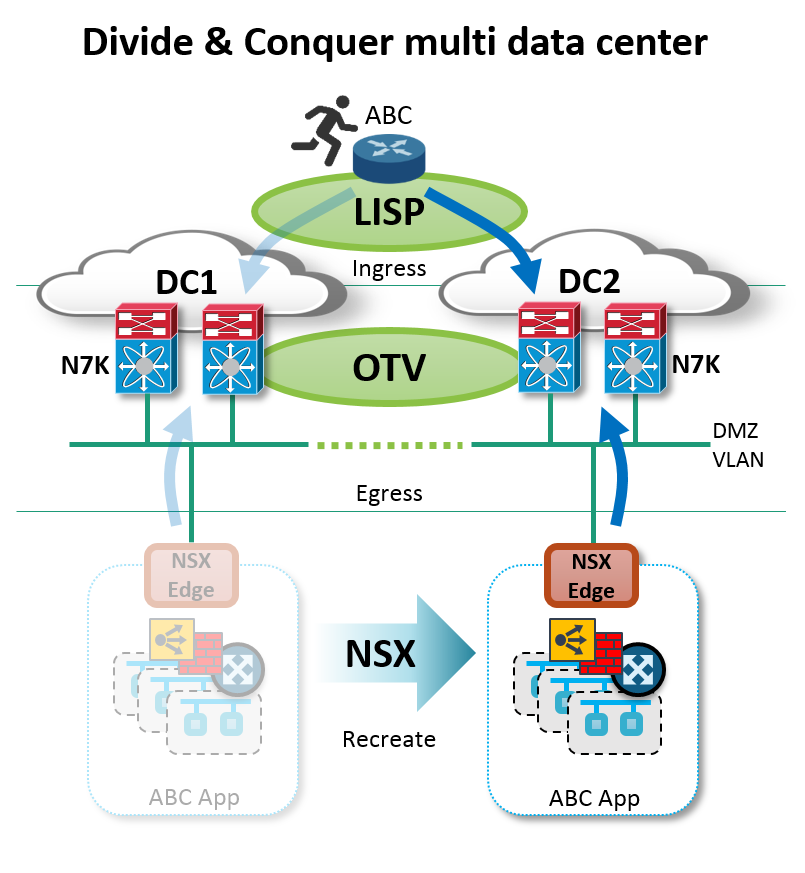
Figure: Multi data center with VMware NSX, Cisco OTV and LISP
The next problem area — optimized egress routing — is ideal for a tool like OTV on the Cisco Nexus 7000 series, where the virtual network’s NSX Edge is given a consistent egress gateway network at either data center, with localized egress forwarding. Cisco OTV services are focused on the DMZ VLAN and the NSX Edge, and not burdened with handling every individual network segment, every virtual machine, and every default gateway within the application. With this simplicity the OTV solution becomes more scalable to handle larger sets of applications, and easier to configure and deploy.
With the Cisco Nexus 7000 and OTV keying on the NSX Edge (via VIPs and IP routing) for the application’s point of presence, this serves as in ideal layering point for the next problem area of optimized ingress routing. This challenge is ideal for tools such as BGP routing, or LISP on the Cisco Nexus 7000 switches and LISP capable routers; delivering inbound client traffic immediately and directly to the data center hosting the application.
7) A superior track record of integration and operational tools
It’s hard to think of two technology leaders with a better track record of doing more operationally focused engineering work together than Cisco and VMware. Examples are both recent and plenty; such as the Cisco Nexus 1000V, Cisco UCS VM-FEX, Cisco UCS Plugin for VMware vCenter, the Cisco UCS Plugin for VMware vCenter Orchestrator, and so on.
Operational visibility is all about providing good data and making it easily accessible. A comprehensive API is the basis on which two industry leaders can engineer tools together exchanging data to provide superior operational visibility. Cisco UCS and VMware NSX are two platforms with a rich API engineered at its core (not a bolted on afterthought). When looking at both the track record and capabilities of VMware and Cisco, working together to serve their mutual customer better, we’re excited about what lies ahead.
In closing
VMware NSX represents best-in-class virtual networking, for any hypervisor, any application, any cloud platform, and any physical network. A well-engineered physical network is, and always will be, an important part of the infrastructure. Network virtualization makes it even better by simplifying the configuration, making it more scalable, enabling rapid deployment of networking services, and providing centralized operational visibility and monitoring into the state of the virtual and physical network.
The point of this post is not so much to help you decide what your data center infrastructure should be, but to show you how adding VMware NSX to Cisco UCS & Nexus will allow you to get much more out of those best-in-class platforms.
Brad Hedlund
Engineering Architect
VMware NSBU


Comments
0 Comments have been added so far